






 本文深入探讨Flink,一个批处理和流处理统一的计算框架。内容涵盖Flink的基本概念、特性,如流处理引擎、容错机制、与Hadoop的兼容性,以及Flink的架构、技术栈、DataStream、Transformation、并行数据流、窗口和checkpoint机制。此外,还解析了Flink在YARN上的运行流程。
本文深入探讨Flink,一个批处理和流处理统一的计算框架。内容涵盖Flink的基本概念、特性,如流处理引擎、容错机制、与Hadoop的兼容性,以及Flink的架构、技术栈、DataStream、Transformation、并行数据流、窗口和checkpoint机制。此外,还解析了Flink在YARN上的运行流程。
目录
一.flink概述
- 基本概念
- 特性
- 与hadoop兼容性
- 流式计算框架的性能对比
二.flink原理与技术架构
- flink架构
- flink技术栈
- flink核心概念 - DataStream
- DataStream Transformation
- flink原理
5.1 原理1
5.2 原理2 - flink并行数据流
- flink操作符链
- flink窗口
- checkpoint
9.1 机制
9.2 运行机制
9.3 对齐机制
三.flink运行流程
- flink 关键角色
- flink on yurn
一.flink概述
1.基本概念
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
2.特性
-
流处理引擎
-
容错,可靠性(HA):以checkpoint(快照)机制来保证容错性。
异步快照:
- 普通快照在快照的时候要将所有业务都停止,但在异步快照时只对需要快照的一部分停止,其他部分继续工作,使得业务不耽误
- 保证所有操作都只有一次
-
可扩展性:分布式,可增加节点。可以分配到不同的节点上运行。
-
性能:高吞吐,低延迟。
3.与hadoop兼容性
-
Flink能够支持Yarn,能够从HDFS和HBase中获取数据;
-
能够使用所有的Hadoop的格式化输入和输出;
-
能够使用Hadoop原有的Mappers和Reducers,并且能与Flink的操作混合使用;
-
能够更快的运行Hadoop的作业。
4.流式计算框架的性能对比

storm已经很快了,但flink更快,可以看到我们的计算框架是不断在进步的。
二.flink原理与技术架构
1.flink架构

-
Data storage:底层的数据存储
-
Single node execution/standalone or YARN cluster:部署方式
-
Embedded/Local/Remote Environment:不同的运行环境
-
Flink Local Runtime:运行线程
-
Flink Optimizer,Flink Stream Builder:优化器
-
Common API表示的是Flink平台的API
-
Scala API和Java API表示的是对外提供的API
2.flink技术栈
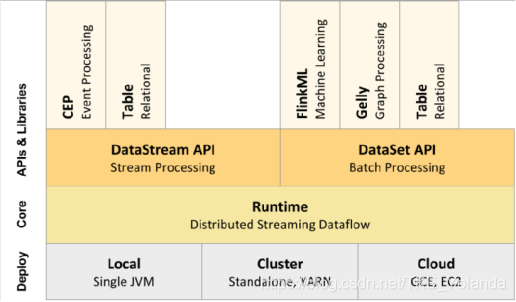
部署方式:
-
Cloud:云平台
-
Cluster:集群(standalone,YARN)
-
Local:本地
API:
- datasetAPI:对静态数据进行批处理操作
- datastreamAPI:对数据流进行流处理操作
3.flink核心概念 - DataStream
datastream是一个不可修改的集合,也是一张无边界表,可分布在多个节点上,是一个分布流。
- Data source:流数据源的接入,支持HDFS文件、kafka、文本数据等。
- Transformations:流数据转换。
- Data sink:数据输出,支持HDFS、kafka、文本等。
4.DataStream Transformation
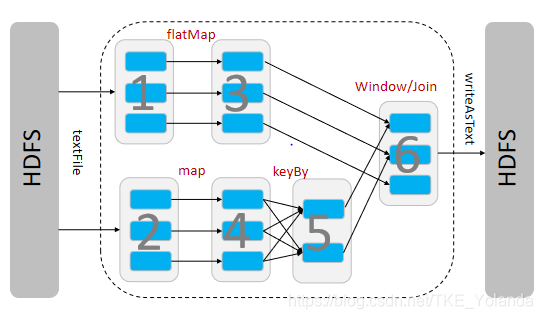
数据流转换流程与Spark类似:
- 从HDFS读取数据到DataStream中
- 进行相关算子操作,如flatMap,Map,keyBy
- 窗口操作或算子操作
- 最后处理结果sink到HDFS
5.flink原理
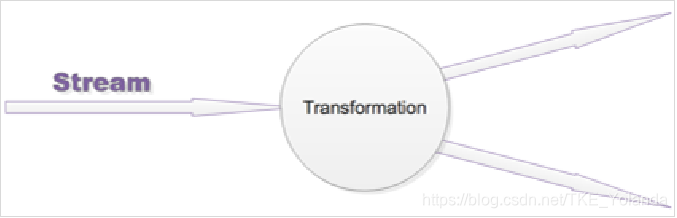
5.1 原理1
- 用户实现的Flink程序是由Stream数据和Transformation算子组成。
- Stream是一个中间结果数据,而Transformation是算子,它对一个或多个输入Stream进行计算处理,输出一个或多个结果Stream。
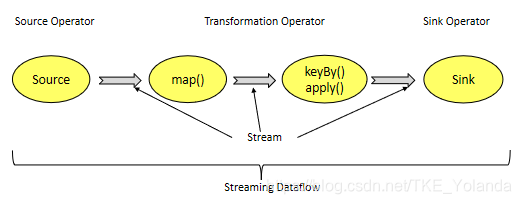
5.2 原理2
Source操作符载入数据,通过map()、keyBy()、apply()等Transformation 操作符处理stream。数据处理完成后,调用sink写入相关存储系统,如hdfs、hbase、kafka等。
6.flink并行数据流
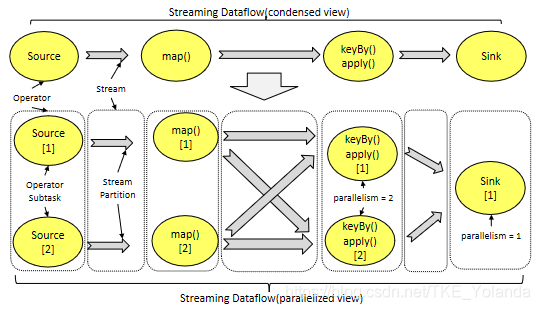
- 一个Stream可以被分成多个Stream分区(Stream Partitions),一个Operator可以被分成多个Operator Subtask,每一个Operator Subtask是在不同的线程中独立执行的。一个Operator的并行度,等于Operator Subtask的个数,一个Stream的并行度等于生成它的Operator的并行度。
- One-to-one模式
比如从Source[1]到map()[1],它保持了Source的分区特性(Partitioning)和分区内元素处理的有序性,也就是说map()[1]的Subtask看到数据流中记录的顺序,与Source[1]中看到的记录顺序是一致的。 - Redistribution模式
这种模式改变了输入数据流的分区,比如从map()[1]、map()[2]到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的Subtask向下游的多个不同的Subtask发送数据,改变了数据流的分区,这与实际应用所选择的Operator有关系。 Subtask的个数,一个Stream的并行度总是等于生成它的Operator的并行度。
7.flink操作符链
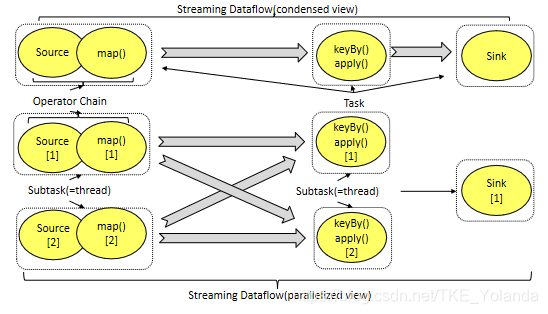
- Flink内部有一个优化的功能,根据上下游算子的紧密程度来进行优化。紧密度高的算子可以进行优化,优化后可以将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
- 上半部分表示的是将两个紧密度高的算子优化后串成一个Operator Chain,实际上一个Operator Chain就是一个大的Operator的概念。途中的Operator Chain表示一个Operator,keyBy表示一个Operator,Sink表示一个Operator,他们通过Stream连接,而每个Operator在运行时对应一个Task,也就是说图中的上半部分3个Operator对应的是3个Task。
- 下半部分是上半部分的一个并行版本,对每一个Task都并行华为多个Subtask,这里只是演示了2个并行度,sink算子是1个并行度。
8.flink窗口
- 基于分割标准:
- 时间窗口
- 数量窗口
- 基于行为标准:
- 滑动窗口:窗口之间有数据重叠
- 滚动窗口:窗口之间没有数据重叠
- 自定义窗口
会话窗口:经过一段设置时间无数据认为窗口完成。用不活跃的时间点把窗口进行分隔,窗口和窗口之间不重合
9.checkpoint
9.1 机制
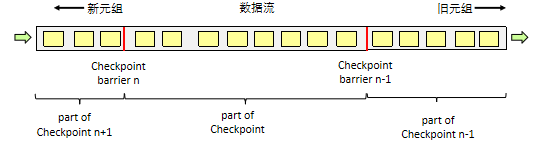
- Flink分布式快照机制的核心是barriers,这些barriers周期性插入到数据流中,并作为数据流的一部分随之流动。
- 存放位置:
- jobmanager
- HDFS
- Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。
- 该机制可以保证应用在运行过程中出现失败时,应用的所有状态能够从某一个检查点恢复,保证数据仅被处理一次(Exactly Once)。另外,也可以选择至少处理一次(at least once)。
9.2 运行机制
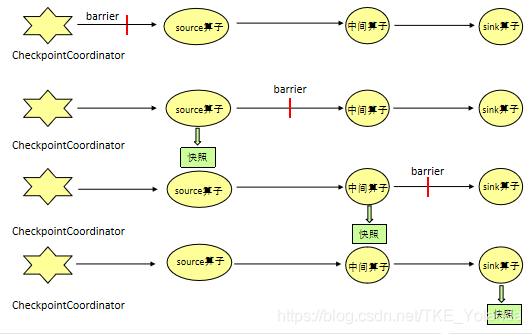
- CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier。
- 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
- 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
- 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功;否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
9.3 对齐机制
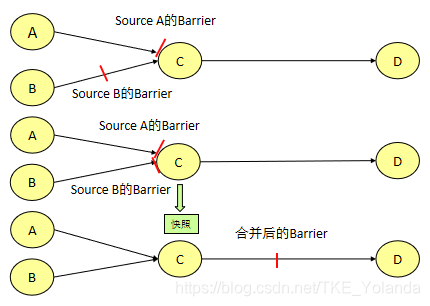
source不一定只有一个
source不一定同时接收到barrier
- 假设算子C有A和B两个输入源。
- 在第i个快照周期中,由于某些原因(如处理时延、网络时延等)输入源A发出的barrier先到来,这时算子C暂时将输入源A的输入通道阻塞,仅接收输入源B的数据。
- 当输入源B发出的barrier到来时,算子C制作自身快照并向CheckpointCoordinator报告自身的快照制作情况,然后将两个barrier合并为一个,向下游所有的算子广播。
三.flink运行流程
1.flink关键角色
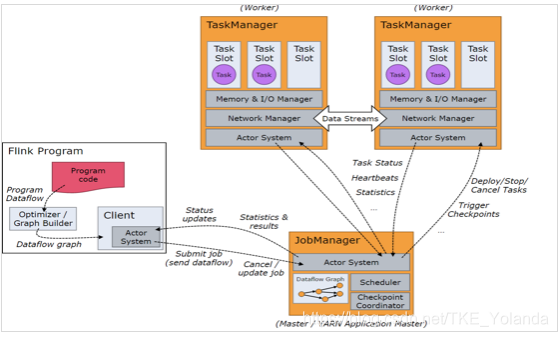
- Jobmanager:负责job的管理,资源的调度,任务的调度,checkpoint管理,故障恢复
- Actor system:作为jobmanager和taskmanager之间的通信机制
2.flink on yurn
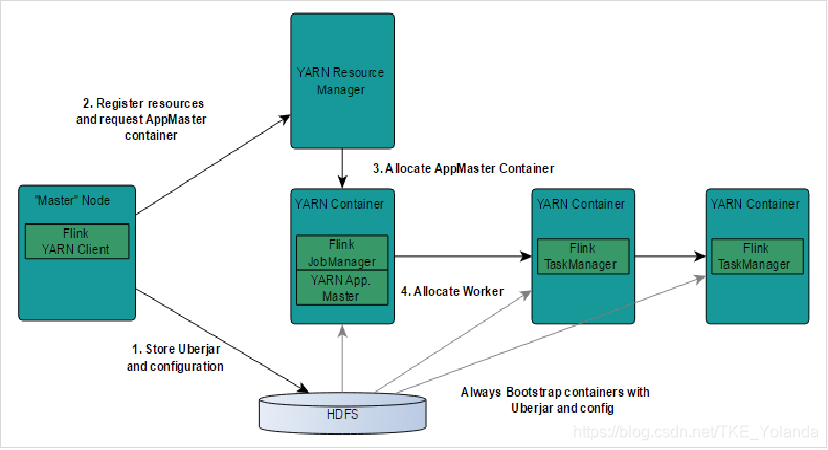
- Flink YARN Client首先会检验是否有足够的资源来启动YARN集群,如果资源足够的话,会将jar包、配置文件等上传到HDFS。
- Flink YARN Client首先与YARN Resource Manager进行通信,申请启动ApplicationMaster(以下简称AM)。在Flink YARN的集群中,AM与Flink JobManager在同一个Container中。
- AM在启动的过程中会和YARN的RM进行交互,向RM申请需要的Task ManagerContainer,申请到Task Manager Container后,在对应的NodeManager节点上启动TaskManager进程。
- AM与Fink JobManager在同一个container中,AM会将JobManager的RPC地址通过HDFS共享的方式通知各个TaskManager,TaskManager启动成功后,会向JobManager注册。
- 等所有TaskManager都向JobManager注册成功后,Flink基于YARN的集群启动成功,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。

















 5170
5170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









