







大模型时代大家常用pytorch来编写代码,模型结构依然使用的Transformer网络结构,由于笔者之前已用Keras实现Transformer( Keras Transformer模型代码实现)。 现基于pytorch完成Transformer网络结构编写。
本文所有代码内容完全由笔者独立Coding,转载、引用请告知并笔者,同时附上本文出处;
本文将介绍如下内容:
- 检查依赖库版本、GPU 状态
- 一、下载、加载数据集
- 二、数据预处理
- 三、位置编码
- 四、Mask的构建
- 五、缩放点积注意力机制实现
- 六、多头注意力机制实现
- 七、FeedForward层次实现
- 八、定义EncoderLayer层
- 九、定义DecoderLayer层
- 十、EncoderModel的实现
- 十一、DecoderModel的实现
- 十二、Transformer的实现
- 十三、初始化参数,实例化Transformer
- 十四、自定义学习率和优化器
- 十五、自定义损失函数
- 十六、Mask的创建与使用
- 十七、定义训练模型
- 十八、checkpoints
- 十九、模型预测实现
- 二十、Attention可视化
- 二十一、TransFormer模型示例展示
- 二十二、总结代码
检查依赖库版本、GPU 状态,常量、超参数定义
import os
import sys
import time
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import sklearn
from pathlib import Path
from datasets import load_dataset
from tokenizers import ByteLevelBPETokenizer
from transformers import PreTrainedTokenizerFast
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
from torch.optim.lr_scheduler import _LRScheduler
from transformers import get_cosine_schedule_with_warmup
from datetime import datetime
# 数据文件地址
train_path = "/home/nijiahui/Datas/por_eng_csv/por_en_train.csv"
val_path = "/home/nijiahui/Datas/por_eng_csv/por_en_test.csv"
special_tokens = ["<s>", "<pad>", "</s>", "<unk>", "<mask>"]
checkpoint_dir = './checkpoints-tmp22'
src_lang = "pt"
tgt_lang = "en"
# 构建词表参数
vocab_size = 2**13 # 词表大小
min_freq = 2 # 最小词频
special_tokens=special_tokens # 特殊符号
max_length = 128 # 最大序列长度
# 模型训练超参数
batch_size = 32 # 批处理数
# warmup_steps = 4000 # warmup steps数
epochs = 60 # 训练轮数
# learning_rate = 1.0 # 学习率
# betas = (0.9, 0.98) # Adam 的一阶矩(梯度均值);二阶矩(梯度平方的均值)
# eps = 1e-9 # 防止除零错误的小常数
learning_rate = 5e-4
betas = (0.9, 0.98)
eps = 1e-8
weight_decay = 1e-6 # L2正则化((权重衰减)) - 0.01
# 模型结构
# num_layers = 8
# d_model = 512 # hidden-size
# dff = 2048
# num_heads = 8
# dropout_rate = 0.1
num_layers = 4
d_model = 128 # hidden-size
dff = 512
num_heads = 8
dropout_rate = 0.2
def check_env():
"""
检查 PyTorch 环境信息、GPU 状态,以及常用依赖库版本。
返回推荐的 device ('cuda' 或 'cpu')。
"""
print("===== PyTorch & 系统信息 =====")
print("torch.__version__:", torch.__version__)
print("python version:", sys.version_info)
print("\n===== 常用库版本 =====")
for module in (mpl, np, pd, torch):
print(module.__name__, module.__version__)
print("\n===== GPU 检查 =====")
print("torch.cuda.is_available():", torch.cuda.is_available())
print("torch.version.cuda:", torch.version.cuda)
try:
print("cudnn version:", torch.backends.cudnn.version())
except Exception as e:
print("cudnn version: N/A", e)
if torch.cuda.is_available():
print("GPU count:", torch.cuda.device_count())
print("Current device id:", torch.cuda.current_device())
print("GPU name:", torch.cuda.get_device_name(0))
print("bfloat16 supported:", torch.cuda.is_bf16_supported())
# 启用 TF32
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
try:
torch.set_float32_matmul_precision("high")
except Exception:
pass
device = "cuda"
else:
print("⚠️ 没检测到 CUDA,可强制 device='cpu' 运行,但速度会慢")
device = "cpu"
print("\n推荐使用 device: Cuda;")
return device
# ---------output-----------
# ===== PyTorch & 系统信息 =====
# torch.__version__: 2.5.1+cu121
# python version: sys.version_info(major=3, minor=12, micro=3, releaselevel='final', serial=0)
# ===== 常用库版本 =====
# matplotlib 3.10.3
# numpy 1.26.4
# pandas 2.2.3
# torch 2.5.1+cu121
# ===== GPU 检查 =====
# torch.cuda.is_available(): True
# torch.version.cuda: 12.1
# cudnn version: 90100
# GPU count: 1
# Current device id: 0
# GPU name: NVIDIA GeForce RTX 3090
# bfloat16 supported: True
# 推荐使用 device: Cuda;
# 实际使用设备: cuda
一、加载数据集
1. 下载数据集
有两种方案:
- 资源库中下载:ted_hrlr_translate.zip
- 基于笔者如下文章下载:下载葡萄牙语与英语翻译ted_hrlr_translate数据集
2. 加载、拆分数据集
def load_translation_dataset(
train_path: str,
val_path: str,
src_lang: str = "src",
tgt_lang: str = "tgt",
delimiter: str = "\t"
):
"""
通用机器翻译数据集加载函数
参数:
train_path: 训练集 CSV 文件路径
val_path: 验证集 CSV 文件路径
src_lang: 源语言列名 (例如 'de', 'fr', 'zh')
tgt_lang: 目标语言列名 (例如 'en', 'ja')
delimiter: 分隔符,默认制表符 '\t'
返回:
train_dataset, val_dataset
"""
print(f"开始加载 {src_lang} → {tgt_lang} 翻译数据...")
dataset = load_dataset(
"csv",
data_files={
"train": train_path,
"validation": val_path
},
column_names=[src_lang, tgt_lang],
delimiter=delimiter,
skiprows=1 # 跳过第一行
)
print("数据集类型:", type(dataset))
print(dataset)
# 打印一个样本
sample = dataset["train"][0]
print(f"示例数据 -> {src_lang}: {sample[src_lang]} | {tgt_lang}: {sample[tgt_lang]}")
return dataset["train"], dataset["validation"]
# 2. 加载葡萄牙语-英语翻译数据集
train_dataset, val_dataset = load_translation_dataset(
train_path=train_path,
val_path=val_path,
src_lang="pt", # 源语言
tgt_lang="en" # 目标语言
)
print("训练集样本数:", len(train_dataset))
print("验证集样本数:", len(val_dataset))
# ---------output-----------
# 开始加载 pt → en 翻译数据...
# Generating train split:
# 176958/0 [00:00<00:00, 506187.96 examples/s]
# Generating validation split:
# 19662/0 [00:00<00:00, 427124.82 examples/s]
# 数据集类型: <class 'datasets.dataset_dict.DatasetDict'>
# DatasetDict({
# train: Dataset({
# features: ['pt', 'en'],
# num_rows: 176958
# })
# validation: Dataset({
# features: ['pt', 'en'],
# num_rows: 19662
# })
# })
# 示例数据 -> pt: Eu dei um livro ao menino. | en: I gave the boy a book.
# 训练集样本数: 176958
# 验证集样本数: 19662
二、数据预处理
1. 定义、构建 Tokenizer
# 3.1 构建 Tokenizer
def train_and_load_tokenizers(
train_dataset,
src_lang="src",
tgt_lang='tgt',
vocab_size=2**13,
min_freq=2,
special_tokens=["<s>", "<pad>", "</s>", "<unk>", "<mask>"],
save_dir_src="tok_src",
save_dir_tgt="tok_tgt",
max_length=1024):
"""
训练并加载两种语言的 ByteLevel BPE Tokenizer
参数:
train_dataset: 数据集 (需包含 src_lang 和 tgt_lang 两列)
src_lang: 源语言字段名
tgt_lang: 目标语言字段名
vocab_size: 词表大小
min_freq: 最小词频
special_tokens: 特殊符号
save_dir_src: 葡语 tokenizer 保存路径
save_dir_tgt: 英语 tokenizer 保存路径
max_length: 模型最大序列长度
返回:
pt_tokenizer, en_tokenizer
"""
def iter_lang(ds, key):
for ex in ds:
txt = ex[key]
if isinstance(txt, bytes):
txt = txt.decode("utf-8")
yield txt
# 初始化 tokenizer
src_bbpe = ByteLevelBPETokenizer(add_prefix_space=True)
tgt_bbpe = ByteLevelBPETokenizer(add_prefix_space=True)
# 训练 tokenizer
src_bbpe.train_from_iterator(
iter_lang(train_dataset, src_lang),
vocab_size=vocab_size,
min_frequency=min_freq,
special_tokens=special_tokens,
)
tgt_bbpe.train_from_iterator(
iter_lang(train_dataset, tgt_lang),
vocab_size=vocab_size,
min_frequency=min_freq,
special_tokens=special_tokens,
)
# 保存 vocab/merges + tokenizer.json
Path(save_dir_src).mkdir(exist_ok=True)
Path(save_dir_tgt).mkdir(exist_ok=True)
src_bbpe.save_model(save_dir_src)
tgt_bbpe.save_model(save_dir_tgt)
src_bbpe._tokenizer.save(f"{save_dir_src}/tokenizer.json")
tgt_bbpe._tokenizer.save(f"{save_dir_tgt}/tokenizer.json")
# 用 PreTrainedTokenizerFast 加载
src_tokenizer = PreTrainedTokenizerFast(tokenizer_file=f"{save_dir_src}/tokenizer.json")
tgt_tokenizer = PreTrainedTokenizerFast(tokenizer_file=f"{save_dir_tgt}/tokenizer.json")
# 设置特殊符号
for tok in (src_tokenizer, tgt_tokenizer):
tok.pad_token = "<pad>"
tok.unk_token = "<unk>"
tok.bos_token = "<s>"
tok.eos_token = "</s>"
tok.mask_token = "<mask>"
tok.model_max_length = max_length
tok.padding_side = "right"
print("pt vocab size:", len(src_tokenizer))
print("en vocab size:", len(tgt_tokenizer))
return src_tokenizer, tgt_tokenizer
print("开始构建 Tokenizer...")
src_tokenizer, tgt_tokenizer = train_and_load_tokenizers(
train_dataset=train_dataset, # 数据集
src_lang=src_lang,
tgt_lang=tgt_lang,
vocab_size=vocab_size, # 词表大小
min_freq=min_freq, # 最小词频
special_tokens=special_tokens, # 特殊符号
save_dir_src=f"tok_{src_lang}", # 保存目录
save_dir_tgt=f"tok_{tgt_lang}", # 保存目录
max_length=max_length # 最大序列长度
)
# ---------output-----------
# 开始构建 Tokenizer...
# pt vocab size: 8192
# en vocab size: 8192
2. 测试 Tokenizer 的 Encoder、Decoder
def test_tokenizers(
src_tokenizer,
tgt_tokenizer,
dataset,
src_lang: str = "src",
tgt_lang: str = "tgt",
num_samples: int = 1
):
"""
通用双语 tokenizer 测试函数(顺序打印前 num_samples 条样本)。
参数:
src_tokenizer: 源语言 tokenizer
tgt_tokenizer: 目标语言 tokenizer
dataset: 包含源语言和目标语言字段的数据集
src_lang: 源语言列名 (如 'de', 'fr', 'zh')
tgt_lang: 目标语言列名 (如 'en', 'ja', 'es')
num_samples: 要打印的样本数量(默认 1)
"""
if dataset is None or len(dataset) == 0:
raise ValueError("❌ dataset 为空,无法取样。")
end_index = min(num_samples, len(dataset))
print(f"🔹 从第 0 条开始,顺序打印前 {end_index} 条样本(共 {len(dataset)} 条)\n")
for i in range(end_index):
sample = dataset[i]
src_sample = sample[src_lang]
tgt_sample = sample[tgt_lang]
print(f"\n===== 样本 {i} ({src_lang} → {tgt_lang}) =====")
print(f"{src_lang}: {src_sample}")
print(f"{tgt_lang}: {tgt_sample}")
print("-" * 60)
# === 源语言 Tokenizer 测试 ===
print(f"\n=== {src_lang.upper()} Tokenizer Test ===")
src_ids = src_tokenizer.encode(src_sample, add_special_tokens=False)
print(f"[{src_lang.upper()}] Tokenized IDs: {src_ids}")
src_decoded = src_tokenizer.decode(
src_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(f"[{src_lang.upper()}] Decoded string: {src_decoded}")
assert src_decoded == src_sample, f"{src_lang.upper()} decode != original input!"
print(f"[{src_lang.upper()}] id --> decoded([id]) | id --> token(str)")
for tid in src_ids:
single_decoded = src_tokenizer.decode([tid], skip_special_tokens=True)
token_str = src_tokenizer.convert_ids_to_tokens(tid)
print(f"{tid:>6} --> {single_decoded!r} | {tid:>6} --> {token_str!r}")
print("\n" + "-" * 60 + "\n")
# === 目标语言 Tokenizer 测试 ===
print(f"=== {tgt_lang.upper()} Tokenizer Test ===")
tgt_ids = tgt_tokenizer.encode(tgt_sample, add_special_tokens=False)
print(f"[{tgt_lang.upper()}] Tokenized IDs: {tgt_ids}")
tgt_decoded = tgt_tokenizer.decode(
tgt_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(f"[{tgt_lang.upper()}] Decoded string: {tgt_decoded}")
assert tgt_decoded == tgt_sample, f"{tgt_lang.upper()} decode != original input!"
print(f"[{tgt_lang.upper()}] id --> decoded([id]) | id --> token(str)")
for tid in tgt_ids:
single_decoded = tgt_tokenizer.decode([tid], skip_special_tokens=True)
token_str = tgt_tokenizer.convert_ids_to_tokens(tid)
print(f"{tid:>6} --> {single_decoded!r} | {tid:>6} --> {token_str!r}")
print("\n" + "=" * 80 + "\n")
test_tokenizers(
src_tokenizer=src_tokenizer,
tgt_tokenizer=tgt_tokenizer,
dataset=train_dataset,
src_lang=src_lang,
tgt_lang=tgt_lang,
num_samples=1
)
# ---------output-----------
# 🔹 从第 0 条开始,顺序打印前 1 条样本(共 176958 条)
# ===== 样本 0 (pt → en) =====
# pt: Eu dei um livro ao menino.
# en: I gave the boy a book.
# ------------------------------------------------------------
# === PT Tokenizer Test ===
# [PT] Tokenized IDs: [4169, 630, 310, 724, 523, 1894, 18]
# [PT] Decoded string: Eu dei um livro ao menino.
# [PT] id --> decoded([id]) | id --> token(str)
# 4169 --> 'Eu' | 4169 --> 'Eu'
# 630 --> ' dei' | 630 --> 'Ġdei'
# 310 --> ' um' | 310 --> 'Ġum'
# 724 --> ' livro' | 724 --> 'Ġlivro'
# 523 --> ' ao' | 523 --> 'Ġao'
# 1894 --> ' menino' | 1894 --> 'Ġmenino'
# 18 --> '.' | 18 --> '.'
# ------------------------------------------------------------
# === EN Tokenizer Test ===
# [EN] Tokenized IDs: [45, 1004, 285, 950, 264, 593, 18]
# [EN] Decoded string: I gave the boy a book.
# [EN] id --> decoded([id]) | id --> token(str)
# 45 --> 'I' | 45 --> 'I'
# 1004 --> ' gave' | 1004 --> 'Ġgave'
# 285 --> ' the' | 285 --> 'Ġthe'
# 950 --> ' boy' | 950 --> 'Ġboy'
# 264 --> ' a' | 264 --> 'Ġa'
# 593 --> ' book' | 593 --> 'Ġbook'
# 18 --> '.' | 18 --> '.'
# ================================================================================
3. 构建 batch data loader
def build_dataloaders(
train_dataset,
val_dataset,
src_tokenizer,
tgt_tokenizer,
src_lang: str = "src",
tgt_lang: str = "tgt",
batch_size: int = 64,
max_length: int = 48,
num_workers: int = 0,
shuffle_train: bool = True,
):
"""
通用双语翻译任务的 DataLoader 构建函数
参数:
train_dataset: HuggingFace Dataset (训练集)
val_dataset: HuggingFace Dataset (验证集)
src_tokenizer: 源语言 tokenizer
tgt_tokenizer: 目标语言 tokenizer
src_lang: 源语言字段名(如 'de', 'fr', 'zh')
tgt_lang: 目标语言字段名(如 'en', 'ja', 'es')
batch_size: 批大小
max_length: 样本最大长度(超过则过滤)
num_workers: DataLoader worker 数量
shuffle_train: 是否打乱训练集
返回:
train_loader, val_loader
"""
# === 1) 工具函数:编码并添加 BOS/EOS ===
def encode_with_bos_eos(tokenizer, text: str):
ids = tokenizer.encode(text, add_special_tokens=False)
bos_id = tokenizer.bos_token_id
eos_id = tokenizer.eos_token_id
if bos_id is None or eos_id is None:
raise ValueError("❌ tokenizer 未设置 bos_token/eos_token")
return [bos_id] + ids + [eos_id]
# === 2) 构造过滤后的样本对 ===
def build_filtered_pairs(hf_split, src_tok, tgt_tok, max_len: int):
pairs, kept, skipped = [], 0, 0
for ex in hf_split:
src_ids = encode_with_bos_eos(src_tok, ex[src_lang])
tgt_ids = encode_with_bos_eos(tgt_tok, ex[tgt_lang])
if len(src_ids) <= max_len and len(tgt_ids) <= max_len:
pairs.append((src_ids, tgt_ids))
kept += 1
else:
skipped += 1
print(f"[filter] kept={kept}, skipped={skipped}, max_length={max_len}")
return pairs
train_pairs = build_filtered_pairs(train_dataset, src_tokenizer, tgt_tokenizer, max_length)
val_pairs = build_filtered_pairs(val_dataset, src_tokenizer, tgt_tokenizer, max_length)
# === 3) Dataset 类 ===
class TranslationPairsDataset(Dataset):
def __init__(self, pairs):
self.pairs = pairs
def __len__(self):
return len(self.pairs)
def __getitem__(self, idx):
src_ids, tgt_ids = self.pairs[idx]
return {
f"{src_lang}_input_ids": src_ids,
f"{tgt_lang}_input_ids": tgt_ids
}
# === 4) Collate 函数(动态 padding)===
def collate_padded(batch, pad_id_src: int, pad_id_tgt: int):
def pad_block(seqs, pad_value):
max_len = max(len(s) for s in seqs)
out = torch.full((len(seqs), max_len), pad_value, dtype=torch.long)
attn = torch.zeros((len(seqs), max_len), dtype=torch.long)
for i, s in enumerate(seqs):
L = len(s)
out[i, :L] = torch.tensor(s, dtype=torch.long)
attn[i, :L] = 1
return out, attn
src_ids_list = [ex[f"{src_lang}_input_ids"] for ex in batch]
tgt_ids_list = [ex[f"{tgt_lang}_input_ids"] for ex in batch]
src_input_ids, src_attention_mask = pad_block(src_ids_list, pad_id_src)
tgt_input_ids, tgt_attention_mask = pad_block(tgt_ids_list, pad_id_tgt)
return {
f"{src_lang}_input_ids": src_input_ids,
f"{src_lang}_attention_mask": src_attention_mask,
f"{tgt_lang}_input_ids": tgt_input_ids,
f"{tgt_lang}_attention_mask": tgt_attention_mask,
}
# === 5) DataLoader 构建 ===
train_loader = DataLoader(
TranslationPairsDataset(train_pairs),
batch_size=batch_size,
shuffle=shuffle_train,
collate_fn=lambda b: collate_padded(b, src_tokenizer.pad_token_id, tgt_tokenizer.pad_token_id),
num_workers=num_workers,
)
val_loader = DataLoader(
TranslationPairsDataset(val_pairs),
batch_size=batch_size,
shuffle=False,
collate_fn=lambda b: collate_padded(b, src_tokenizer.pad_token_id, tgt_tokenizer.pad_token_id),
num_workers=num_workers,
)
print(f"✅ DataLoader 构建完成:train={len(train_pairs)},val={len(val_pairs)}")
return train_loader, val_loader
print("开始构建 batch data loader...")
train_loader, val_loader = build_dataloaders(
train_dataset=train_dataset,
val_dataset=val_dataset,
src_tokenizer=src_tokenizer, # 源语言分词器
tgt_tokenizer=tgt_tokenizer, # 目标语言分词器
src_lang=src_lang, # 源语言字段名
tgt_lang=tgt_lang, # 目标语言字段名
batch_size=64,
max_length=48,
num_workers=0,
shuffle_train=True
)
# ---------output-----------
# 开始构建 batch data loader...
# [filter] kept=176952, skipped=6, max_length=48
# [filter] kept=19662, skipped=0, max_length=48
# ✅ DataLoader 构建完成:train=176952,val=19662
4. 查看预处理后的batch数据
# 3.4 【测试】 batch data loader
def test_dataloaders(
train_loader,
val_loader,
src_lang: str = "src",
tgt_lang: str = "tgt",
show_val: bool = True
):
"""
通用 DataLoader 检查函数,打印 batch 形状并展示一个样本。
参数:
train_loader: 训练 DataLoader
val_loader: 验证 DataLoader
src_lang: 源语言字段名 (如 'de', 'fr', 'zh')
tgt_lang: 目标语言字段名 (如 'en', 'ja', 'es')
show_val: 是否展示验证集样本(默认 True)
"""
# === 1. 查看一个训练 batch 的形状 ===
batch = next(iter(train_loader))
print("=== Train Loader Batch Shapes ===")
for k, v in batch.items():
print(f"{k:25s} {tuple(v.shape)}")
# === 2. 查看验证集的一个样本 ===
if show_val:
print("\n=== Validation Loader Example ===")
for i in val_loader:
print(f"{src_lang}_input_ids: ", i[f"{src_lang}_input_ids"][0])
print(f"{src_lang}_attention_mask: ", i[f"{src_lang}_attention_mask"][0])
print(f"{tgt_lang}_input_ids: ", i[f"{tgt_lang}_input_ids"][0])
print(f"{tgt_lang}_attention_mask: ", i[f"{tgt_lang}_attention_mask"][0])
break
test_dataloaders(
train_loader,
val_loader,
src_lang=src_lang,
tgt_lang=tgt_lang
)
# ---------output-----------
# === Train Loader Batch Shapes ===
# pt_input_ids (64, 17)
# pt_attention_mask (64, 17)
# en_input_ids (64, 15)
# en_attention_mask (64, 15)
# === Validation Loader Example ===
# pt_input_ids: tensor([ 0, 51, 278, 335, 1550, 370, 1411, 2321, 18, 2, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
# pt_attention_mask: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# en_input_ids: tensor([ 0, 6866, 299, 1036, 358, 264, 2342, 2165, 18, 2, 1, 1,
# 1, 1, 1, 1, 1, 1])
# en_attention_mask: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0])
三、位置编码
1. position对应embedding矩阵的计算公式:位置编码(Positional Encoding)
在 Transformer 模型中,位置编码 P E ( p o s , i ) PE(pos,i) PE(pos,i)的定义如下:
偶数维度( 2 i 2_i 2i):
PE ( p o s , 2 i ) = sin ( p o s 1000 0 2 i d model ) \text{PE}(pos, 2i) = \sin \left( \frac{pos}{10000^{\tfrac{2i}{d_{\text{model}}}}} \right) PE(pos,2i)=sin(10000dmodel2ipos)
奇数维度( 2 i 2_i 2i+1):
PE ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i d model ) \text{PE}(pos, 2i+1) = \cos \left( \frac{pos}{10000^{\tfrac{2i}{d_{\text{model}}}}} \right) PE(pos,2i+1)=cos(10000dmodel2ipos)
其中:
- p o s pos pos:表示序列中的位置(0, 1, 2, …);
- i i i:表示 embedding 向量的维度下标;
- d m o d e l d_{model} dmodel:表示 embedding 的维度大小。
总结
- 偶数维度 使用正弦函数:
sin - 奇数维度 使用余弦函数:
cos
这样的位置编码设计能够为模型提供序列的相对和绝对位置信息。
2. 位置编码 - 生成 position embedding
def get_position_embedding(sentence_length: int, d_model: int, device="cuda", dtype=torch.float32):
"""
返回 position 对应的 embedding 矩阵
形状: [1, sentence_length, d_model]
"""
def get_angles(pos: torch.Tensor, i: torch.Tensor, d_model: int):
"""
获取单词 pos 对应 embedding 的角度
pos: [sentence_length, 1]
i : [1, d_model]
return: [sentence_length, d_model]
"""
angle_rates = 1.0 / torch.pow(
10000,
(2 * torch.div(i, 2, rounding_mode='floor')).float() / d_model
)
return pos.float() * angle_rates
if device is None:
device = torch.device("cpu")
pos = torch.arange(sentence_length, device=device).unsqueeze(1) # [L, 1]
i = torch.arange(d_model, device=device).unsqueeze(0) # [1, D]
angle_rads = get_angles(pos, i, d_model) # [L, D]
# 偶数下标:sin
sines = torch.sin(angle_rads[:, 0::2])
# 奇数下标:cos
cosines = torch.cos(angle_rads[:, 1::2])
# 拼接还原成 [L, D]
position_embedding = torch.zeros((sentence_length, d_model), device=device, dtype=dtype)
position_embedding[:, 0::2] = sines
position_embedding[:, 1::2] = cosines
# 增加 batch 维度 [1, L, D]
position_embedding = position_embedding.unsqueeze(0)
return position_embedding
position_embedding = get_position_embedding(max_length, d_model)
print(position_embedding.shape)
print(position_embedding)
# ---------output-----------
# torch.Size([1, 128, 128])
# tensor([[[ 0.0000e+00, 1.0000e+00, 0.0000e+00, ..., 1.0000e+00,
# 0.0000e+00, 1.0000e+00],
# [ 8.4147e-01, 5.4030e-01, 7.6172e-01, ..., 1.0000e+00,
# 1.1548e-04, 1.0000e+00],
# [ 9.0930e-01, -4.1615e-01, 9.8705e-01, ..., 1.0000e+00,
# 2.3096e-04, 1.0000e+00],
# ...,
# [-6.1604e-01, 7.8771e-01, 9.9030e-01, ..., 9.9986e-01,
# 1.4434e-02, 9.9990e-01],
# [ 3.2999e-01, 9.4398e-01, 7.4746e-01, ..., 9.9986e-01,
# 1.4550e-02, 9.9989e-01],
# [ 9.7263e-01, 2.3236e-01, -2.1726e-02, ..., 9.9986e-01,
# 1.4665e-02, 9.9989e-01]]], device='cuda:0')
3. 打印矩阵图形
def plot_position_embedding(position_embedding: torch.Tensor):
"""
可视化位置编码矩阵
参数:
position_embedding: [1, L, D] 的张量
"""
# 转到 CPU,并转成 numpy
pe = position_embedding.detach().cpu().numpy()[0] # [L, D]
plt.figure(figsize=(10, 6))
plt.pcolormesh(pe, cmap='RdBu') # L × D 矩阵
plt.xlabel("Depth (d_model)")
plt.xlim((0, pe.shape[1]))
plt.ylabel("Position (pos)")
plt.colorbar()
plt.title("Positional Encoding Visualization")
plt.show()
plot_position_embedding(position_embedding)

四、Mask的构建
1. padding mask
import torch
# batch_data.shape: [batch_size, seq_len]
def create_padding_mask(batch_data: torch.Tensor, pad_token_id: int = 0):
"""
输入:
batch_data: [batch_size, seq_len],填充位置用 pad_token_id 表示
pad_token_id: 默认是 0
输出:
padding_mask: [batch_size, 1, 1, seq_len]
"""
# 等价于 tf.math.equal(batch_data, 0)
mask = (batch_data == pad_token_id).float()
# 插入维度
return mask[:, None, None, :] # [B, 1, 1, L]
# 测试
x = torch.tensor([
[7, 6, 0, 0, 1],
[1, 2, 3, 0, 0],
[0, 0, 0, 4, 5]
])
mask = create_padding_mask(x, pad_token_id=0)
print(mask.shape) # torch.Size([3, 1, 1, 5])
print(mask)
# ---------output-----------
# torch.Size([3, 1, 1, 5])
# tensor([[[[0., 0., 1., 1., 0.]]],
# [[[0., 0., 0., 1., 1.]]],
# [[[1., 1., 1., 0., 0.]]]])
2. decoder 中的 look ahead
def create_look_ahead_mask(size: int):
"""
生成 Look-ahead mask (上三角矩阵)
参数:
size: 序列长度 (seq_len)
返回:
mask: [seq_len, seq_len],上三角为 1,其他为 0
"""
# ones: [size, size]
ones = torch.ones((size, size))
# 取上三角(不含对角线)=1,下三角和对角线=0
mask = torch.triu(ones, diagonal=1)
return mask
# 测试
mask = create_look_ahead_mask(3)
print(mask)
# ---------output-----------
# tensor([[0., 1., 1.],
# [0., 0., 1.],
# [0., 0., 0.]])
五、缩放点积注意力机制实现
1. 定义缩放点积注意力机制函数
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(q, k, v, mask=None):
"""
Args:
q: (..., seq_len_q, depth)
k: (..., seq_len_k, depth)
v: (..., seq_len_v, depth_v) (seq_len_k == seq_len_v)
mask: (..., seq_len_q, seq_len_k),
mask里1表示要忽略的位置,0表示保留。
Returns:
output: (..., seq_len_q, depth_v) 加权和
attention_weights: (..., seq_len_q, seq_len_k) 注意力权重
"""
# (..., seq_len_q, seq_len_k)
matmul_qk = torch.matmul(q, k.transpose(-2, -1))
# 缩放
dk = q.size()[-1]
scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32, device=q.device))
# 加上 mask
if mask is not None:
# 在 mask==1 的位置加上 -1e9,使 softmax 后趋近于0
scaled_attention_logits = scaled_attention_logits.masked_fill(mask == 1, -1e9)
# softmax 得到注意力权重
attention_weights = F.softmax(scaled_attention_logits, dim=-1)
# 加权求和
output = torch.matmul(attention_weights, v)
return output, attention_weights
2. 调用缩放点积注意力,返回权重和输出
def print_scaled_dot_product_attention(q, k, v):
"""
打印缩放点积注意力的权重和输出
Args:
q, k, v: 张量 (..., seq_len, depth)
"""
temp_out, temp_att = scaled_dot_product_attention(q, k, v, mask=None)
print("Attention weights are:")
print(temp_att)
print("Output is:")
print(temp_out)
3. 测试
import torch
import numpy as np
# 使用前面实现的 scaled_dot_product_attention 和 print_scaled_dot_product_attention
# 定义 k, v
temp_k = torch.tensor([[10, 0, 0],
[0, 10, 0],
[0, 0, 10],
[0, 0, 10]], dtype=torch.float32) # (4, 3)
temp_v = torch.tensor([[1, 0],
[10, 0],
[100, 5],
[1000, 6]], dtype=torch.float32) # (4, 2)
# 设置 numpy 打印格式
np.set_printoptions(suppress=True)
# q1
temp_q1 = torch.tensor([[0, 10, 0]], dtype=torch.float32) # (1, 3)
print("Query 1")
print_scaled_dot_product_attention(temp_q1, temp_k, temp_v)
# q2
temp_q2 = torch.tensor([[0, 0, 10]], dtype=torch.float32) # (1, 3)
print("\nQuery 2")
print_scaled_dot_product_attention(temp_q2, temp_k, temp_v)
# q3
temp_q3 = torch.tensor([[10, 10, 0]], dtype=torch.float32) # (1, 3)
print("\nQuery 3")
print_scaled_dot_product_attention(temp_q3, temp_k, temp_v)
# q4
temp_q4 = torch.tensor([[0, 10, 0],
[0, 0, 10],
[10, 10, 0]], dtype=torch.float32) # (3, 3)
print("\nQuery 4")
print_scaled_dot_product_attention(temp_q4, temp_k, temp_v)
# ---------output-----------
# Query 1
# Attention weights are:
# tensor([[8.4333e-26, 1.0000e+00, 8.4333e-26, 8.4333e-26]])
# Output is:
# tensor([[1.0000e+01, 9.2766e-25]])
# Query 2
# Attention weights are:
# tensor([[4.2166e-26, 4.2166e-26, 5.0000e-01, 5.0000e-01]])
# Output is:
# tensor([[550.0000, 5.5000]])
# Query 3
# Attention weights are:
# tensor([[5.0000e-01, 5.0000e-01, 4.2166e-26, 4.2166e-26]])
# Output is:
# tensor([[5.5000e+00, 4.6383e-25]])
# Query 4
# Attention weights are:
# tensor([[8.4333e-26, 1.0000e+00, 8.4333e-26, 8.4333e-26],
# [4.2166e-26, 4.2166e-26, 5.0000e-01, 5.0000e-01],
# [5.0000e-01, 5.0000e-01, 4.2166e-26, 4.2166e-26]])
# Output is:
# tensor([[1.0000e+01, 9.2766e-25],
# [5.5000e+02, 5.5000e+00],
# [5.5000e+00, 4.6383e-25]])
六、多头注意力机制实现
1. 定义多头注意力函数
from torch import nn
class MultiHeadAttention(nn.Module):
"""
PyTorch 版 MHA,与 Keras 版本对应:
q -> WQ -> 分头
k -> WK -> 分头
v -> WV -> 分头
计算 scaled dot-product attention
合并 -> 线性层
期望输入形状:
q, k, v: [B, L, d_model]
"""
def __init__(self, d_model: int, num_heads: int):
super().__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.depth = d_model // num_heads # 每个头的维度 Dh
# 对应 Keras 的 Dense(d_model)
self.WQ = nn.Linear(d_model, d_model, bias=True)
self.WK = nn.Linear(d_model, d_model, bias=True)
self.WV = nn.Linear(d_model, d_model, bias=True)
self.out_proj = nn.Linear(d_model, d_model, bias=True)
def _split_heads(self, x: torch.Tensor):
"""
x: [B, L, d_model] -> [B, num_heads, L, depth]
"""
B, L, _ = x.shape
x = x.view(B, L, self.num_heads, self.depth) # [B, L, H, Dh]
x = x.permute(0, 2, 1, 3).contiguous() # [B, H, L, Dh]
return x
def _combine_heads(self, x: torch.Tensor):
"""
x: [B, num_heads, L, depth] -> [B, L, d_model]
"""
B, H, L, Dh = x.shape
x = x.permute(0, 2, 1, 3).contiguous() # [B, L, H, Dh]
x = x.view(B, L, H * Dh) # [B, L, d_model]
return x
def forward(self, q, k, v, mask=None, return_attn: bool = True):
"""
q, k, v: [B, Lq/Lk/Lv, d_model]
mask: 期望形状为 [B, 1, Lq, Lk] 或 [B, Lq, Lk];值为1表示屏蔽,0表示保留
return:
output: [B, Lq, d_model]
attention_weights (可选): [B, num_heads, Lq, Lk]
"""
B = q.size(0)
# 线性映射
q = self.WQ(q) # [B, Lq, d_model]
k = self.WK(k) # [B, Lk, d_model]
v = self.WV(v) # [B, Lv, d_model]
# 分头
q = self._split_heads(q) # [B, H, Lq, Dh]
k = self._split_heads(k) # [B, H, Lk, Dh]
v = self._split_heads(v) # [B, H, Lv, Dh]
# 处理 mask:广播到 [B, H, Lq, Lk]
if mask is not None:
# 允许 [B, 1, Lq, Lk] 或 [B, Lq, Lk]
if mask.dim() == 3:
mask = mask.unsqueeze(1) # [B,1,Lq,Lk]
elif mask.dim() == 4 and mask.size(1) == 1:
pass # 已是 [B,1,Lq,Lk]
else:
raise ValueError("mask 形状需为 [B, Lq, Lk] 或 [B, 1, Lq, Lk]")
mask = mask.expand(B, self.num_heads, mask.size(-2), mask.size(-1))
# 注意力
attn_out, attn_weights = scaled_dot_product_attention(q, k, v, mask) # [B,H,Lq,Dh], [B,H,Lq,Lk]
# 合并头
attn_out = self._combine_heads(attn_out) # [B, Lq, d_model]
# 输出线性层
output = self.out_proj(attn_out) # [B, Lq, d_model]
if return_attn:
return output, attn_weights
return output
2. 测试
# 初始化 MultiHeadAttention
temp_mha = MultiHeadAttention(d_model=512, num_heads=8)
# 输入要匹配 d_model=512
y = torch.rand(1, 60, 512) # (batch_size=1, seq_len=60, dim=512)
# 前向计算
output, attn = temp_mha(y, y, y, mask=None)
print("output.shape:", output.shape) # (1, 60, 512)
print("attn.shape:", attn.shape) # (1, 8, 60, 60)
# ---------output-----------
# output.shape: torch.Size([1, 60, 512])
# attn.shape: torch.Size([1, 8, 60, 60])
七、FeedForward层次实现
1. 定义FeedForward函数
import torch.nn as nn
def feed_forward_network(d_model, dff):
"""
前馈网络 FFN
Args:
d_model: 输出维度 (embedding 维度)
dff: 内部隐层维度 (feed-forward 网络的中间层大小)
Returns:
nn.Sequential 模型
"""
return nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
2. 测试
import torch
sample_ffn = feed_forward_network(512, 2048)
x = torch.rand(64, 50, 512) # (batch, seq_len, d_model)
y = sample_ffn(x)
print(y.shape) # torch.Size([64, 50, 512])
# ---------output-----------
# torch.Size([64, 50, 512])
八、定义EncoderLayer层
1. 定义EncoderLayer层
class EncoderLayer(nn.Module):
"""
x -> self-attention -> add & norm & dropout
-> feed-forward -> add & norm & dropout
期望输入:
x: [B, L, d_model]
src_mask: [B, 1, L, L] 或 [B, L, L],其中 1 表示屏蔽,0 表示保留
"""
def __init__(self, d_model: int, num_heads: int, dff: int, rate: float = 0.1):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads) # 前面已实现
self.ffn = feed_forward_network(d_model, dff) # 前面已实现
self.norm1 = nn.LayerNorm(d_model, eps=1e-6)
self.norm2 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(rate)
self.dropout2 = nn.Dropout(rate)
def forward(self, x: torch.Tensor, src_mask: torch.Tensor = None):
"""
返回:
out: [B, L, d_model]
"""
# Self-Attention
attn_out, _ = self.mha(x, x, x, mask=src_mask) # [B, L, d_model], [B, H, L, L]
attn_out = self.dropout1(attn_out) # 训练模式下生效
out1 = self.norm1(x + attn_out) # 残差 + LayerNorm
# Feed Forward
ffn_out = self.ffn(out1) # [B, L, d_model]
ffn_out = self.dropout2(ffn_out)
out2 = self.norm2(out1 + ffn_out)
return out2
2. 测试
# 初始化
sample_encoder_layer = EncoderLayer(512, 8, 2048)
# 输入
sample_input = torch.rand(64, 50, 512) # (batch=64, seq_len=50, d_model=512)
# 前向
sample_output = sample_encoder_layer(sample_input, src_mask=None)
print(sample_output.shape) # torch.Size([64, 50, 512])
# ---------output-----------
# torch.Size([64, 50, 512])
九、定义DecoderLayer层
1. 定义DecoderLayer层
import torch
from torch import nn
class DecoderLayer(nn.Module):
"""
x -> masked self-attention -> add & norm & dropout -> out1
out1, enc_out -> cross-attention -> add & norm & dropout -> out2
out2 -> FFN -> add & norm & dropout -> out3
期望输入:
x: [B, L_tgt, d_model]
enc_out: [B, L_src, d_model]
tgt_mask: [B, 1, L_tgt, L_tgt] 或 [B, L_tgt, L_tgt] (look-ahead + padding 的合并掩码,1=屏蔽)
enc_dec_mask: [B, 1, L_tgt, L_src] 或 [B, L_tgt, L_src] (decoder 对 encoder 的 padding 掩码,1=屏蔽)
"""
def __init__(self, d_model: int, num_heads: int, dff: int, rate: float = 0.1):
super().__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads) # masked self-attn
self.mha2 = MultiHeadAttention(d_model, num_heads) # cross-attn
self.ffn = feed_forward_network(d_model, dff)
self.norm1 = nn.LayerNorm(d_model, eps=1e-6)
self.norm2 = nn.LayerNorm(d_model, eps=1e-6)
self.norm3 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(rate)
self.dropout2 = nn.Dropout(rate)
self.dropout3 = nn.Dropout(rate)
def forward(
self,
x: torch.Tensor,
enc_out: torch.Tensor,
tgt_mask: torch.Tensor = None,
enc_dec_mask: torch.Tensor = None,
):
# 1) Masked Self-Attention (decoder 自注意力,使用 look-ahead+padding 的合并 mask)
attn1_out, attn_weights1 = self.mha1(x, x, x, mask=tgt_mask) # [B,Lt,D], [B,H,Lt,Lt]
attn1_out = self.dropout1(attn1_out)
out1 = self.norm1(x + attn1_out)
# 2) Cross-Attention (query=out1, key/value=enc_out),使用 encoder padding 掩码
attn2_out, attn_weights2 = self.mha2(out1, enc_out, enc_out, mask=enc_dec_mask) # [B,Lt,D], [B,H,Lt,Ls]
attn2_out = self.dropout2(attn2_out)
out2 = self.norm2(out1 + attn2_out)
# 3) FFN
ffn_out = self.ffn(out2) # [B,Lt,D]
ffn_out = self.dropout3(ffn_out)
out3 = self.norm3(out2 + ffn_out) # [B,Lt,D]
return out3, attn_weights1, attn_weights2
2. 测试
# 初始化解码层
sample_decoder_layer = DecoderLayer(512, 8, 2048)
# 模拟输入 (batch=64, target_seq_len=60, d_model=512)
sample_decoder_input = torch.rand(64, 60, 512)
# 模拟 encoder 输出 (batch=64, input_seq_len=50, d_model=512)
sample_output = torch.rand(64, 50, 512)
# 前向传播
sample_decoder_output, sample_decoder_attn_weights1, sample_decoder_attn_weights2 = \
sample_decoder_layer(sample_decoder_input, sample_output, tgt_mask=None, enc_dec_mask=None)
print(sample_decoder_output.shape) # torch.Size([64, 60, 512])
print(sample_decoder_attn_weights1.shape) # torch.Size([64, 8, 60, 60])
print(sample_decoder_attn_weights2.shape) # torch.Size([64, 8, 60, 50])
# ---------output-----------
# torch.Size([64, 60, 512])
# torch.Size([64, 8, 60, 60])
# torch.Size([64, 8, 60, 50])
十、EncoderModel的实现
1. EncoderModel的实现
class EncoderModel(nn.Module):
def __init__(self, num_layers: int, input_vocab_size: int, max_length: int,
d_model: int, num_heads: int, dff: int, rate: float = 0.1,
padding_idx: int = None):
"""
参数与 Keras 版本对齐;额外提供 padding_idx 以便 Embedding 忽略 pad 的梯度。
"""
super().__init__()
self.d_model = d_model
self.num_layers = num_layers
self.max_length = max_length
# Embedding
self.embedding = nn.Embedding(input_vocab_size, d_model, padding_idx=padding_idx)
# 位置编码:注册为 buffer(不参与训练/优化器)
pe = get_position_embedding(max_length, d_model) # [1, max_len, d_model]
self.register_buffer("position_embedding", pe, persistent=False)
self.dropout = nn.Dropout(rate)
# 堆叠 EncoderLayer(前面我们已实现过)
self.encoder_layers = nn.ModuleList(
[EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
)
# 预存缩放因子
self.scale = math.sqrt(d_model)
def forward(self, x: torch.Tensor, src_mask: torch.Tensor = None):
"""
x: [B, L] (token ids)
src_mask: [B, 1, L, L] 或 [B, L, L],1=屏蔽,0=保留(与前文一致)
return: 编码结果 [B, L, d_model]
"""
B, L = x.shape
# 等价于 tf.debugging.assert_less_equal
if L > self.max_length:
raise ValueError(f"input_seq_len ({L}) should be ≤ max_length ({self.max_length})")
# [B, L, D]
x = self.embedding(x)
# 缩放:使 embedding 的尺度与位置编码相近(论文做法)
x = x * self.scale
# 加位置编码(按实际序列长度切片)
x = x + self.position_embedding[:, :L, :]
x = self.dropout(x)
# 逐层 Encoder
for layer in self.encoder_layers:
x = layer(x, src_mask)
return x
2. 测试
# 初始化 (num_layers=2, vocab_size=8500, max_length=100 假设为100)
sample_encoder_model = EncoderModel(
num_layers=2,
input_vocab_size=8500,
max_length=100,
d_model=512,
num_heads=8,
dff=2048
)
# 模拟输入 (batch=64, seq_len=37),注意输入是 token ids (整数),而不是浮点数
sample_encoder_model_input = torch.randint(0, 8500, (64, 37))
# 前向传播 (不传 mask)
sample_encoder_model_output = sample_encoder_model(sample_encoder_model_input, src_mask=None)
print(sample_encoder_model_output.shape) # torch.Size([64, 37, 512])
# ---------output-----------
# torch.Size([64, 37, 512])
十一、DecoderModel的实现
1. DecoderModel的实现
class DecoderModel(nn.Module):
"""
x -> masked self-attn -> add & norm & dropout
-> cross-attn(enc_out) -> add & norm & dropout
-> FFN -> add & norm & dropout
"""
def __init__(self, num_layers: int, target_vocab_size: int, max_length: int,
d_model: int, num_heads: int, dff: int, rate: float = 0.1,
padding_idx: int = None):
super().__init__()
self.num_layers = num_layers
self.max_length = max_length
self.d_model = d_model
# 词嵌入
self.embedding = nn.Embedding(target_vocab_size, d_model, padding_idx=padding_idx)
# 位置编码(注册为 buffer,不参与训练)
pe = get_position_embedding(max_length, d_model)
self.register_buffer("position_embedding", pe, persistent=False)
self.dropout = nn.Dropout(rate)
# 堆叠解码层
self.decoder_layers = nn.ModuleList(
[DecoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
)
self.scale = math.sqrt(d_model)
def forward(
self,
x: torch.Tensor, # [B, L_tgt] 目标端 token ids
enc_out: torch.Tensor, # [B, L_src, D] 编码器输出
tgt_mask: torch.Tensor = None, # [B, 1, L_tgt, L_tgt] 或 [B, L_tgt, L_tgt](look-ahead+padding)
enc_dec_mask: torch.Tensor = None, # [B, 1, L_tgt, L_src] 或 [B, L_tgt, L_src](对 encoder 的 padding)
):
B, Lt = x.shape
if Lt > self.max_length:
raise ValueError(f"output_seq_len ({Lt}) should be ≤ max_length ({self.max_length})")
# (B, Lt, D)
x = self.embedding(x) * self.scale
x = x + self.position_embedding[:, :Lt, :]
x = self.dropout(x)
attention_weights = {}
for i, layer in enumerate(self.decoder_layers, start=1):
x, attn1, attn2 = layer(x, enc_out, tgt_mask=tgt_mask, enc_dec_mask=enc_dec_mask)
attention_weights[f"decoder_layer{i}_att1"] = attn1 # [B, H, Lt, Lt]
attention_weights[f"decoder_layer{i}_att2"] = attn2 # [B, H, Lt, Ls]
# x: (B, Lt, D)
return x, attention_weights
2. 测试
# 初始化解码器
sample_decoder_model = DecoderModel(
num_layers=2,
target_vocab_size=8000,
max_length=100, # 这里假设 max_length=100
d_model=512,
num_heads=8,
dff=2048
)
# 模拟输入 (batch=64, seq_len=35),必须是整数 token ids
sample_decoder_model_input = torch.randint(0, 8000, (64, 35))
# 假设 encoder 的输出 (来自 EncoderModel),形状 (batch=64, src_seq_len=37, d_model=512)
sample_encoder_model_output = torch.rand(64, 37, 512)
# 前向传播(不传 mask)
sample_decoder_model.eval() # 等价于 training=False
sample_decoder_model_output, sample_decoder_model_att = sample_decoder_model(
sample_decoder_model_input,
sample_encoder_model_output,
tgt_mask=None,
enc_dec_mask=None
)
print(sample_decoder_model_output.shape) # torch.Size([64, 35, 512])
for key in sample_decoder_model_att:
print(key, sample_decoder_model_att[key].shape)
# ---------output-----------
# torch.Size([64, 35, 512])
# decoder_layer1_att1 torch.Size([64, 8, 35, 35])
# decoder_layer1_att2 torch.Size([64, 8, 35, 37])
# decoder_layer2_att1 torch.Size([64, 8, 35, 35])
# decoder_layer2_att2 torch.Size([64, 8, 35, 37])
十二、Transformer的实现
1. Transformer的实现
class Transformer(nn.Module):
def __init__(self, num_layers, input_vocab_size, target_vocab_size,
max_length, d_model, num_heads, dff, rate=0.1,
src_padding_idx: int = None, tgt_padding_idx: int = None):
super().__init__()
self.encoder_model = EncoderModel(
num_layers=num_layers,
input_vocab_size=input_vocab_size,
max_length=max_length,
d_model=d_model,
num_heads=num_heads,
dff=dff,
rate=rate,
padding_idx=src_padding_idx,
)
self.decoder_model = DecoderModel(
num_layers=num_layers,
target_vocab_size=target_vocab_size,
max_length=max_length,
d_model=d_model,
num_heads=num_heads,
dff=dff,
rate=rate,
padding_idx=tgt_padding_idx,
)
# 等价于 Keras 的 Dense(target_vocab_size)
self.final_layer = nn.Linear(d_model, target_vocab_size)
def forward(self, inp_ids, tgt_ids, src_mask=None, tgt_mask=None, enc_dec_mask=None):
"""
inp_ids: [B, L_src] 源端 token ids
tgt_ids: [B, L_tgt] 目标端 token ids(训练时通常是 shift 后的 decoder 输入)
src_mask: [B, 1, L_src, L_src] 或 [B, L_src, L_src](1=屏蔽)
tgt_mask: [B, 1, L_tgt, L_tgt] 或 [B, L_tgt, L_tgt](look-ahead+padding)
enc_dec_mask:[B, 1, L_tgt, L_src] 或 [B, L_tgt, L_src]
返回:
logits: [B, L_tgt, target_vocab_size]
attention_weights: dict,包含每层的 attn
"""
enc_out = self.encoder_model(inp_ids, src_mask=src_mask) # [B, L_src, D]
dec_out, attention_weights = self.decoder_model(
tgt_ids, enc_out, tgt_mask=tgt_mask, enc_dec_mask=enc_dec_mask
) # [B, L_tgt, D], dict
logits = self.final_layer(dec_out) # [B, L_tgt, V_tgt]
return logits, attention_weights
2. 测试
# 假设 max_length 事先定义,比如:
max_length = 100
sample_transformer = Transformer(
num_layers=2,
input_vocab_size=8500,
target_vocab_size=8000,
max_length=max_length,
d_model=512,
num_heads=8,
dff=2048,
rate=0.1,
src_padding_idx=0,
tgt_padding_idx=0,
)
# 注意:在 PyTorch 里必须是整数 token ids(而不是随机浮点)
temp_input = torch.randint(0, 8500, (64, 26)) # [B=64, L_src=26]
temp_target = torch.randint(0, 8000, (64, 31)) # [B=64, L_tgt=31]
# 不传 mask(与 Keras 示例一致)
sample_transformer.eval() # 等价于 training=False
predictions, attention_weights = sample_transformer(
temp_input, temp_target, src_mask=None, tgt_mask=None, enc_dec_mask=None
)
print(predictions.shape) # torch.Size([64, 31, 8000])
for key in attention_weights:
print(key, attention_weights[key].shape)
# ---------output-----------
# torch.Size([64, 31, 8000])
# decoder_layer1_att1 torch.Size([64, 8, 31, 31])
# decoder_layer1_att2 torch.Size([64, 8, 31, 26])
# decoder_layer2_att1 torch.Size([64, 8, 31, 31])
# decoder_layer2_att2 torch.Size([64, 8, 31, 26])
十三、初始化参数,实例化Transformer
"""
# 1. initializes model.
# 2. define loss, optimizer, learning_rate schedule
# 3. train_step
# 4. train process
"""
# 假设已经有:pt_tokenizer, en_tokenizer, max_length, Transformer 类
num_layers = 4
d_model = 128
dff = 512
num_heads = 8
dropout_rate = 0.1
# BBPE 分词器已自带特殊符号(bos/eos/pad等)→ 不要 +2
input_vocab_size = pt_tokenizer.vocab_size
target_vocab_size = en_tokenizer.vocab_size
transformer = Transformer(
num_layers=num_layers,
input_vocab_size=input_vocab_size,
target_vocab_size=target_vocab_size,
max_length=max_length,
d_model=d_model,
num_heads=num_heads,
dff=dff,
rate=dropout_rate,
src_padding_idx=pt_tokenizer.pad_token_id if hasattr(pt_tokenizer, "pad_token_id") else None,
tgt_padding_idx=en_tokenizer.pad_token_id if hasattr(en_tokenizer, "pad_token_id") else None,
)
十四、自定义学习率和优化器
1. 自定义学习率
import math
from torch.optim.lr_scheduler import _LRScheduler
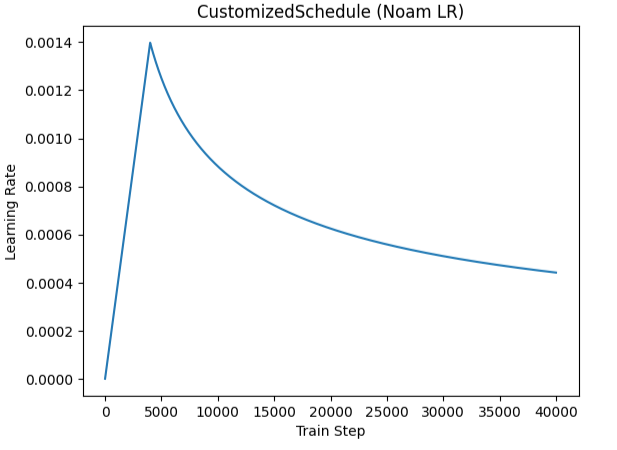
class CustomizedSchedule(_LRScheduler):
"""
Noam / Transformer LR:
lr = d_model**(-0.5) * min(step**(-0.5), step * warmup_steps**(-1.5))
"""
def __init__(self, optimizer, d_model, warmup_steps=4000, last_epoch=-1):
self.d_model = float(d_model)
self.warmup_steps = float(warmup_steps)
super().__init__(optimizer, last_epoch)
def get_lr(self):
step = max(1, self.last_epoch + 1) # 确保从 1 开始
scale = self.d_model ** -0.5
arg1 = step ** -0.5
arg2 = step * (self.warmup_steps ** -1.5)
lr = scale * min(arg1, arg2)
return [lr for _ in self.base_lrs]
2. 测试
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(10, 10)
optimizer = optim.Adam(model.parameters(),
lr=1.0, # 占位
betas=(0.9, 0.98),
eps=1e-9)
scheduler = CustomizedSchedule(optimizer, d_model=128, warmup_steps=4000)
for step in range(1, 6):
optimizer.step()
scheduler.step()
optimizer.zero_grad()
print(f"step={step:2d}, lr={scheduler.get_last_lr()[0]:.8f}")
# ---------output-----------
# step= 1, lr=0.00000070
# step= 2, lr=0.00000105
# step= 3, lr=0.00000140
# step= 4, lr=0.00000175
# step= 5, lr=0.00000210
3. 打印自定义学习率曲线
def plot_customized_lr_curve(optimizer, scheduler, total_steps: int, label: str = None):
"""
绘制学习率曲线(支持传入已有 optimizer 和 scheduler)
Args:
optimizer (torch.optim.Optimizer): 优化器
scheduler (torch.optim.lr_scheduler._LRScheduler): 学习率调度器
total_steps (int): 总训练步数
label (str): 图例标签,默认使用 scheduler 配置
"""
lrs = []
for step in range(total_steps):
scheduler.step()
lr = scheduler.get_last_lr()[0]
lrs.append(lr)
# 绘制曲线
plt.figure(figsize=(8, 4))
plt.plot(range(1, total_steps + 1), lrs, label=label or "LR Curve")
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")
plt.title("Learning Rate Schedule")
plt.legend()
plt.grid(True)
plt.show()
plot_customized_lr_curve(optimizer, scheduler, total_steps=num_training_steps, label=f"d_model={d_model}, warmup={warmup_steps}")
十五、自定义损失函数
import torch
import torch.nn as nn
# PyTorch 的 CrossEntropyLoss 默认就支持 from_logits=True
loss_object = nn.CrossEntropyLoss(reduction="none")
def loss_function(real, pred):
"""
real: (batch_size, seq_len) -- target token ids
pred: (batch_size, seq_len, vocab_size) -- model output logits
"""
# 展平数据,方便 CrossEntropyLoss 计算
pred = pred.view(-1, pred.size(-1)) # (batch_size*seq_len, vocab_size)
real = real.view(-1) # (batch_size*seq_len)
# 逐元素交叉熵
loss_ = loss_object(pred, real) # (batch_size*seq_len,)
# mask 掉 padding (id=0)
mask = (real != 0).float() # 1: 有效, 0: padding
loss_ = loss_ * mask
# 返回均值损失
return loss_.sum() / mask.sum()
十六、Mask的创建与使用
1. Mask的创建
def create_masks(
inp_ids: torch.Tensor, # [B, L_src]
tar_ids: torch.Tensor, # [B, L_tgt] —— 通常是 decoder 输入(已左移)
src_pad_id: int = 0,
tgt_pad_id: int = 0,
):
"""
返回:
encoder_padding_mask : [B, 1, 1, L_src] (给 EncoderLayer self-attn)
decoder_mask (LA + padding) : [B, 1, L_tgt, L_tgt] (给 DecoderLayer 自注意力)
encoder_decoder_padding_mask : [B, 1, 1, L_src] (给 DecoderLayer cross-attn)
语义:
1 = 屏蔽(masked),0 = 保留
"""
# 1) Encoder 端 padding mask
encoder_padding_mask = create_padding_mask(inp_ids, pad_token_id=src_pad_id) # [B,1,1,L_src]
encoder_decoder_padding_mask = create_padding_mask(inp_ids, pad_token_id=src_pad_id) # [B,1,1,L_src]
# 2) Decoder 端 look-ahead + padding 合并
B, L_tgt = tar_ids.size(0), tar_ids.size(1)
# [L_tgt, L_tgt] → [1,1,L_tgt,L_tgt],放到与输入相同 device/dtype
look_ahead = create_look_ahead_mask(L_tgt).to(
device=tar_ids.device, dtype=encoder_padding_mask.dtype
).unsqueeze(0).unsqueeze(1) # [1,1,L_tgt,L_tgt]
# 目标端 padding: [B,1,1,L_tgt] → 扩到 [B,1,L_tgt,L_tgt]
decoder_padding_mask = create_padding_mask(tar_ids, pad_token_id=tgt_pad_id) # [B,1,1,L_tgt]
decoder_padding_mask = decoder_padding_mask.expand(-1, -1, L_tgt, -1) # [B,1,L_tgt,L_tgt]
# 合并(任一为 1 即屏蔽)
decoder_mask = torch.maximum(decoder_padding_mask, look_ahead) # [B,1,L_tgt,L_tgt]
return encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask
2. 测试
# 从 DataLoader 里取一个 batch
batch = next(iter(train_loader2)) # train_loader2 就是之前我们写的 DataLoader
# 取出输入和目标序列
temp_inp = batch["pt_input_ids"] # [B, L_src]
temp_tar = batch["en_input_ids"] # [B, L_tgt]
print("temp_inp:", temp_inp.shape) # e.g. torch.Size([64, 37])
print("temp_tar:", temp_tar.shape) # e.g. torch.Size([64, 40])
# 创建 mask —— 使用我们刚写好的 create_masks
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
temp_inp, temp_tar,
src_pad_id=pt_tokenizer.pad_token_id,
tgt_pad_id=en_tokenizer.pad_token_id,
)
print("enc_pad_mask:", enc_pad_mask.shape)
print("dec_mask:", dec_mask.shape)
print("enc_dec_pad_mask:", enc_dec_pad_mask.shape)
# ---------output-----------
# temp_inp: torch.Size([64, 44])
# temp_tar: torch.Size([64, 48])
# enc_pad_mask: torch.Size([64, 1, 1, 44])
# dec_mask: torch.Size([64, 1, 48, 48])
# enc_dec_pad_mask: torch.Size([64, 1, 1, 44])
十七、定义训练模型
1. 定义单个训练step
import torch
import torch.nn as nn
# === token 准确率(忽略 pad=0) ===
@torch.no_grad()
def token_accuracy(real, pred, pad_id):
pred_ids = pred.argmax(dim=-1) # (B, L)
mask = (real != pad_id)
correct = ((pred_ids == real) & mask).sum().item()
denom = mask.sum().item()
return correct / max(1, denom)
class AverageMeter:
def __init__(self, name="meter"): self.name = name; self.reset()
def reset(self): self.sum = 0.0; self.n = 0
def update(self, val, count=1): self.sum += float(val) * count; self.n += count
@property
def avg(self): return self.sum / max(1, self.n)
def train_step(batch, transformer, optimizer, scheduler=None, device=None):
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
transformer.train()
inp = batch["pt_input_ids"].to(device)
tar = batch["en_input_ids"].to(device)
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
SRC_PAD_ID = pt_tokenizer.pad_token_id
TGT_PAD_ID = en_tokenizer.pad_token_id
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
inp, tar_inp, src_pad_id=SRC_PAD_ID, tgt_pad_id=TGT_PAD_ID
)
enc_dec_mask = enc_dec_pad_mask.expand(-1, 1, tar_inp.size(1), -1)
logits, _ = transformer(
inp, tar_inp,
src_mask=enc_pad_mask,
tgt_mask=dec_mask,
enc_dec_mask=enc_dec_mask
)
loss = loss_function(tar_real, logits)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(transformer.parameters(), max_norm=1.0)
optimizer.step()
if scheduler is not None:
scheduler.step()
acc = token_accuracy(tar_real, logits, pad_id=TGT_PAD_ID)
return loss.item(), acc
2. 定义训练模型
def train_model(
epochs: int,
model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
train_loader: torch.utils.data.DataLoader,
val_loader: torch.utils.data.DataLoader,
scheduler=None,
device: str = None,
log_every: int = 100,
ckpt_dir: str = "checkpoints",
ckpt_prefix: str = "ckpt",
):
os.makedirs(ckpt_dir, exist_ok=True)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
train_loss_meter = AverageMeter("train_loss")
train_acc_meter = AverageMeter("train_accuracy")
global_step = 0
for epoch in range(epochs):
try:
start = time.time()
train_loss_meter.reset()
train_acc_meter.reset()
model.train()
for batch_idx, batch in enumerate(train_loader):
loss_val, acc_val = train_step(
batch=batch, transformer=model, optimizer=optimizer, scheduler=scheduler, device=device
)
train_loss_meter.update(loss_val, 1)
train_acc_meter.update(acc_val, 1)
global_step += 1
if batch_idx % log_every == 0:
print(
f"Epoch {epoch+1} Batch {batch_idx} "
f"Loss {train_loss_meter.avg:.4f} Accuracy {train_acc_meter.avg:.4f}"
)
save_ckpt(
model=model,
optimizer=optimizer,
scheduler=scheduler,
epoch=epoch+1,
step=global_step,
ckpt_dir=ckpt_dir,
tag="latest"
)
print(f"Epoch {epoch+1} Loss {train_loss_meter.avg:.4f} Accuracy {train_acc_meter.avg:.4f}")
print(f"Time taken for 1 epoch: {time.time() - start:.2f} secs\n")
# 每个epoch结束后进行验证集评测
validate_loss, validate_acc = evaluate_on_val(model, val_loader, device)
print(f"Validation - Epoch {epoch+1} Loss: {validate_loss:.4f}, Accuracy: {validate_acc:.4f}\n")
except Exception as e:
print(f"报错啦!!! 报错信息: {e}")
save_ckpt(
model=model,
optimizer=optimizer,
scheduler=scheduler,
epoch=epoch,
step=global_step,
tag="error"
)
# ========= 运行训练 =========
EPOCHS = 60
train_model(
epochs=EPOCHS,
model=transformer,
optimizer=optimizer,
train_loader=train_loader2,
scheduler=scheduler, # Noam 调度
device=None, # 自动选 GPU/CPU
log_every=100,
ckpt_dir="checkpoints",
ckpt_prefix="transformer",
)
十八、checkpoints
# 十八、checkpoints
def load_ckpt(model, optimizer=None, scheduler=None, ckpt_dir="checkpoints", device="cpu"):
"""
加载最新 checkpoint
"""
latest = os.path.join(ckpt_dir, "latest.pt")
if not os.path.exists(latest):
print("⚠️ No checkpoint found, training from scratch.")
return 0, 0
ckpt = torch.load(latest, map_location=device)
model.load_state_dict(ckpt["model"])
if optimizer: optimizer.load_state_dict(ckpt["optim"])
if scheduler and ckpt["sched"]: scheduler.load_state_dict(ckpt["sched"])
print(f"✅ checkpoint loaded (epoch={ckpt['epoch']}, step={ckpt['step']})")
return ckpt["epoch"], ckpt["step"]
def save_ckpt(model, optimizer, scheduler, epoch, step, ckpt_dir="checkpoints", tag="latest"):
"""
保存 checkpoint
Args:
model: nn.Module
optimizer: torch.optim
scheduler: torch.optim.lr_scheduler (可选)
epoch: 当前 epoch
step: 全局 step
ckpt_dir: 保存目录
tag: 保存标识 ("latest", "error", "custom" 等)
"""
os.makedirs(ckpt_dir, exist_ok=True)
ckpt = {
"epoch": epoch,
"step": step,
"model": model.state_dict(),
"optim": optimizer.state_dict(),
"sched": scheduler.state_dict() if scheduler else None,
}
latest_path = os.path.join(ckpt_dir, "latest.pt")
torch.save(ckpt, latest_path)
# print(f"✅ checkpoint updated: {latest_path}")
# 1. 默认保存 latest
if tag == "latest":
path = os.path.join(ckpt_dir, f"mid_e{epoch}_s{step}.pt")
elif tag == "error":
# 避免覆盖,用时间戳
ts = datetime.now().strftime("%Y%m%d_%H%M%S")
path = os.path.join(ckpt_dir, f"error_e{epoch}_s{step}_{ts}.pt")
else:
path = os.path.join(ckpt_dir, f"{tag}_e{epoch}_s{step}.pt")
torch.save(ckpt, path)
# print(f"✅ checkpoint saved: {path}")
return path
十九、模型预测实现
@torch.no_grad()
def evaluate(
inp_sentence: str,
transformer: Transformer,
pt_tokenizer,
en_tokenizer,
max_length: int,
device: str = None):
"""
inp_sentence: 输入的源语言字符串 (pt)
transformer: 已训练的 Transformer
pt_tokenizer, en_tokenizer: 分别是葡萄牙语和英语 tokenizer
max_length: 最大生成长度
"""
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
transformer.eval()
transformer.to(device)
# 1. 编码输入,加 <s> 和 </s>
inp_ids = encode_with_bos_eos(pt_tokenizer, inp_sentence)
encoder_input = torch.tensor(inp_ids, dtype=torch.long, device=device).unsqueeze(0) # (1, Ls)
# 2. decoder 起始符 <s>
start_id = en_tokenizer.bos_token_id
end_id = en_tokenizer.eos_token_id
decoder_input = torch.tensor([[start_id]], dtype=torch.long, device=device) # (1, 1)
# 3. 循环预测
attention_weights = {}
for _ in range(max_length):
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
encoder_input, decoder_input,
src_pad_id=pt_tokenizer.pad_token_id,
tgt_pad_id=en_tokenizer.pad_token_id,
)
enc_dec_mask = enc_dec_pad_mask.expand(-1, 1, decoder_input.size(1), -1)
logits, attn = transformer(
encoder_input, decoder_input,
src_mask=enc_pad_mask,
tgt_mask=dec_mask,
enc_dec_mask=enc_dec_mask,
)
# 取最后一步预测
next_token_logits = logits[:, -1, :] # (1, V)
predicted_id = torch.argmax(next_token_logits, dim=-1) # (1,)
if predicted_id.item() == end_id:
break
# 拼接到 decoder_input
decoder_input = torch.cat(
[decoder_input, predicted_id.unsqueeze(0)], dim=-1
) # (1, Lt+1)
attention_weights = attn
return decoder_input.squeeze(0).tolist(), attention_weights
@torch.no_grad()
def evaluate_on_val(model, val_loader, device):
model.eval()
total_loss = 0
total_acc = 0
total_count = 0
for batch in val_loader:
inp = batch["pt_input_ids"].to(device)
tar = batch["en_input_ids"].to(device)
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
inp, tar_inp, src_pad_id=pt_tokenizer.pad_token_id, tgt_pad_id=en_tokenizer.pad_token_id
)
enc_dec_mask = enc_dec_pad_mask.expand(-1, 1, tar_inp.size(1), -1)
logits, _ = model(
inp, tar_inp,
src_mask=enc_pad_mask,
tgt_mask=dec_mask,
enc_dec_mask=enc_dec_mask
)
loss = loss_function(tar_real, logits)
acc = token_accuracy(tar_real, logits, pad_id=en_tokenizer.pad_token_id)
total_loss += loss.item() * inp.size(0)
total_acc += acc * inp.size(0)
total_count += inp.size(0)
avg_loss = total_loss / total_count
avg_acc = total_acc / total_count
return avg_loss, avg_acc
二十、Attention可视化
import matplotlib.pyplot as plt
def plot_encoder_decoder_attention(attention, input_sentence, result, layer_name):
"""
attention: 来自 forward 返回的 attention_weights dict
形状 [B, num_heads, tgt_len, src_len]
input_sentence: 源语言字符串
result: 目标句子 token id 列表 (decoder 输出)
layer_name: 指定可视化的层 key,比如 "decoder_layer1_att2"
"""
fig = plt.figure(figsize=(16, 8))
# 源句子编码
input_id_sentence = pt_tokenizer.encode(input_sentence, add_special_tokens=False)
# 取 batch 维度 squeeze,并转 numpy
attn = attention[layer_name].squeeze(0) # [num_heads, tgt_len, src_len]
attn = attn.detach().cpu().numpy()
for head in range(attn.shape[0]):
ax = fig.add_subplot(2, 4, head + 1)
# 只取 result[:-1] 的注意力 (去掉最后 <eos>)
ax.matshow(attn[head][:-1, :], cmap="viridis")
fontdict = {"fontsize": 10}
# X 轴: 输入 token (<s> + sentence + </s>)
ax.set_xticks(range(len(input_id_sentence) + 2))
ax.set_xticklabels(
["<s>"] + [pt_tokenizer.decode([i]) for i in input_id_sentence] + ["</s>"],
fontdict=fontdict, rotation=90,
)
# Y 轴: decoder 输出 token
ax.set_yticks(range(len(result)))
ax.set_yticklabels(
[en_tokenizer.decode([i]) for i in result if i < en_tokenizer.vocab_size],
fontdict=fontdict,
)
ax.set_ylim(len(result) - 1.5, -0.5)
ax.set_xlabel(f"Head {head+1}")
plt.tight_layout()
plt.show()
二十一、TransFormer模型示例展示
def translate(input_sentence, transformer, pt_tokenizer, en_tokenizer,
max_length=64, device=None, layer_name=""):
# 调用我们改好的 evaluate (PyTorch 版)
result, attention_weights = evaluate(
inp_sentence=input_sentence,
transformer=transformer,
pt_tokenizer=pt_tokenizer,
en_tokenizer=en_tokenizer,
max_length=max_length,
device=device,
)
# 把 token id 转回句子
predicted_sentence = en_tokenizer.decode(
[i for i in result if i < en_tokenizer.vocab_size],
skip_special_tokens=True
)
print("Input: {}".format(input_sentence))
print("Predicted translation: {}".formatpredicted_sentence))
# 如果传入了 layer_name,就画注意力图
if layer_name:
plot_encoder_decoder_attention(
attention_weights,
input_sentence,
result,
layer_name
)
return predicted_sentence
二十二、总结代码
# -*- coding: utf-8 -*-
import os
import sys
import time
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import sklearn
from pathlib import Path
from datasets import load_dataset
from tokenizers import ByteLevelBPETokenizer
from transformers import PreTrainedTokenizerFast
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
from torch.optim.lr_scheduler import _LRScheduler
from transformers import get_cosine_schedule_with_warmup
from datetime import datetime
os.environ["CUDA_VISIBLE_DEVICES"] = "4"
def check_env():
"""
检查 PyTorch 环境信息、GPU 状态,以及常用依赖库版本。
返回推荐的 device ('cuda' 或 'cpu')。
"""
print("===== PyTorch & 系统信息 =====")
print("torch.__version__:", torch.__version__)
print("python version:", sys.version_info)
print("\n===== 常用库版本 =====")
for module in (mpl, np, pd, torch):
print(module.__name__, module.__version__)
print("\n===== GPU 检查 =====")
print("torch.cuda.is_available():", torch.cuda.is_available())
print("torch.version.cuda:", torch.version.cuda)
try:
print("cudnn version:", torch.backends.cudnn.version())
except Exception as e:
print("cudnn version: N/A", e)
if torch.cuda.is_available():
print("GPU count:", torch.cuda.device_count())
print("Current device id:", torch.cuda.current_device())
print("GPU name:", torch.cuda.get_device_name(0))
print("bfloat16 supported:", torch.cuda.is_bf16_supported())
# 启用 TF32
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
try:
torch.set_float32_matmul_precision("high")
except Exception:
pass
device = "cuda"
else:
print("⚠️ 没检测到 CUDA,可强制 device='cpu' 运行,但速度会慢")
device = "cpu"
print("\n推荐使用 device: Cuda;")
return device
def load_translation_dataset(
train_path: str,
val_path: str,
src_lang: str = "src",
tgt_lang: str = "tgt",
delimiter: str = "\t"
):
"""
通用机器翻译数据集加载函数
参数:
train_path: 训练集 CSV 文件路径
val_path: 验证集 CSV 文件路径
src_lang: 源语言列名 (例如 'de', 'fr', 'zh')
tgt_lang: 目标语言列名 (例如 'en', 'ja')
delimiter: 分隔符,默认制表符 '\t'
返回:
train_dataset, val_dataset
"""
print(f"开始加载 {src_lang} → {tgt_lang} 翻译数据...")
dataset = load_dataset(
"csv",
data_files={
"train": train_path,
"validation": val_path
},
column_names=[src_lang, tgt_lang],
delimiter=delimiter,
skiprows=1 # 跳过第一行
)
print("数据集类型:", type(dataset))
print(dataset)
# 打印一个样本
sample = dataset["train"][0]
print(f"示例数据 -> {src_lang}: {sample[src_lang]} | {tgt_lang}: {sample[tgt_lang]}")
return dataset["train"], dataset["validation"]
def train_and_load_tokenizers(
train_dataset,
src_lang="src",
tgt_lang='tgt',
vocab_size=2**13,
min_freq=2,
special_tokens=["<s>", "<pad>", "</s>", "<unk>", "<mask>"],
save_dir_src="tok_src",
save_dir_tgt="tok_tgt",
max_length=1024):
"""
训练并加载两种语言的 ByteLevel BPE Tokenizer
参数:
train_dataset: 数据集 (需包含 src_lang 和 tgt_lang 两列)
src_lang: 源语言字段名
tgt_lang: 目标语言字段名
vocab_size: 词表大小
min_freq: 最小词频
special_tokens: 特殊符号
save_dir_src: 葡语 tokenizer 保存路径
save_dir_tgt: 英语 tokenizer 保存路径
max_length: 模型最大序列长度
返回:
pt_tokenizer, en_tokenizer
"""
def iter_lang(ds, key):
for ex in ds:
txt = ex[key]
if isinstance(txt, bytes):
txt = txt.decode("utf-8")
yield txt
# 初始化 tokenizer
src_bbpe = ByteLevelBPETokenizer(add_prefix_space=True)
tgt_bbpe = ByteLevelBPETokenizer(add_prefix_space=True)
# 训练 tokenizer
src_bbpe.train_from_iterator(
iter_lang(train_dataset, src_lang),
vocab_size=vocab_size,
min_frequency=min_freq,
special_tokens=special_tokens,
)
tgt_bbpe.train_from_iterator(
iter_lang(train_dataset, tgt_lang),
vocab_size=vocab_size,
min_frequency=min_freq,
special_tokens=special_tokens,
)
# 保存 vocab/merges + tokenizer.json
Path(save_dir_src).mkdir(exist_ok=True)
Path(save_dir_tgt).mkdir(exist_ok=True)
src_bbpe.save_model(save_dir_src)
tgt_bbpe.save_model(save_dir_tgt)
src_bbpe._tokenizer.save(f"{save_dir_src}/tokenizer.json")
tgt_bbpe._tokenizer.save(f"{save_dir_tgt}/tokenizer.json")
# 用 PreTrainedTokenizerFast 加载
src_tokenizer = PreTrainedTokenizerFast(tokenizer_file=f"{save_dir_src}/tokenizer.json")
tgt_tokenizer = PreTrainedTokenizerFast(tokenizer_file=f"{save_dir_tgt}/tokenizer.json")
# 设置特殊符号
for tok in (src_tokenizer, tgt_tokenizer):
tok.pad_token = "<pad>"
tok.unk_token = "<unk>"
tok.bos_token = "<s>"
tok.eos_token = "</s>"
tok.mask_token = "<mask>"
tok.model_max_length = max_length
tok.padding_side = "right"
print("pt vocab size:", len(src_tokenizer))
print("en vocab size:", len(tgt_tokenizer))
return src_tokenizer, tgt_tokenizer
def test_tokenizers(
src_tokenizer,
tgt_tokenizer,
dataset,
src_lang: str = "src",
tgt_lang: str = "tgt",
num_samples: int = 1
):
"""
通用双语 tokenizer 测试函数(顺序打印前 num_samples 条样本)。
参数:
src_tokenizer: 源语言 tokenizer
tgt_tokenizer: 目标语言 tokenizer
dataset: 包含源语言和目标语言字段的数据集
src_lang: 源语言列名 (如 'de', 'fr', 'zh')
tgt_lang: 目标语言列名 (如 'en', 'ja', 'es')
num_samples: 要打印的样本数量(默认 1)
"""
if dataset is None or len(dataset) == 0:
raise ValueError("❌ dataset 为空,无法取样。")
end_index = min(num_samples, len(dataset))
print(f"🔹 从第 0 条开始,顺序打印前 {end_index} 条样本(共 {len(dataset)} 条)\n")
for i in range(end_index):
sample = dataset[i]
src_sample = sample[src_lang]
tgt_sample = sample[tgt_lang]
print(f"\n===== 样本 {i} ({src_lang} → {tgt_lang}) =====")
print(f"{src_lang}: {src_sample}")
print(f"{tgt_lang}: {tgt_sample}")
print("-" * 60)
# === 源语言 Tokenizer 测试 ===
print(f"\n=== {src_lang.upper()} Tokenizer Test ===")
src_ids = src_tokenizer.encode(src_sample, add_special_tokens=False)
print(f"[{src_lang.upper()}] Tokenized IDs: {src_ids}")
src_decoded = src_tokenizer.decode(
src_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(f"[{src_lang.upper()}] Decoded string: {src_decoded}")
assert src_decoded == src_sample, f"{src_lang.upper()} decode != original input!"
print(f"[{src_lang.upper()}] id --> decoded([id]) | id --> token(str)")
for tid in src_ids:
single_decoded = src_tokenizer.decode([tid], skip_special_tokens=True)
token_str = src_tokenizer.convert_ids_to_tokens(tid)
print(f"{tid:>6} --> {single_decoded!r} | {tid:>6} --> {token_str!r}")
print("\n" + "-" * 60 + "\n")
# === 目标语言 Tokenizer 测试 ===
print(f"=== {tgt_lang.upper()} Tokenizer Test ===")
tgt_ids = tgt_tokenizer.encode(tgt_sample, add_special_tokens=False)
print(f"[{tgt_lang.upper()}] Tokenized IDs: {tgt_ids}")
tgt_decoded = tgt_tokenizer.decode(
tgt_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(f"[{tgt_lang.upper()}] Decoded string: {tgt_decoded}")
assert tgt_decoded == tgt_sample, f"{tgt_lang.upper()} decode != original input!"
print(f"[{tgt_lang.upper()}] id --> decoded([id]) | id --> token(str)")
for tid in tgt_ids:
single_decoded = tgt_tokenizer.decode([tid], skip_special_tokens=True)
token_str = tgt_tokenizer.convert_ids_to_tokens(tid)
print(f"{tid:>6} --> {single_decoded!r} | {tid:>6} --> {token_str!r}")
print("\n" + "=" * 80 + "\n")
def build_dataloaders(
train_dataset,
val_dataset,
src_tokenizer,
tgt_tokenizer,
src_lang: str = "src",
tgt_lang: str = "tgt",
batch_size: int = 64,
max_length: int = 48,
num_workers: int = 0,
shuffle_train: bool = True,
):
"""
通用双语翻译任务的 DataLoader 构建函数
参数:
train_dataset: HuggingFace Dataset (训练集)
val_dataset: HuggingFace Dataset (验证集)
src_tokenizer: 源语言 tokenizer
tgt_tokenizer: 目标语言 tokenizer
src_lang: 源语言字段名(如 'de', 'fr', 'zh')
tgt_lang: 目标语言字段名(如 'en', 'ja', 'es')
batch_size: 批大小
max_length: 样本最大长度(超过则过滤)
num_workers: DataLoader worker 数量
shuffle_train: 是否打乱训练集
返回:
train_loader, val_loader
"""
# === 1) 工具函数:编码并添加 BOS/EOS ===
def encode_with_bos_eos(tokenizer, text: str):
ids = tokenizer.encode(text, add_special_tokens=False)
bos_id = tokenizer.bos_token_id
eos_id = tokenizer.eos_token_id
if bos_id is None or eos_id is None:
raise ValueError("❌ tokenizer 未设置 bos_token/eos_token")
return [bos_id] + ids + [eos_id]
# === 2) 构造过滤后的样本对 ===
def build_filtered_pairs(hf_split, src_tok, tgt_tok, max_len: int):
pairs, kept, skipped = [], 0, 0
for ex in hf_split:
src_ids = encode_with_bos_eos(src_tok, ex[src_lang])
tgt_ids = encode_with_bos_eos(tgt_tok, ex[tgt_lang])
if len(src_ids) <= max_len and len(tgt_ids) <= max_len:
pairs.append((src_ids, tgt_ids))
kept += 1
else:
skipped += 1
print(f"[filter] kept={kept}, skipped={skipped}, max_length={max_len}")
return pairs
train_pairs = build_filtered_pairs(train_dataset, src_tokenizer, tgt_tokenizer, max_length)
val_pairs = build_filtered_pairs(val_dataset, src_tokenizer, tgt_tokenizer, max_length)
# === 3) Dataset 类 ===
class TranslationPairsDataset(Dataset):
def __init__(self, pairs):
self.pairs = pairs
def __len__(self):
return len(self.pairs)
def __getitem__(self, idx):
src_ids, tgt_ids = self.pairs[idx]
return {
f"{src_lang}_input_ids": src_ids,
f"{tgt_lang}_input_ids": tgt_ids
}
# === 4) Collate 函数(动态 padding)===
def collate_padded(batch, pad_id_src: int, pad_id_tgt: int):
def pad_block(seqs, pad_value):
max_len = max(len(s) for s in seqs)
out = torch.full((len(seqs), max_len), pad_value, dtype=torch.long)
attn = torch.zeros((len(seqs), max_len), dtype=torch.long)
for i, s in enumerate(seqs):
L = len(s)
out[i, :L] = torch.tensor(s, dtype=torch.long)
attn[i, :L] = 1
return out, attn
src_ids_list = [ex[f"{src_lang}_input_ids"] for ex in batch]
tgt_ids_list = [ex[f"{tgt_lang}_input_ids"] for ex in batch]
src_input_ids, src_attention_mask = pad_block(src_ids_list, pad_id_src)
tgt_input_ids, tgt_attention_mask = pad_block(tgt_ids_list, pad_id_tgt)
return {
f"{src_lang}_input_ids": src_input_ids,
f"{src_lang}_attention_mask": src_attention_mask,
f"{tgt_lang}_input_ids": tgt_input_ids,
f"{tgt_lang}_attention_mask": tgt_attention_mask,
}
# === 5) DataLoader 构建 ===
train_loader = DataLoader(
TranslationPairsDataset(train_pairs),
batch_size=batch_size,
shuffle=shuffle_train,
collate_fn=lambda b: collate_padded(b, src_tokenizer.pad_token_id, tgt_tokenizer.pad_token_id),
num_workers=num_workers,
)
val_loader = DataLoader(
TranslationPairsDataset(val_pairs),
batch_size=batch_size,
shuffle=False,
collate_fn=lambda b: collate_padded(b, src_tokenizer.pad_token_id, tgt_tokenizer.pad_token_id),
num_workers=num_workers,
)
print(f"✅ DataLoader 构建完成:train={len(train_pairs)},val={len(val_pairs)}")
return train_loader, val_loader
def test_dataloaders(
train_loader,
val_loader,
src_lang: str = "src",
tgt_lang: str = "tgt",
show_val: bool = True
):
"""
通用 DataLoader 检查函数,打印 batch 形状并展示一个样本。
参数:
train_loader: 训练 DataLoader
val_loader: 验证 DataLoader
src_lang: 源语言字段名 (如 'de', 'fr', 'zh')
tgt_lang: 目标语言字段名 (如 'en', 'ja', 'es')
show_val: 是否展示验证集样本(默认 True)
"""
# === 1. 查看一个训练 batch 的形状 ===
batch = next(iter(train_loader))
print("=== Train Loader Batch Shapes ===")
for k, v in batch.items():
print(f"{k:25s} {tuple(v.shape)}")
# === 2. 查看验证集的一个样本 ===
if show_val:
print("\n=== Validation Loader Example ===")
for i in val_loader:
print(f"{src_lang}_input_ids: ", i[f"{src_lang}_input_ids"][0])
print(f"{src_lang}_attention_mask: ", i[f"{src_lang}_attention_mask"][0])
print(f"{tgt_lang}_input_ids: ", i[f"{tgt_lang}_input_ids"][0])
print(f"{tgt_lang}_attention_mask: ", i[f"{tgt_lang}_attention_mask"][0])
break
def get_position_embedding(sentence_length: int, d_model: int, device="cuda", dtype=torch.float32):
"""
返回 position 对应的 embedding 矩阵
形状: [1, sentence_length, d_model]
"""
def get_angles(pos: torch.Tensor, i: torch.Tensor, d_model: int):
"""
获取单词 pos 对应 embedding 的角度
pos: [sentence_length, 1]
i : [1, d_model]
return: [sentence_length, d_model]
"""
angle_rates = 1.0 / torch.pow(
10000,
(2 * torch.div(i, 2, rounding_mode='floor')).float() / d_model
)
return pos.float() * angle_rates
if device is None:
device = torch.device("cpu")
pos = torch.arange(sentence_length, device=device).unsqueeze(1) # [L, 1]
i = torch.arange(d_model, device=device).unsqueeze(0) # [1, D]
angle_rads = get_angles(pos, i, d_model) # [L, D]
# 偶数下标:sin
sines = torch.sin(angle_rads[:, 0::2])
# 奇数下标:cos
cosines = torch.cos(angle_rads[:, 1::2])
# 拼接还原成 [L, D]
position_embedding = torch.zeros((sentence_length, d_model), device=device, dtype=dtype)
position_embedding[:, 0::2] = sines
position_embedding[:, 1::2] = cosines
# 增加 batch 维度 [1, L, D]
position_embedding = position_embedding.unsqueeze(0)
return position_embedding
def plot_position_embedding(position_embedding: torch.Tensor):
"""
可视化位置编码矩阵
参数:
position_embedding: [1, L, D] 的张量
"""
# 转到 CPU,并转成 numpy
pe = position_embedding.detach().cpu().numpy()[0] # [L, D]
plt.figure(figsize=(10, 6))
plt.pcolormesh(pe, cmap='RdBu') # L × D 矩阵
plt.xlabel("Depth (d_model)")
plt.xlim((0, pe.shape[1]))
plt.ylabel("Position (pos)")
plt.colorbar()
plt.title("Positional Encoding Visualization")
plt.show()
def create_padding_mask(batch_data: torch.Tensor, pad_token_id: int = 0):
"""
输入:
batch_data: [batch_size, seq_len],填充位置用 pad_token_id 表示
pad_token_id: 默认是 0
输出:
padding_mask: [batch_size, 1, 1, seq_len]
"""
# 等价于 tf.math.equal(batch_data, 0)
mask = (batch_data == pad_token_id).float()
# 插入维度
return mask[:, None, None, :] # [B, 1, 1, L]
def create_look_ahead_mask(size: int):
"""
生成 Look-ahead mask (上三角矩阵)
参数:
size: 序列长度 (seq_len)
返回:
mask: [seq_len, seq_len],上三角为 1,其他为 0
"""
# ones: [size, size]
ones = torch.ones((size, size))
# 取上三角(不含对角线)=1,下三角和对角线=0
mask = torch.triu(ones, diagonal=1)
return mask
def scaled_dot_product_attention(q, k, v, mask=None):
"""
Args:
q: (..., seq_len_q, depth)
k: (..., seq_len_k, depth)
v: (..., seq_len_v, depth_v) (seq_len_k == seq_len_v)
mask: (..., seq_len_q, seq_len_k),
mask里1表示要忽略的位置,0表示保留。
Returns:
output: (..., seq_len_q, depth_v) 加权和
attention_weights: (..., seq_len_q, seq_len_k) 注意力权重
"""
# (..., seq_len_q, seq_len_k)
matmul_qk = torch.matmul(q, k.transpose(-2, -1))
# 缩放
dk = q.size()[-1]
scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32, device=q.device))
# 加上 mask
if mask is not None:
# 在 mask==1 的位置加上 -1e9,使 softmax 后趋近于0
scaled_attention_logits = scaled_attention_logits.masked_fill(mask == 1, -1e9)
# softmax 得到注意力权重
attention_weights = F.softmax(scaled_attention_logits, dim=-1)
# 加权求和
output = torch.matmul(attention_weights, v)
return output, attention_weights
class MultiHeadAttention(nn.Module):
"""
PyTorch 版 MHA,与 Keras 版本对应:
q -> WQ -> 分头
k -> WK -> 分头
v -> WV -> 分头
计算 scaled dot-product attention
合并 -> 线性层
期望输入形状:
q, k, v: [B, L, d_model]
"""
def __init__(self, d_model: int, num_heads: int):
super().__init__()
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.depth = d_model // num_heads # 每个头的维度 Dh
# 对应 Keras 的 Dense(d_model)
self.WQ = nn.Linear(d_model, d_model, bias=True)
self.WK = nn.Linear(d_model, d_model, bias=True)
self.WV = nn.Linear(d_model, d_model, bias=True)
self.out_proj = nn.Linear(d_model, d_model, bias=True)
def _split_heads(self, x: torch.Tensor):
"""
x: [B, L, d_model] -> [B, num_heads, L, depth]
"""
B, L, _ = x.shape
x = x.view(B, L, self.num_heads, self.depth) # [B, L, H, Dh]
x = x.permute(0, 2, 1, 3).contiguous() # [B, H, L, Dh]
return x
def _combine_heads(self, x: torch.Tensor):
"""
x: [B, num_heads, L, depth] -> [B, L, d_model]
"""
B, H, L, Dh = x.shape
x = x.permute(0, 2, 1, 3).contiguous() # [B, L, H, Dh]
x = x.view(B, L, H * Dh) # [B, L, d_model]
return x
def forward(self, q, k, v, mask=None, return_attn: bool = True):
"""
q, k, v: [B, Lq/Lk/Lv, d_model]
mask: 期望形状为 [B, 1, Lq, Lk] 或 [B, Lq, Lk];值为1表示屏蔽,0表示保留
return:
output: [B, Lq, d_model]
attention_weights (可选): [B, num_heads, Lq, Lk]
"""
B = q.size(0)
# 线性映射
q = self.WQ(q) # [B, Lq, d_model]
k = self.WK(k) # [B, Lk, d_model]
v = self.WV(v) # [B, Lv, d_model]
# 分头
q = self._split_heads(q) # [B, H, Lq, Dh]
k = self._split_heads(k) # [B, H, Lk, Dh]
v = self._split_heads(v) # [B, H, Lv, Dh]
# 处理 mask:广播到 [B, H, Lq, Lk]
if mask is not None:
# 允许 [B, 1, Lq, Lk] 或 [B, Lq, Lk]
if mask.dim() == 3:
mask = mask.unsqueeze(1) # [B,1,Lq,Lk]
elif mask.dim() == 4 and mask.size(1) == 1:
pass # 已是 [B,1,Lq,Lk]
else:
raise ValueError("mask 形状需为 [B, Lq, Lk] 或 [B, 1, Lq, Lk]")
mask = mask.expand(B, self.num_heads, mask.size(-2), mask.size(-1))
# 注意力
attn_out, attn_weights = scaled_dot_product_attention(q, k, v, mask) # [B,H,Lq,Dh], [B,H,Lq,Lk]
# 合并头
attn_out = self._combine_heads(attn_out) # [B, Lq, d_model]
# 输出线性层
output = self.out_proj(attn_out) # [B, Lq, d_model]
if return_attn:
return output, attn_weights
return output
def feed_forward_network(d_model, dff):
"""
前馈网络 FFN
Args:
d_model: 输出维度 (embedding 维度)
dff: 内部隐层维度 (feed-forward 网络的中间层大小)
Returns:
nn.Sequential 模型
"""
return nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
class EncoderLayer(nn.Module):
"""
x -> self-attention -> add & norm & dropout
-> feed-forward -> add & norm & dropout
期望输入:
x: [B, L, d_model]
src_mask: [B, 1, L, L] 或 [B, L, L],其中 1 表示屏蔽,0 表示保留
"""
def __init__(self, d_model: int, num_heads: int, dff: int, rate: float = 0.1):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads) # 前面已实现
self.ffn = feed_forward_network(d_model, dff) # 前面已实现
self.norm1 = nn.LayerNorm(d_model, eps=1e-6)
self.norm2 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(rate)
self.dropout2 = nn.Dropout(rate)
def forward(self, x: torch.Tensor, src_mask: torch.Tensor = None):
"""
返回:
out: [B, L, d_model]
"""
# Self-Attention
attn_out, _ = self.mha(x, x, x, mask=src_mask) # [B, L, d_model], [B, H, L, L]
attn_out = self.dropout1(attn_out) # 训练模式下生效
out1 = self.norm1(x + attn_out) # 残差 + LayerNorm
# Feed Forward
ffn_out = self.ffn(out1) # [B, L, d_model]
ffn_out = self.dropout2(ffn_out)
out2 = self.norm2(out1 + ffn_out)
return out2
class DecoderLayer(nn.Module):
"""
x -> masked self-attention -> add & norm & dropout -> out1
out1, enc_out -> cross-attention -> add & norm & dropout -> out2
out2 -> FFN -> add & norm & dropout -> out3
期望输入:
x: [B, L_tgt, d_model]
enc_out: [B, L_src, d_model]
tgt_mask: [B, 1, L_tgt, L_tgt] 或 [B, L_tgt, L_tgt] (look-ahead + padding 的合并掩码,1=屏蔽)
enc_dec_mask: [B, 1, L_tgt, L_src] 或 [B, L_tgt, L_src] (decoder 对 encoder 的 padding 掩码,1=屏蔽)
"""
def __init__(self, d_model: int, num_heads: int, dff: int, rate: float = 0.1):
super().__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads) # masked self-attn
self.mha2 = MultiHeadAttention(d_model, num_heads) # cross-attn
self.ffn = feed_forward_network(d_model, dff)
self.norm1 = nn.LayerNorm(d_model, eps=1e-6)
self.norm2 = nn.LayerNorm(d_model, eps=1e-6)
self.norm3 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(rate)
self.dropout2 = nn.Dropout(rate)
self.dropout3 = nn.Dropout(rate)
def forward(
self,
x: torch.Tensor,
enc_out: torch.Tensor,
tgt_mask: torch.Tensor = None,
enc_dec_mask: torch.Tensor = None,
):
# 1) Masked Self-Attention (decoder 自注意力,使用 look-ahead+padding 的合并 mask)
attn1_out, attn_weights1 = self.mha1(x, x, x, mask=tgt_mask) # [B,Lt,D], [B,H,Lt,Lt]
attn1_out = self.dropout1(attn1_out)
out1 = self.norm1(x + attn1_out)
# 2) Cross-Attention (query=out1, key/value=enc_out),使用 encoder padding 掩码
attn2_out, attn_weights2 = self.mha2(out1, enc_out, enc_out, mask=enc_dec_mask) # [B,Lt,D], [B,H,Lt,Ls]
attn2_out = self.dropout2(attn2_out)
out2 = self.norm2(out1 + attn2_out)
# 3) FFN
ffn_out = self.ffn(out2) # [B,Lt,D]
ffn_out = self.dropout3(ffn_out)
out3 = self.norm3(out2 + ffn_out) # [B,Lt,D]
return out3, attn_weights1, attn_weights2
class EncoderModel(nn.Module):
def __init__(self, num_layers: int, input_vocab_size: int, max_length: int,
d_model: int, num_heads: int, dff: int, rate: float = 0.1,
padding_idx: int = None):
"""
参数与 Keras 版本对齐;额外提供 padding_idx 以便 Embedding 忽略 pad 的梯度。
"""
super().__init__()
self.d_model = d_model
self.num_layers = num_layers
self.max_length = max_length
# Embedding
self.embedding = nn.Embedding(input_vocab_size, d_model, padding_idx=padding_idx)
# 位置编码:注册为 buffer(不参与训练/优化器)
pe = get_position_embedding(max_length, d_model) # [1, max_len, d_model]
self.register_buffer("position_embedding", pe, persistent=False)
self.dropout = nn.Dropout(rate)
# 堆叠 EncoderLayer(前面我们已实现过)
self.encoder_layers = nn.ModuleList(
[EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
)
# 预存缩放因子
self.scale = math.sqrt(d_model)
def forward(self, x: torch.Tensor, src_mask: torch.Tensor = None):
"""
x: [B, L] (token ids)
src_mask: [B, 1, L, L] 或 [B, L, L],1=屏蔽,0=保留(与前文一致)
return: 编码结果 [B, L, d_model]
"""
B, L = x.shape
# 等价于 tf.debugging.assert_less_equal
if L > self.max_length:
raise ValueError(f"input_seq_len ({L}) should be ≤ max_length ({self.max_length})")
# [B, L, D]
x = self.embedding(x)
# 缩放:使 embedding 的尺度与位置编码相近(论文做法)
x = x * self.scale
# 加位置编码(按实际序列长度切片)
x = x + self.position_embedding[:, :L, :]
x = self.dropout(x)
# 逐层 Encoder
for layer in self.encoder_layers:
x = layer(x, src_mask)
return x
class DecoderModel(nn.Module):
"""
x -> masked self-attn -> add & norm & dropout
-> cross-attn(enc_out) -> add & norm & dropout
-> FFN -> add & norm & dropout
"""
def __init__(self, num_layers: int, target_vocab_size: int, max_length: int,
d_model: int, num_heads: int, dff: int, rate: float = 0.1,
padding_idx: int = None):
super().__init__()
self.num_layers = num_layers
self.max_length = max_length
self.d_model = d_model
# 词嵌入
self.embedding = nn.Embedding(target_vocab_size, d_model, padding_idx=padding_idx)
# 位置编码(注册为 buffer,不参与训练)
pe = get_position_embedding(max_length, d_model)
self.register_buffer("position_embedding", pe, persistent=False)
self.dropout = nn.Dropout(rate)
# 堆叠解码层
self.decoder_layers = nn.ModuleList(
[DecoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers)]
)
self.scale = math.sqrt(d_model)
def forward(
self,
x: torch.Tensor, # [B, L_tgt] 目标端 token ids
enc_out: torch.Tensor, # [B, L_src, D] 编码器输出
tgt_mask: torch.Tensor = None, # [B, 1, L_tgt, L_tgt] 或 [B, L_tgt, L_tgt](look-ahead+padding)
enc_dec_mask: torch.Tensor = None, # [B, 1, L_tgt, L_src] 或 [B, L_tgt, L_src](对 encoder 的 padding)
):
B, Lt = x.shape
if Lt > self.max_length:
raise ValueError(f"output_seq_len ({Lt}) should be ≤ max_length ({self.max_length})")
# (B, Lt, D)
x = self.embedding(x) * self.scale
x = x + self.position_embedding[:, :Lt, :]
x = self.dropout(x)
attention_weights = {}
for i, layer in enumerate(self.decoder_layers, start=1):
x, attn1, attn2 = layer(x, enc_out, tgt_mask=tgt_mask, enc_dec_mask=enc_dec_mask)
attention_weights[f"decoder_layer{i}_att1"] = attn1 # [B, H, Lt, Lt]
attention_weights[f"decoder_layer{i}_att2"] = attn2 # [B, H, Lt, Ls]
# x: (B, Lt, D)
return x, attention_weights
class Transformer(nn.Module):
def __init__(self, num_layers, input_vocab_size, target_vocab_size,
max_length, d_model, num_heads, dff, rate=0.1,
src_padding_idx: int = None, tgt_padding_idx: int = None):
super().__init__()
self.encoder_model = EncoderModel(
num_layers=num_layers,
input_vocab_size=input_vocab_size,
max_length=max_length,
d_model=d_model,
num_heads=num_heads,
dff=dff,
rate=rate,
padding_idx=src_padding_idx,
)
self.decoder_model = DecoderModel(
num_layers=num_layers,
target_vocab_size=target_vocab_size,
max_length=max_length,
d_model=d_model,
num_heads=num_heads,
dff=dff,
rate=rate,
padding_idx=tgt_padding_idx,
)
# 等价于 Keras 的 Dense(target_vocab_size)
self.final_layer = nn.Linear(d_model, target_vocab_size)
def forward(self, inp_ids, tgt_ids, src_mask=None, tgt_mask=None, enc_dec_mask=None):
"""
inp_ids: [B, L_src] 源端 token ids
tgt_ids: [B, L_tgt] 目标端 token ids(训练时通常是 shift 后的 decoder 输入)
src_mask: [B, 1, L_src, L_src] 或 [B, L_src, L_src](1=屏蔽)
tgt_mask: [B, 1, L_tgt, L_tgt] 或 [B, L_tgt, L_tgt](look-ahead+padding)
enc_dec_mask:[B, 1, L_tgt, L_src] 或 [B, L_tgt, L_src]
返回:
logits: [B, L_tgt, target_vocab_size]
attention_weights: dict,包含每层的 attn
"""
enc_out = self.encoder_model(inp_ids, src_mask=src_mask) # [B, L_src, D]
dec_out, attention_weights = self.decoder_model(
tgt_ids, enc_out, tgt_mask=tgt_mask, enc_dec_mask=enc_dec_mask
) # [B, L_tgt, D], dict
logits = self.final_layer(dec_out) # [B, L_tgt, V_tgt]
return logits, attention_weights
class CustomizedSchedule(_LRScheduler):
"""
Noam / Transformer LR:
lr = d_model**(-0.5) * min(step**(-0.5), step * warmup_steps**(-1.5))
"""
def __init__(self, optimizer, d_model, warmup_steps=4000, last_epoch=-1):
self.d_model = float(d_model)
self.warmup_steps = float(warmup_steps)
super().__init__(optimizer, last_epoch)
def get_lr(self):
step = max(1, self.last_epoch + 1) # 确保从 1 开始
scale = self.d_model ** -0.5
arg1 = step ** -0.5
arg2 = step * (self.warmup_steps ** -1.5)
lr = scale * min(arg1, arg2)
return [lr for _ in self.base_lrs]
def plot_customized_lr_curve(optimizer, scheduler, total_steps: int, label: str = None):
"""
绘制学习率曲线(支持传入已有 optimizer 和 scheduler)
Args:
optimizer (torch.optim.Optimizer): 优化器
scheduler (torch.optim.lr_scheduler._LRScheduler): 学习率调度器
total_steps (int): 总训练步数
label (str): 图例标签,默认使用 scheduler 配置
"""
lrs = []
for step in range(total_steps):
scheduler.step()
lr = scheduler.get_last_lr()[0]
lrs.append(lr)
# 绘制曲线
plt.figure(figsize=(8, 4))
plt.plot(range(1, total_steps + 1), lrs, label=label or "LR Curve")
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")
plt.title("Learning Rate Schedule")
plt.legend()
plt.grid(True)
plt.show()
def loss_function(real, pred):
"""
Args:
real: (B, L) target ids (shift 后)
pred: (B, L, V) logits
Returns:
loss (float): 平均有效 token 的交叉熵损失
"""
B, L, V = pred.shape
# 展平
pred = pred.reshape(-1, V) # (B*L, V)
real = real.reshape(-1) # (B*L,)
# token 级别交叉熵 (padding 已被 ignore_index 屏蔽)
loss_ = loss_object(pred, real) # (B*L,)
# # 统计有效 token
# valid = (real != PAD_ID_TGT).float()
# # 均值损失(只对有效 token 求平均)
# loss = (loss_ * valid).sum() / valid.sum()
return loss_.mean()
def create_masks(
inp_ids: torch.Tensor, # [B, L_src]
tar_ids: torch.Tensor, # [B, L_tgt] —— 通常是 decoder 输入(已左移)
src_pad_id: int = 0,
tgt_pad_id: int = 0,
):
"""
返回:
encoder_padding_mask : [B, 1, 1, L_src] (给 EncoderLayer self-attn)
decoder_mask (LA + padding) : [B, 1, L_tgt, L_tgt] (给 DecoderLayer 自注意力)
encoder_decoder_padding_mask : [B, 1, 1, L_src] (给 DecoderLayer cross-attn)
语义:
1 = 屏蔽(masked),0 = 保留
"""
# 1) Encoder 端 padding mask
encoder_padding_mask = create_padding_mask(inp_ids, pad_token_id=src_pad_id) # [B,1,1,L_src]
encoder_decoder_padding_mask = create_padding_mask(inp_ids, pad_token_id=src_pad_id) # [B,1,1,L_src]
# 2) Decoder 端 look-ahead + padding 合并
B, L_tgt = tar_ids.size(0), tar_ids.size(1)
# [L_tgt, L_tgt] → [1,1,L_tgt,L_tgt],放到与输入相同 device/dtype
look_ahead = create_look_ahead_mask(L_tgt).to(
device=tar_ids.device, dtype=encoder_padding_mask.dtype
).unsqueeze(0).unsqueeze(1) # [1,1,L_tgt,L_tgt]
# 目标端 padding: [B,1,1,L_tgt] → 扩到 [B,1,L_tgt,L_tgt]
decoder_padding_mask = create_padding_mask(tar_ids, pad_token_id=tgt_pad_id) # [B,1,1,L_tgt]
decoder_padding_mask = decoder_padding_mask.expand(-1, -1, L_tgt, -1) # [B,1,L_tgt,L_tgt]
# 合并(任一为 1 即屏蔽)
decoder_mask = torch.maximum(decoder_padding_mask, look_ahead) # [B,1,L_tgt,L_tgt]
return encoder_padding_mask, decoder_mask, encoder_decoder_padding_mask
@torch.no_grad()
def token_accuracy(real, pred, pad_id):
pred_ids = pred.argmax(dim=-1) # (B, L)
mask = (real != pad_id)
correct = ((pred_ids == real) & mask).sum().item()
denom = mask.sum().item()
return correct / max(1, denom)
class AverageMeter:
def __init__(self, name="meter"): self.name = name; self.reset()
def reset(self): self.sum = 0.0; self.n = 0
def update(self, val, count=1): self.sum += float(val) * count; self.n += count
@property
def avg(self): return self.sum / max(1, self.n)
def train_step(batch, transformer, optimizer, scheduler=None, device=None):
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
transformer.train()
inp = batch["pt_input_ids"].to(device)
tar = batch["en_input_ids"].to(device)
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
SRC_PAD_ID = pt_tokenizer.pad_token_id
TGT_PAD_ID = en_tokenizer.pad_token_id
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
inp, tar_inp, src_pad_id=SRC_PAD_ID, tgt_pad_id=TGT_PAD_ID
)
enc_dec_mask = enc_dec_pad_mask.expand(-1, 1, tar_inp.size(1), -1)
logits, _ = transformer(
inp, tar_inp,
src_mask=enc_pad_mask,
tgt_mask=dec_mask,
enc_dec_mask=enc_dec_mask
)
loss = loss_function(tar_real, logits)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(transformer.parameters(), max_norm=1.0)
optimizer.step()
if scheduler is not None:
scheduler.step()
acc = token_accuracy(tar_real, logits, pad_id=TGT_PAD_ID)
return loss.item(), acc
def train_model(
epochs: int,
model: torch.nn.Module,
optimizer: torch.optim.Optimizer,
train_loader: torch.utils.data.DataLoader,
val_loader: torch.utils.data.DataLoader,
scheduler=None,
device: str = None,
log_every: int = 100,
ckpt_dir: str = "checkpoints",
ckpt_prefix: str = "ckpt",
):
os.makedirs(ckpt_dir, exist_ok=True)
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
train_loss_meter = AverageMeter("train_loss")
train_acc_meter = AverageMeter("train_accuracy")
global_step = 0
for epoch in range(epochs):
try:
start = time.time()
train_loss_meter.reset()
train_acc_meter.reset()
model.train()
for batch_idx, batch in enumerate(train_loader):
loss_val, acc_val = train_step(
batch=batch, transformer=model, optimizer=optimizer, scheduler=scheduler, device=device
)
train_loss_meter.update(loss_val, 1)
train_acc_meter.update(acc_val, 1)
global_step += 1
if batch_idx % log_every == 0:
print(
f"Epoch {epoch+1} Batch {batch_idx} "
f"Loss {train_loss_meter.avg:.4f} Accuracy {train_acc_meter.avg:.4f}"
)
save_ckpt(
model=model,
optimizer=optimizer,
scheduler=scheduler,
epoch=epoch+1,
step=global_step,
ckpt_dir=ckpt_dir,
tag="latest"
)
print(f"Epoch {epoch+1} Loss {train_loss_meter.avg:.4f} Accuracy {train_acc_meter.avg:.4f}")
print(f"Time taken for 1 epoch: {time.time() - start:.2f} secs\n")
# 每个epoch结束后进行验证集评测
validate_loss, validate_acc = evaluate_on_val(model, val_loader, device)
print(f"Validation - Epoch {epoch+1} Loss: {validate_loss:.4f}, Accuracy: {validate_acc:.4f}\n")
except Exception as e:
print(f"报错啦!!! 报错信息: {e}")
save_ckpt(
model=model,
optimizer=optimizer,
scheduler=scheduler,
epoch=epoch,
step=global_step,
tag="error"
)
@torch.no_grad()
def evaluate(
inp_sentence: str,
transformer: Transformer,
pt_tokenizer,
en_tokenizer,
max_length: int,
device: str = None):
"""
inp_sentence: 输入的源语言字符串 (pt)
transformer: 已训练的 Transformer
pt_tokenizer, en_tokenizer: 分别是葡萄牙语和英语 tokenizer
max_length: 最大生成长度
"""
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
transformer.eval()
transformer.to(device)
# 1. 编码输入,加 <s> 和 </s>
inp_ids = encode_with_bos_eos(pt_tokenizer, inp_sentence)
encoder_input = torch.tensor(inp_ids, dtype=torch.long, device=device).unsqueeze(0) # (1, Ls)
# 2. decoder 起始符 <s>
start_id = en_tokenizer.bos_token_id
end_id = en_tokenizer.eos_token_id
decoder_input = torch.tensor([[start_id]], dtype=torch.long, device=device) # (1, 1)
# 3. 循环预测
attention_weights = {}
for _ in range(max_length):
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
encoder_input, decoder_input,
src_pad_id=pt_tokenizer.pad_token_id,
tgt_pad_id=en_tokenizer.pad_token_id,
)
enc_dec_mask = enc_dec_pad_mask.expand(-1, 1, decoder_input.size(1), -1)
logits, attn = transformer(
encoder_input, decoder_input,
src_mask=enc_pad_mask,
tgt_mask=dec_mask,
enc_dec_mask=enc_dec_mask,
)
# 取最后一步预测
next_token_logits = logits[:, -1, :] # (1, V)
predicted_id = torch.argmax(next_token_logits, dim=-1) # (1,)
if predicted_id.item() == end_id:
break
# 拼接到 decoder_input
decoder_input = torch.cat(
[decoder_input, predicted_id.unsqueeze(0)], dim=-1
) # (1, Lt+1)
attention_weights = attn
return decoder_input.squeeze(0).tolist(), attention_weights
@torch.no_grad()
def evaluate_on_val(model, val_loader, device):
model.eval()
total_loss = 0
total_acc = 0
total_count = 0
for batch in val_loader:
inp = batch["pt_input_ids"].to(device)
tar = batch["en_input_ids"].to(device)
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
enc_pad_mask, dec_mask, enc_dec_pad_mask = create_masks(
inp, tar_inp, src_pad_id=pt_tokenizer.pad_token_id, tgt_pad_id=en_tokenizer.pad_token_id
)
enc_dec_mask = enc_dec_pad_mask.expand(-1, 1, tar_inp.size(1), -1)
logits, _ = model(
inp, tar_inp,
src_mask=enc_pad_mask,
tgt_mask=dec_mask,
enc_dec_mask=enc_dec_mask
)
loss = loss_function(tar_real, logits)
acc = token_accuracy(tar_real, logits, pad_id=en_tokenizer.pad_token_id)
total_loss += loss.item() * inp.size(0)
total_acc += acc * inp.size(0)
total_count += inp.size(0)
avg_loss = total_loss / total_count
avg_acc = total_acc / total_count
return avg_loss, avg_acc
def plot_encoder_decoder_attention(attention, input_sentence, result, layer_name):
"""
attention: 来自 forward 返回的 attention_weights dict
形状 [B, num_heads, tgt_len, src_len]
input_sentence: 源语言字符串
result: 目标句子 token id 列表 (decoder 输出)
layer_name: 指定可视化的层 key,比如 "decoder_layer1_att2"
"""
fig = plt.figure(figsize=(16, 8))
# 源句子编码
input_id_sentence = pt_tokenizer.encode(input_sentence, add_special_tokens=False)
# 取 batch 维度 squeeze,并转 numpy
attn = attention[layer_name].squeeze(0) # [num_heads, tgt_len, src_len]
attn = attn.detach().cpu().numpy()
for head in range(attn.shape[0]):
ax = fig.add_subplot(2, 4, head + 1)
# 只取 result[:-1] 的注意力 (去掉最后 <eos>)
ax.matshow(attn[head][:-1, :], cmap="viridis")
fontdict = {"fontsize": 10}
# X 轴: 输入 token (<s> + sentence + </s>)
ax.set_xticks(range(len(input_id_sentence) + 2))
ax.set_xticklabels(
["<s>"] + [pt_tokenizer.decode([i]) for i in input_id_sentence] + ["</s>"],
fontdict=fontdict, rotation=90,
)
# Y 轴: decoder 输出 token
ax.set_yticks(range(len(result)))
ax.set_yticklabels(
[en_tokenizer.decode([i]) for i in result if i < en_tokenizer.vocab_size],
fontdict=fontdict,
)
ax.set_ylim(len(result) - 1.5, -0.5)
ax.set_xlabel(f"Head {head+1}")
plt.tight_layout()
plt.show()
def translate(input_sentence, transformer, pt_tokenizer, en_tokenizer,
max_length=64, device=None, layer_name=""):
# 调用我们改好的 evaluate (PyTorch 版)
result, attention_weights = evaluate(
inp_sentence=input_sentence,
transformer=transformer,
pt_tokenizer=pt_tokenizer,
en_tokenizer=en_tokenizer,
max_length=max_length,
device=device,
)
# 把 token id 转回句子
predicted_sentence = en_tokenizer.decode(
[i for i in result if i < en_tokenizer.vocab_size],
skip_special_tokens=True
)
print("Input: {}".format(input_sentence))
print(f"Predicted translation: {predicted_sentence}")
# 如果传入了 layer_name,就画注意力图
if layer_name:
plot_encoder_decoder_attention(
attention_weights,
input_sentence,
result,
layer_name
)
return predicted_sentence
def save_ckpt(model, optimizer, scheduler, epoch, step, ckpt_dir="checkpoints", tag="latest"):
"""
保存 checkpoint
Args:
model: nn.Module
optimizer: torch.optim
scheduler: torch.optim.lr_scheduler (可选)
epoch: 当前 epoch
step: 全局 step
ckpt_dir: 保存目录
tag: 保存标识 ("latest", "error", "custom" 等)
"""
os.makedirs(ckpt_dir, exist_ok=True)
ckpt = {
"epoch": epoch,
"step": step,
"model": model.state_dict(),
"optim": optimizer.state_dict(),
"sched": scheduler.state_dict() if scheduler else None,
}
latest_path = os.path.join(ckpt_dir, "latest.pt")
torch.save(ckpt, latest_path)
# print(f"✅ checkpoint updated: {latest_path}")
# 1. 默认保存 latest
if tag == "latest":
path = os.path.join(ckpt_dir, f"mid_e{epoch}_s{step}.pt")
elif tag == "error":
# 避免覆盖,用时间戳
ts = datetime.now().strftime("%Y%m%d_%H%M%S")
path = os.path.join(ckpt_dir, f"error_e{epoch}_s{step}_{ts}.pt")
else:
path = os.path.join(ckpt_dir, f"{tag}_e{epoch}_s{step}.pt")
torch.save(ckpt, path)
# print(f"✅ checkpoint saved: {path}")
return path
def load_ckpt(model, optimizer=None, scheduler=None, ckpt_dir="checkpoints", device="cpu"):
"""
加载最新 checkpoint
"""
latest = os.path.join(ckpt_dir, "latest.pt")
if not os.path.exists(latest):
print("⚠️ No checkpoint found, training from scratch.")
return 0, 0
ckpt = torch.load(latest, map_location=device)
model.load_state_dict(ckpt["model"])
if optimizer: optimizer.load_state_dict(ckpt["optim"])
if scheduler and ckpt["sched"]: scheduler.load_state_dict(ckpt["sched"])
print(f"✅ checkpoint loaded (epoch={ckpt['epoch']}, step={ckpt['step']})")
return ckpt["epoch"], ckpt["step"]
if __name__ == "__main__":
# 0. 常量定义
# 数据文件地址
train_path = "/home/nijiahui/Datas/por_eng_csv/por_en_train.csv"
val_path = "/home/nijiahui/Datas/por_eng_csv/por_en_test.csv"
special_tokens = ["<s>", "<pad>", "</s>", "<unk>", "<mask>"]
checkpoint_dir = './checkpoints-tmp22'
src_lang = "pt"
tgt_lang = "en"
# 构建词表参数
vocab_size = 2**13 # 词表大小
min_freq = 2 # 最小词频
special_tokens=special_tokens # 特殊符号
max_length = 128 # 最大序列长度
# 模型训练超参数
batch_size = 32 # 批处理数
# warmup_steps = 4000 # warmup steps数
epochs = 60 # 训练轮数
# learning_rate = 1.0 # 学习率
# betas = (0.9, 0.98) # Adam 的一阶矩(梯度均值);二阶矩(梯度平方的均值)
# eps = 1e-9 # 防止除零错误的小常数
learning_rate = 5e-4
betas = (0.9, 0.98)
eps = 1e-8
weight_decay = 1e-6 # L2正则化((权重衰减)) - 0.01
# 模型结构
# num_layers = 8
# d_model = 512 # hidden-size
# dff = 2048
# num_heads = 8
# dropout_rate = 0.1
num_layers = 4
d_model = 128 # hidden-size
dff = 512
num_heads = 8
dropout_rate = 0.2
# 1. 检查 PyTorch 环境信息、GPU 状态,以及常用依赖库版本;
device = check_env()
print("实际使用设备:", device)
# 2. 加载葡萄牙语-英语翻译数据集
train_dataset, val_dataset = load_translation_dataset(
train_path=train_path,
val_path=val_path,
src_lang=src_lang, # 源语言
tgt_lang=tgt_lang # 目标语言
)
print("训练集样本数:", len(train_dataset))
print("验证集样本数:", len(val_dataset))
# 3. 构建 Tokenizer
# 3.1 构建 Tokenizer
print("开始构建 Tokenizer...")
src_tokenizer, tgt_tokenizer = train_and_load_tokenizers(
train_dataset=train_dataset, # 数据集
src_lang=src_lang,
tgt_lang=tgt_lang,
vocab_size=vocab_size, # 词表大小
min_freq=min_freq, # 最小词频
special_tokens=special_tokens, # 特殊符号
save_dir_src=f"tok_{src_lang}", # 保存目录
save_dir_tgt=f"tok_{tgt_lang}", # 保存目录
max_length=max_length # 最大序列长度
)
# 3.2 【测试】 Tokenizer 代码
test_tokenizers(
src_tokenizer=src_tokenizer,
tgt_tokenizer=tgt_tokenizer,
dataset=train_dataset,
src_lang=src_lang,
tgt_lang=tgt_lang,
num_samples=1
)
# 3.3 构建 batch data loader
print("开始构建 batch data loader...")
train_loader, val_loader = build_dataloaders(
train_dataset=train_dataset,
val_dataset=val_dataset,
src_tokenizer=src_tokenizer, # 源语言分词器
tgt_tokenizer=tgt_tokenizer, # 目标语言分词器
src_lang=src_lang, # 源语言字段名
tgt_lang=tgt_lang, # 目标语言字段名
batch_size=64,
max_length=48,
num_workers=0,
shuffle_train=True
)
# 3.4 【测试】 batch data loader
test_dataloaders(
train_loader,
val_loader,
src_lang=src_lang,
tgt_lang=tgt_lang
)
# 4. 【测试】位置编码 - 打印位置编码矩阵图形
position_embedding = get_position_embedding(max_length, d_model)
plot_position_embedding(position_embedding)
# 5. 构建 model 模型 Transformer 结构
input_vocab_size = pt_tokenizer.vocab_size
target_vocab_size = en_tokenizer.vocab_size
model = Transformer(
num_layers=num_layers,
input_vocab_size=input_vocab_size,
target_vocab_size=target_vocab_size,
max_length=max_length,
d_model=d_model,
num_heads=num_heads,
dff=dff,
rate=dropout_rate,
src_padding_idx=pt_tokenizer.pad_token_id if hasattr(pt_tokenizer, "pad_token_id") else None,
tgt_padding_idx=en_tokenizer.pad_token_id if hasattr(en_tokenizer, "pad_token_id") else None,
)
##############################【Test - optimizer | scheduler 】##############################
# # 6. 自定义学习率和优化器
# optimizer = optim.Adam(model.parameters(),
# lr=learning_rate,
# betas=betas,
# eps=eps)
# # 自定义学习率
# scheduler = CustomizedSchedule(optimizer, d_model=d_model, warmup_steps=warmup_steps)
# 6. 自定义学习率和优化器
num_training_steps = len(train_loader2) * epochs
optimizer = optim.AdamW(
model.parameters(),
lr=learning_rate,
betas=betas,
eps=eps,
weight_decay=weight_decay
)
warmup_steps = int(0.1 * num_training_steps) # 10% 步数用作 warmup
scheduler = CustomizedSchedule(optimizer, d_model=d_model, warmup_steps=warmup_steps)
# 自定义学习率
# num_training_steps = len(train_loader2) * epochs
# # scheduler = optim.lr_scheduler.CosineAnnealingLR(
# # optimizer,
# # T_max=num_training_steps,
# # eta_min=1e-6
# # )
# # 设置 warmup steps
# warmup_steps = int(0.1 * num_training_steps) # 10% 步数用作 warmup
# scheduler = get_cosine_schedule_with_warmup(
# optimizer,
# num_warmup_steps=warmup_steps,
# num_training_steps=num_training_steps,
# )
# 6.2 【测试】 打印自定义学习率曲线
plot_customized_lr_curve(optimizer, scheduler, total_steps=num_training_steps, label=f"d_model={d_model}, warmup={warmup_steps}")
##############################【Test - optimizer | scheduler 】##############################
# 7. 自定义损失函数
# PyTorch 的 CrossEntropyLoss 默认就支持 from_logits=True
PAD_ID_TGT = en_tokenizer.pad_token_id
loss_object = nn.CrossEntropyLoss(reduction="none", ignore_index=PAD_ID_TGT)
# 8. 训练模型 && checkpoints
print(f"learning_rate:{learning_rate}")
if not os.path.exists(checkpoint_dir):
os.mkdir(checkpoint_dir)
train_model(
epochs=epochs,
model=model,
optimizer=optimizer,
train_loader=train_loader2,
val_loader=val_loader2,
scheduler=scheduler, # Noam 调度
device=device, # 自动选 GPU/CPU
log_every=100,
ckpt_dir="checkpoints",
ckpt_prefix="transformer",
)
else:
start_epoch, global_step = load_ckpt(model, optimizer, scheduler, device=device)
print("Checkpoint loaded successfully!")



















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









