







 本文探讨了RBF神经网络的工作原理,包括如何使用径向基函数进行非线性映射,以及K-means聚类在确定最优k值和选择径向基函数中心值和方差的应用。介绍了手肘法和轮廓系数法评估K-means聚类效果,以及自组织法和有监督学习在RBF网络参数优化中的角色。
本文探讨了RBF神经网络的工作原理,包括如何使用径向基函数进行非线性映射,以及K-means聚类在确定最优k值和选择径向基函数中心值和方差的应用。介绍了手肘法和轮廓系数法评估K-means聚类效果,以及自组织法和有监督学习在RBF网络参数优化中的角色。
目录
主体代码参照:
1、RBF网络相关知识
知识概述
RBF神经网络是一种3层的前向网络,其基本工作原理是:利用RBF构成的隐藏层空间对低维的输入矢量进行投影,将数据变换到高维空间中去,以使原来线性不可分的问题能够变得线性可分。下图为径向基神经网络的基本结构示意图
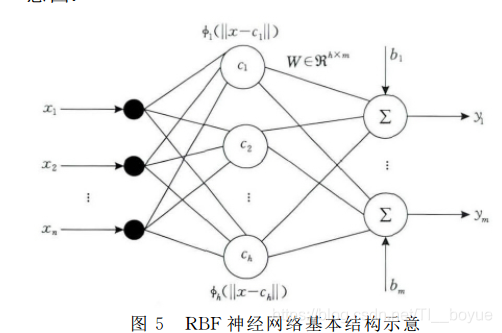
由于输入层在RBF网络中仅仅起到信号的传输作用,故而输入层和隐含层之间的连接权值都为1,隐含层实现对输入特征的非线性投影,而输出层则负责最后的线性加权求和
输出层负责通过线性优化策略来实现对权值的优化,学习速度通常较快;
隐含层则需要采用非线性优化的方法对激活函数的参数调整,故而其学习速度较慢
RBF网络中待学习优化的参数包括:基函数的中心和方差以及隐含层到输出层的连接权值
RBF网络的参数学习方法按照径向基函数中心的选取有不同的类型,主要包括自组织选取法、随机中心法、有监督中心法和正交最小二乘法等
2、K-means聚类最优k值的选取
2.1手肘法:SSE(sum of the squared errors,误差平方和)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
def test_Kmeans_nclusters(data_train):
#计算不同的k值时,SSE的大小变化
nums=range(2,10)
SSE = [] # 存放每次结果的误差平方和
for k in nums:
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(data_train)
SSE.append(estimator.inertia_)
X = range(2,10)
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(X,SSE,'o-')
plt.grid()
plt.show()
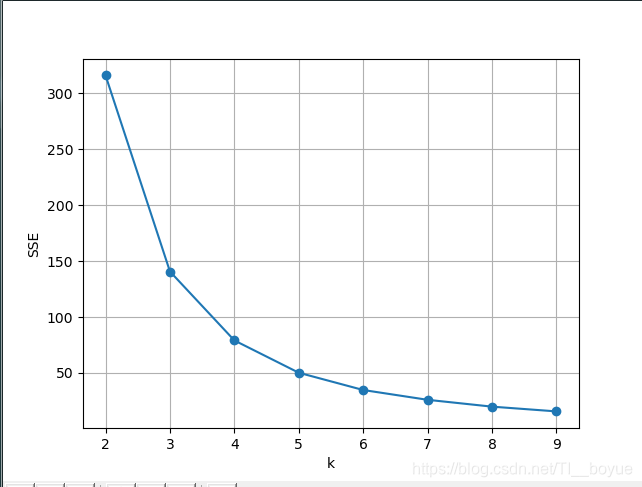
运行结果如下,根据SSE的变化趋势选取K值为4
2.2 轮廓系数法
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。
轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优
def Kmeans_SC_nclusters(data_train):
nums=range(2,10)
Scores = [] # 存放轮廓系数
for k in nums:
estimator = KMeans(n_clusters=k) # 构造聚类器
estimator.fit(data_train)
Scores.append(silhouette_score(data_train,estimator.labels_,metric='euclidean'))
X = range(2,10)
plt.xlabel('k')
plt.ylabel('SC')
plt.plot(X,Scores,'o-')
plt.show()
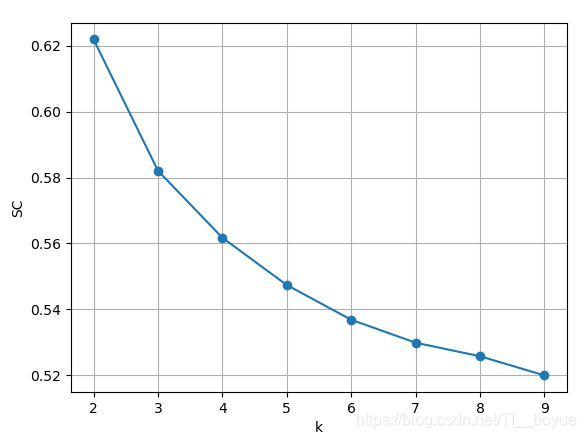
运行结果:
3、径向基函数的中心值和方差的选取
3.1 有无监督知识概述
无监督学习:输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化;
有监督学习:从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求包括输入输出,也可以说是特征和目标
参考:监督学习和无监督学习
3.2 自组织法(无监督)
以自组织法为例,其学习主要包括两个阶段:
第一阶段为无监督和自组织学习阶段,用以确定隐含层基函数的中心及方差;
第二阶段是有监督学习过程,可实现隐含层到输出层之间的连接权值的求解
kmeans聚类方法获取聚类中心和标准差
#使用 k-means 获取聚类中心、标准差
def getC_S(self,x,class_num):
#构造聚类器
#n_clusters: 即我们的k值; max_iter: 最大的迭代次数
estimator=KMeans(n_clusters=class_num,max_iter=10000)
estimator.fit(x) #聚类
# C 隐藏层函数中心
c=estimator.cluster_centers_
n=len(c)
Cmax=0;
for i in range(n):
j=i+1
while j<n:
t=np.sum((c[i]-c[j])**2)# 取正值
Cmax=max(s,t)
j=j+1
s=np.sqrt(Cmax)/np.sqrt(2*n)
print(c,type(c),'\n',s,type(s))
return c,s
采用Kmeans聚类方法获取高斯径向基函数的中心和方差,具体高斯函数形式参考:
高斯函数应用总结
高斯函数(Gaussian function)的详细分析
高斯径向基函数的中心点和方差的:

对Kmeans计算流程介绍可参照:Kmeans聚类过程形象解释;K均值聚类算法
小细节:
t=np.sum((c[i]-c[j])**2)# 平方取正值
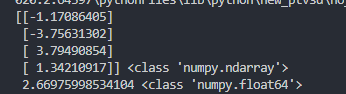
Kmeans 找到的中心值格式如下,形状为4*1,数据类型为numpy.ndarray,所以抽取元素直接相减的数据类型不是float类型,使用sum函数消除,计算的方差类型为numpy.float64。
根据高斯函数的形式构建高斯核函数
#高斯核函数(c为中心,s为标准差)
def kernel(self,x,c,s):
x1=tf.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=tf.reshape(x1,[-1,self.hidden_size,self.feature])
dist=tf.reduce_sum((x2-c)**2,2)
return tf.exp(-dist/(2*s**2))
相关函数解释:
tile()函数是用来对张量(Tensor)进行扩展的,其特点是对当前张量内的数据进行一定规则的复制。最终的输出张量维度不变
reshape()函数是数组对象中的方法,用于改变数组的形状
reduce_sum() 用于计算张量tensor沿着某一维度的和,可以在求和后降维
小细节验证:
import tensorflow as tf
import numpy as np
a=np.array([[1,2,3],[4,5,6]])
hidden =2
fature=3
a1=tf.tile(a,[1,hidden])
a2=tf.reshape(a1,[-1,hidden,fature])
b=np.array([[1,1,1],[1,1,1]])
c=a2-b
#print('a: '+str(np.shape(a)),'\ta1: '+str(np.shape(a1))+'\ta2: '+str(np.shape(a2))+'\tc: '+str(np.shape(c)))
# 不同维度累加,默认降维
Sum0=tf.reduce_sum(c,0)
Sum1=tf.reduce_sum(c,1)
Sum2=tf.reduce_sum(c,2)
with tf.Session() as sess:
print('a1:\n',sess.run(a1),'\na2:\n',sess.run(a2))
print(np.shape(a2))
print('c:\n',sess.run(c))
print('Sum0:\n',sess.run(Sum0))
print('Sum1:\n',sess.run(Sum1))
print('Sum2:\n',sess.run(Sum2))
运行结果:
a:
[[1 2 3]
[4 5 6]]
a1:
[[1 2 3 1 2 3]
[4 5 6 4 5 6]]
a2: shape=[2,2,3]
[[[1 2 3],[1 2 3]]
[[4 5 6],[4 5 6]]]
c=a2-b: #b=np.array([[1,1,1],[1,1,1]]) shape=[2,3]
[ [[0 1 2],[0 1 2]]
[[3 4 5],[3 4 5]] ]
# 从去掉最外层括号开始计算,0,1,2
Sum0:
[[3 5 7]
[3 5 7]]
Sum1:
[[ 0 2 4]
[ 6 8 10]]
Sum2:
[[ 3 3]
[12 12]]
3.3 有监督学习
class RBF_supervision():
#初始化学习率、学习步数
def __init__(self,learning_rate=0.002,step_num=10001,hidden_size=10):
self.learning_rate=learning_rate
self.step_num=step_num
self.hidden_size=hidden_size
#高斯核函数(c为中心,s为标准差)
def kernel(self,x,c,s): #训练时使用
x1=tf.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=tf.reshape(x1,[-1,self.hidden_size,self.feature])
dist=tf.reduce_sum((x2-c)**2,2)
return tf.exp(-dist/(2*s**2))
#训练RBF神经网络
def train(self,x,y):
self.feature=np.shape(x)[1] #输入值的特征数
x_=tf.placeholder(tf.float32,[None,self.feature]) #定义placeholder
y_=tf.placeholder(tf.float32,[None,1]) #定义placeholder
#定义径向基层
c=tf.Variable(tf.random_normal([self.hidden_size,self.feature]))
s=tf.Variable(tf.random_normal([self.hidden_size]))
z=self.kernel(x_,c,s)
#定义输出层
w=tf.Variable(tf.random_normal([self.hidden_size,1]))
b=tf.Variable(tf.zeros([1]))
yf=tf.matmul(z,w)+b
loss=tf.reduce_mean(tf.square(y_-yf))#二次代价函数
optimizer=tf.train.AdamOptimizer(self.learning_rate) #Adam优化器
train=optimizer.minimize(loss) #最小化代价函数
init=tf.global_variables_initializer() #变量初始化
with tf.Session() as sess:
sess.run(init)
for epoch in range(self.step_num):
sess.run(train,feed_dict={x_:x,y_:y})
if epoch>0 and epoch%500==0:
mse=sess.run(loss,feed_dict={x_:x,y_:y})
print(epoch,mse)
# self.c,self.s,self.w,self.b=sess.run([c,s,w,b],feed_dict={x_:x,y_:y})
self.c,self.s,self.w,self.b=sess.run([c,s,w,b])
def kernel2(self,x,c,s): #预测时使用
x1=np.tile(x,[1,self.hidden_size]) #将x水平复制 hidden次
x2=np.reshape(x1,[-1,self.hidden_size,self.feature])
dist=np.sum((x2-c)**2,2)
return np.exp(-dist/(2*s**2))
def predict(self,x):
z=self.kernel2(x,self.c,self.s)
pre=np.matmul(z,self.w)+self.b
return pre
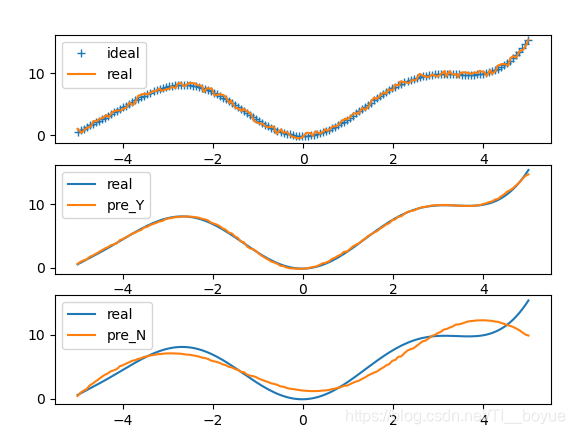
3.4 结果对比
传送门
RBF网络知识
RBF(径向基)神经网络
MLP、RBF、SVM网络比较及其应用前景
【机器学习】径向基(RBF)神经网络的tensorflow实现

【机器学习】RBF神经网络原理与Python实现
核函数
对核函数(kernel)最通俗易懂的理解
知乎-机器学习里的 kernel 是指什么?
核函数K
小函数
numpy.reshape()函数
直观的理解tensorflow中的tf.tile()函数
numpy函数:[1]shape用法
数据预处理中fit()
在keras中model.fit_generator()和model.fit()有什么区别
python使用matplotlib:subplot绘制多个子图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









