







基础知识
0 前言
我之前看transformer的论文《Attention Is All You Need》,根本看不懂,特别是QKV注意力机制那部分。后面在知乎上看到名为“看图学”的博主的一篇回答,按他回答阅读了一些论文,搞明白了 transformer 中的注意力机制的发展演变,才对 transformer 中的注意力机制有了了解,在此向他表示感谢!本文并不是面对零基础的同学,在学习这篇文章之间,需要知道什么是RNN、LSTM、GRU,什么是词嵌入。
1 EncoderDecoder
Transformer最初是用于机器翻译的,它的编码器-解码器结构最初来源于《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》这篇论文。在这篇文章中,Kyunghyun Cho等人提出了基于编码器和解码器的模型(RNN Encoder-Decoder)用于机器翻译,其网络结构如下图所示:
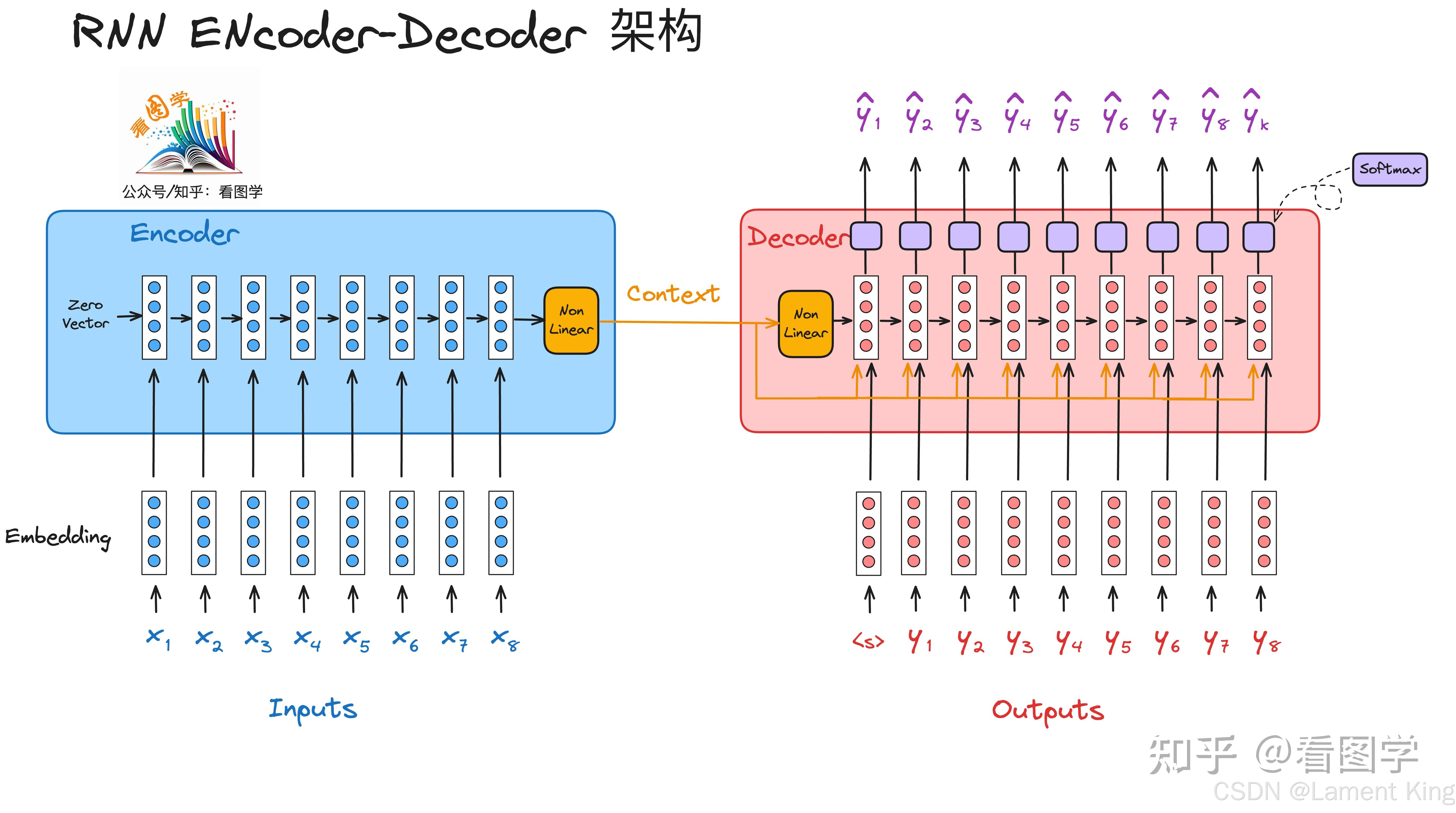
编码器的计算过程为(为了方便理解,我们省略了词嵌入过程,本文的后续内容也省略词嵌入):
h
0
=
0
h
j
=
RNN
G
R
U
(
h
j
−
1
,
x
j
)
c
=
tanh
(
V
⋅
h
T
)
\begin{array}{l} \begin{aligned} h_{0} & =\mathbf{0} \\ h_{j} & =\operatorname{RNN}_{G R U}\left(h_{j-1}, x_{j}\right) \\ c & =\tanh \left(V \cdot h_{T}\right) \end{aligned}\\ \end{array}
h0hjc=0=RNNGRU(hj−1,xj)=tanh(V⋅hT)
这里
T
T
T 是encoder中输入单词的个数,
h
T
h_T
hT 是最后一个单词输入RNN后获得的输出。
解码器的计算过程:
s
0
=
tanh
(
V
′
⋅
c
)
s
t
=
RNN
G
R
U
(
s
t
−
1
,
[
y
t
−
1
;
C
]
)
P
(
y
t
)
=
softmax
(
MLP
(
s
t
)
)
\begin{array}{l} \begin{aligned} s_{0} & =\tanh \left(V^{\prime} \cdot c\right) \\ s_{t} & =\operatorname{RNN}_{G R U}\left(s_{t-1},\left[y_{t-1} ; C\right]\right) \\ P(y_{t}) & =\operatorname{softmax}\left(\operatorname{MLP}\left(s_{t}\right)\right) \end{aligned} \end{array}
s0stP(yt)=tanh(V′⋅c)=RNNGRU(st−1,[yt−1;C])=softmax(MLP(st))
这里 V ′ V^{\prime} V′ 是一个可训练的矩阵, c c c 是来自encoder的上下文向量(context vector), s t − 1 s_{t-1} st−1是decoder中来自上一时步的隐藏层输出, P ( y t ) P(y_{t}) P(yt)是第 t t t 时步输出单词的分布。
编码器输出第
t
{t}
t 个单词的分布,可以简写为:
P
(
y
t
)
=
g
(
y
t
−
1
,
s
t
−
1
,
c
)
P(y_{t}) =g(y_{t-1}, s_{t-1}, c)
P(yt)=g(yt−1,st−1,c)
2 Bahdanau Attention
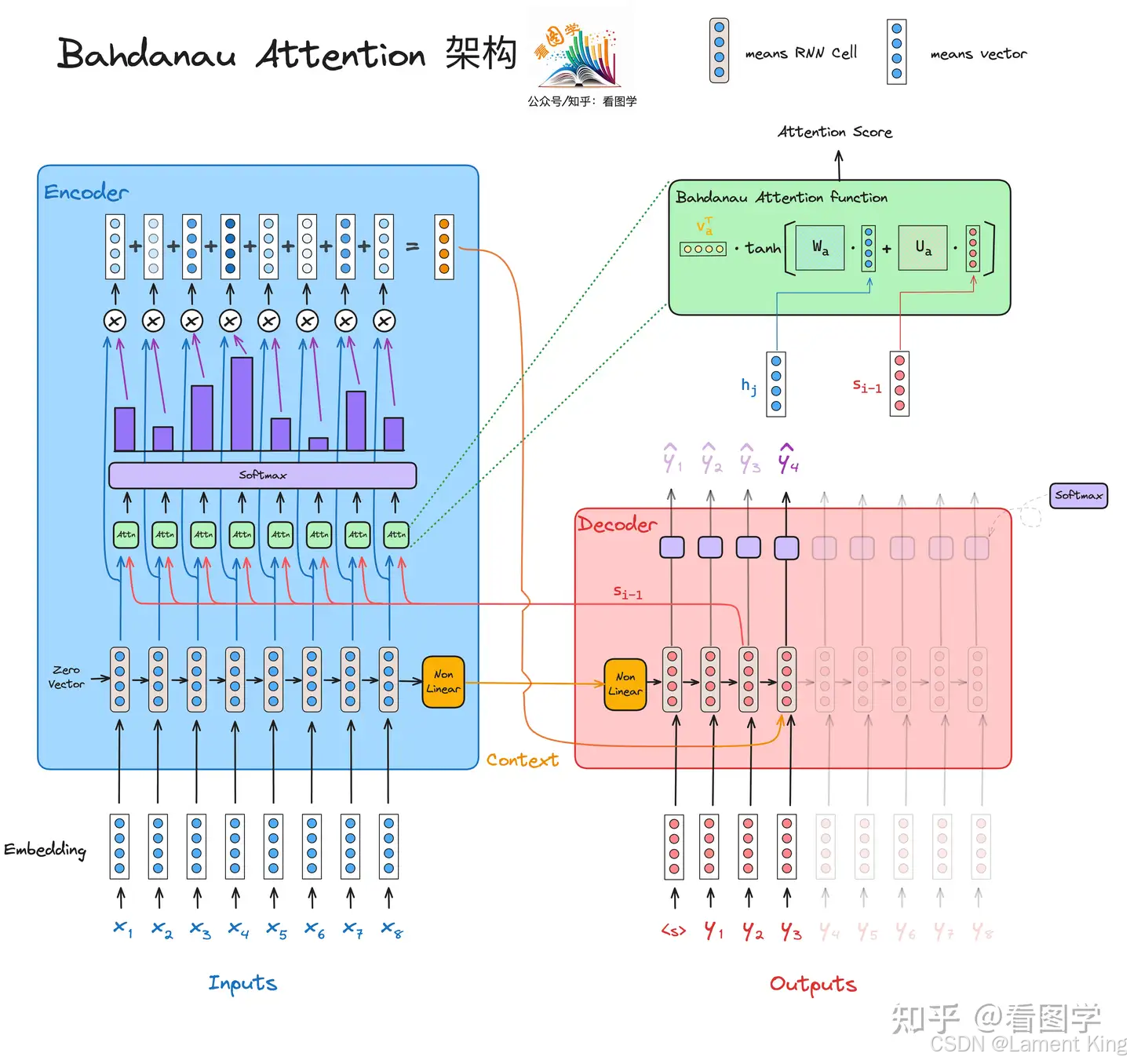
在 RNN Encoder-Decoder 中, P ( y t ) = g ( y t − 1 , s t − 1 , c ) P(y_{t}) =g(y_{t-1}, s_{t-1}, c) P(yt)=g(yt−1,st−1,c),无论 t t t 是0还是100,decoder每次输出时,来自encoder的上下文向量 c c c 是不变的,但实际上,翻译过程中,输出第 t t t 个单词时,对原文中所关注的位置是不同的。Bahdanau 在文章《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》中,认为上下文向量 c c c 应该是动态的,故提出了Bahdanau Attention用以计算上下文向量。
以下是Bahdanau Attention计算
c
t
c_t
ct 的过程:
先计算对齐分数,即影响程度,它反应decoder在生成第
t
t
t 个位置上的单词时,受encoder位置
j
j
j 上的单词的影响:
e
t
j
=
v
T
t
a
n
h
(
W
a
s
t
−
1
+
U
a
h
j
)
e_{tj}=v^Ttanh(W_as_{t-1}+U_ah_j)
etj=vTtanh(Wast−1+Uahj)
这里之所以用
s
t
−
1
s_{t-1}
st−1 是为了将已生成的序列也纳入考虑,之所以不用
s
t
s_{t}
st ,是因为
s
t
=
R
N
N
(
s
t
−
1
,
[
y
t
−
1
;
c
t
]
)
s_{t} =RNN(s_{t-1},[y_{t-1} ; c_t])
st=RNN(st−1,[yt−1;ct]),
c
t
c_t
ct 得靠上述过程才能求出来。
我们把encoder上所有位置对decoder生成第
t
t
t 个位置时的影响归一化,然后再获得encoder位置
j
j
j 上的单词对生成
t
t
t 的影响,这里实际上是获得权重:
α
t
j
=
e
x
p
(
e
t
j
)
∑
k
=
1
T
e
x
p
(
e
t
j
)
\alpha_{tj} = \frac{exp(e_{tj})}{\sum_{k=1}^{T} exp(e_{tj})}
αtj=∑k=1Texp(etj)exp(etj)
这里
T
T
T 是encoder中输入单词的个数。
我们把encoder中获得的隐藏层按照上述权重进行加权,获得上下文向量:
c
t
=
∑
j
=
1
T
α
t
j
h
j
c_t = {\textstyle \sum_{j=1}^{T}} \alpha _{tj}h_j
ct=∑j=1Tαtjhj
我们可以认为,
c
t
c_t
ct 就是
h
j
h_j
hj 的线性组合。
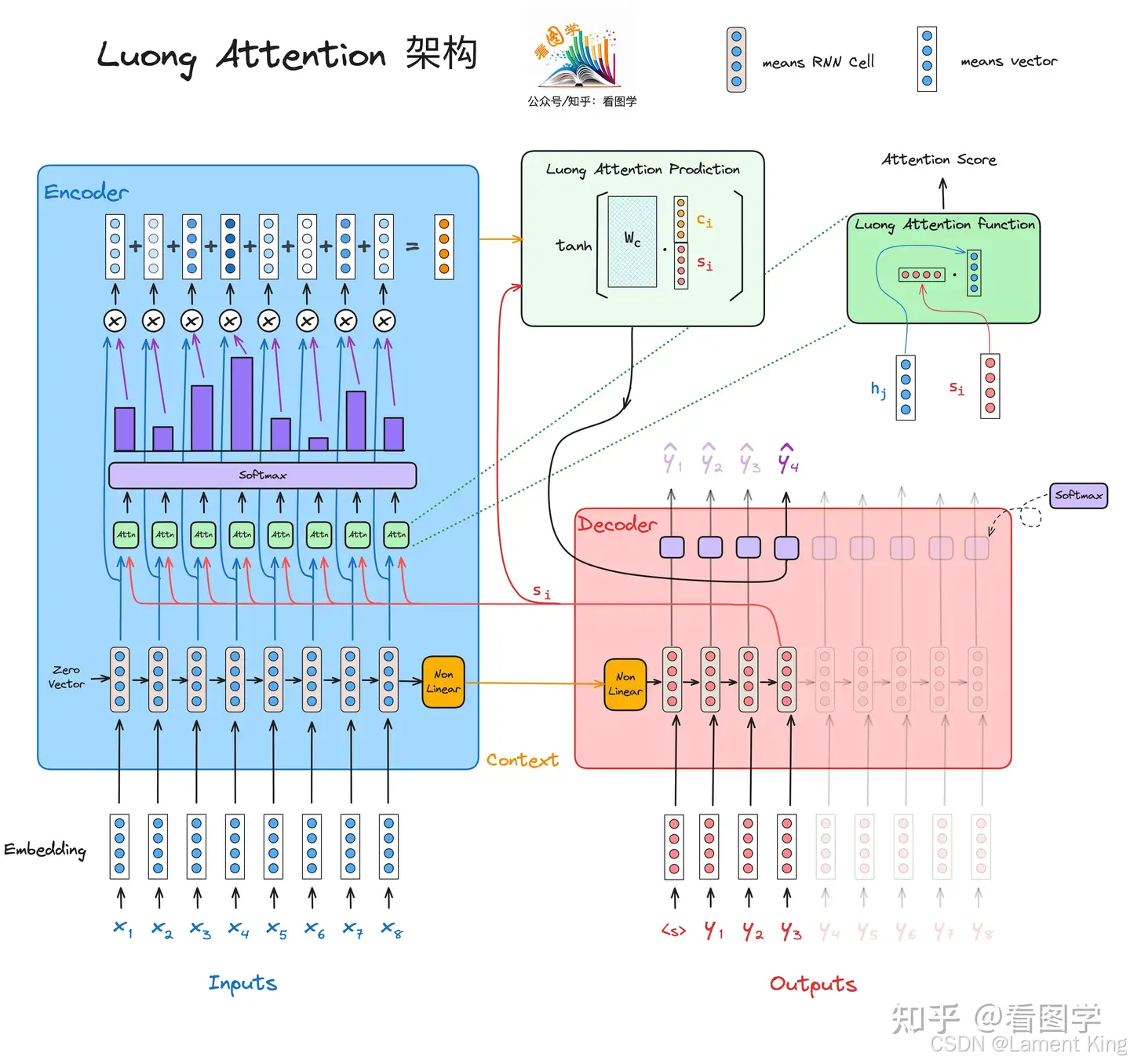
3 Luong Attention
Bahdanau Attention在计算对齐分数的时候,
e
t
j
=
v
T
t
a
n
h
(
W
a
s
t
−
1
+
U
a
h
j
)
e_{tj}=v^Ttanh(W_as_{t-1}+U_ah_j)
etj=vTtanh(Wast−1+Uahj),括号内用的是加法(即加性注意力机制Additive Attention)。Luong认为还可以使用其他方法,并在文章《Effective Approaches to Attention-based Neural Machine Translation》中提出了三种计算方式(为了和前面的内容符号能统一,我这里没有使用论文中的符号):
e
(
t
,
j
)
=
{
s
t
⋅
h
j
s
t
W
a
h
j
v
a
⊤
tanh
(
W
a
[
s
t
;
h
j
]
)
\operatorname{e}\left(t, j\right)=\left\{\begin{array}{l} {s}_{t} \cdot h_j \\ {s}_{t} W_a h_j \\ {v}_{a}^{\top} \tanh \left({W}_{{a}}\left[{s}_{t} ; h_j\right]\right) \end{array}\right.
e(t,j)=⎩
⎨
⎧st⋅hjstWahjva⊤tanh(Wa[st;hj])
这三种注意力机制分别是点乘(dot)、一般(general)、拼接(concat)。
论文中对计算
s
t
{s}_{t}
st 的方式做了优化,
s
t
=
L
S
T
M
(
s
t
−
1
,
y
t
−
1
)
s_t=LSTM(s_{t-1},y_{t-1})
st=LSTM(st−1,yt−1) ,即不再需要
c
t
{c}_{t}
ct。计算得到
e
t
j
e_{tj}
etj 后,就能得到
α
t
j
\alpha_{tj}
αtj 和
c
t
c_t
ct,计算方式与前面相同。
随后可以得到单词分布:
P
(
y
t
)
=
softmax
(
W
s
t
a
n
h
(
[
c
t
;
s
t
]
)
)
P(y_{t}) =\operatorname{softmax}\left(W_stanh\left([c_t;s_t]\right)\right)
P(yt)=softmax(Wstanh([ct;st]))
4 Self Attention/Masked Self Attention
前面介绍的注意力机制,在计算对齐分数的时候,都是拿目标语言的语义信息和源语言的语义信息进行计算,即它们是在两个不同的序列之间进行计算的,这种注意力机制被成为交叉注意力机制(Cross Attention)。除了交叉注意力机制,还有一种被称为“自注意力机制(Self Attention)”或者“内部注意力机制(Intra Attention)”的方式,它是在一个序列的内部进行注意力分数计算,即计算当前词与之前所有词的注意力分数。
Jianpeng Cheng在文章《Long Short-Term Memory-Networks for Machine Reading》中改进了LSTM,提出了一个名为LSTMN的网络结构,该网络在LSTM的基础上增加了注意力机制。
我们先复习一下LSTM的计算过程:
i
t
=
σ
(
W
i
[
h
t
−
1
,
x
t
]
+
b
i
)
f
t
=
σ
(
W
f
[
h
t
−
1
,
x
t
]
+
b
t
)
v
t
=
σ
(
W
o
[
h
t
−
1
,
x
t
]
+
b
o
)
c
t
^
=
tanh
(
W
c
[
h
t
−
1
,
x
t
]
+
b
c
)
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
c
t
^
h
t
=
o
t
⊙
tanh
(
c
t
)
\begin{aligned} i_{t} & =\sigma \left(W_{i}\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\ \\ f_{t} & =\sigma \left(W_{f}\left[h_{t-1}, x_{t}\right]+b_{t}\right) \\ \\ v_{t} & =\sigma \left(W_{o}\left[h_{t-1}, x_{t}\right]+b_{o}\right) \\ \\ \hat{c_t} & =\tanh \left(W_{c}\left[h_{t-1}, x_{t}\right]+b_{c}\right) \\ \\ c_{t} & =f_{t} \odot c_{t-1}+i_{t} \odot \hat{c_t} \\ \\ h_{t} & =o_{t} \odot \tanh \left(c_{t}\right) \end{aligned}
itftvtct^ctht=σ(Wi[ht−1,xt]+bi)=σ(Wf[ht−1,xt]+bt)=σ(Wo[ht−1,xt]+bo)=tanh(Wc[ht−1,xt]+bc)=ft⊙ct−1+it⊙ct^=ot⊙tanh(ct)
这里 h t − 1 h_{t-1} ht−1 是上一时刻的隐藏层, i t i_{t} it 是更新门, t t t_{t} tt 是遗忘门, o t o_{t} ot 是输出门, c t ^ \hat{c_t} ct^是短期记忆, c t c_{t} ct 是长期记忆,它综合考虑了上一时刻的长期记忆和当前的短期记忆,如果遗忘门为0,则彻底遗忘上一时刻的记忆,如果更新门是1,则新记忆需要完全被考虑。
改进后的计算过程为:
e
t
j
=
v
a
⊤
tanh
(
W
a
h
~
t
−
1
+
U
a
h
j
+
W
x
x
t
)
α
t
j
=
exp
(
e
t
j
)
∑
k
=
1
t
exp
(
e
t
k
)
e_{t j}=v_{a}^{\top} \tanh \left(W_{a} \tilde{h}_{t-1}+U_{a} h_{j}+W_{x} x_{t}\right) \\ \alpha_{tj}=\frac{\exp \left(e_{tj}\right)}{\sum_{k=1}^{t} \exp \left(e_{tk}\right)} \\
etj=va⊤tanh(Wah~t−1+Uahj+Wxxt)αtj=∑k=1texp(etk)exp(etj)
注意求和符号的上标,已经不再是T。
[
h
~
t
c
~
t
]
=
∑
j
=
1
t
−
1
α
t
j
⋅
[
h
j
c
j
]
i
t
=
σ
(
W
i
[
h
~
t
,
x
t
]
+
b
i
)
f
t
=
σ
(
W
f
[
h
~
t
,
x
t
]
+
b
f
)
o
t
=
σ
(
W
o
[
h
t
~
,
x
t
]
+
b
o
)
c
^
t
=
tanh
(
W
c
[
h
~
t
,
x
t
]
+
b
c
)
c
t
=
f
t
⊙
c
~
t
+
i
t
⊙
c
^
t
h
t
=
o
t
⊙
tanh
(
c
t
)
\begin{array}{l} \left[\begin{array}{c} \tilde{h}_{t} \\ \tilde{c}_{t} \end{array}\right]=\sum_{j=1}^{t-1} \alpha_{tj} \cdot\left[\begin{array}{l} h_{j} \\ c_{j} \end{array}\right] \\ \\ \begin{array}{l} i_{t}=\sigma \left(W_{i}\left[\tilde{h}_{t}, x_{t}\right]+b_{i}\right)\\ \\ f_{t}=\sigma \left(W_{f}\left[\tilde{h}_{t}, x_{t}\right]+b_{f}\right) \\ \\ o_{t}=\sigma \left(W_{o}\left[\tilde{h_{t}}, x_{t}\right]+b_{o}\right) \\ \\ \hat{c}_{t}=\tanh \left(W_{c}\left[\tilde{h}_{t}, x_{t}\right]+b_{c}\right) \\ \\ c_{t}=f_{t} \odot \tilde{c}_{t}+i_{t} \odot \hat{c}_{t} \\ \\ h_{t}=o_{t} \odot \tanh \left(c_{t}\right) \end{array} \end{array}
[h~tc~t]=∑j=1t−1αtj⋅[hjcj]it=σ(Wi[h~t,xt]+bi)ft=σ(Wf[h~t,xt]+bf)ot=σ(Wo[ht~,xt]+bo)c^t=tanh(Wc[h~t,xt]+bc)ct=ft⊙c~t+it⊙c^tht=ot⊙tanh(ct)
我们前后对比一下:
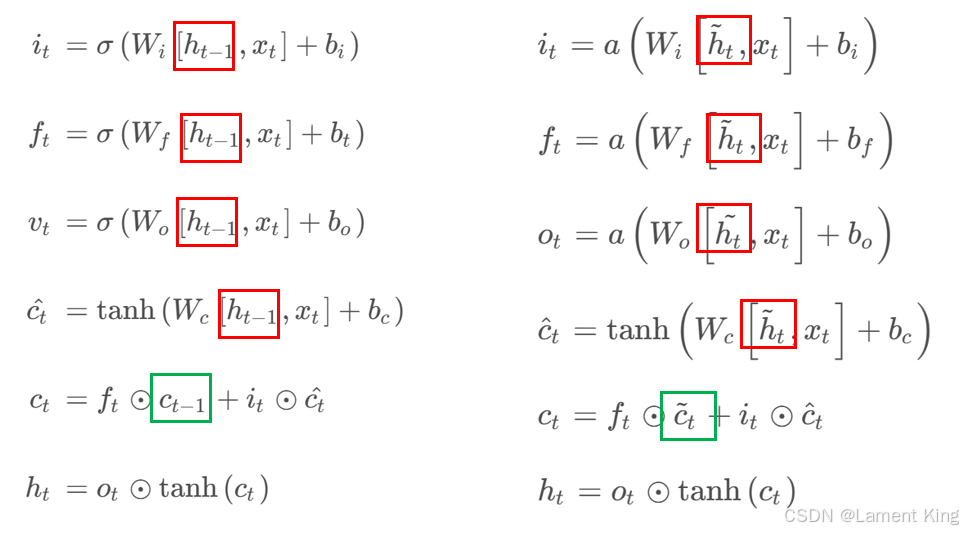
这里把
h
t
−
1
h_{t-1}
ht−1 和
c
t
−
1
c_{t-1}
ct−1 分别改成了
h
~
t
\tilde{h}_{t}
h~t 和
c
~
t
\tilde{c}_{t}
c~t,而
h
~
t
\tilde{h}_{t}
h~t 和
c
~
t
\tilde{c}_{t}
c~t 则是通过对前面
h
j
h_{j}
hj 和
c
j
c_{j}
cj 加权得到:
[
h
~
t
c
~
t
]
=
∑
j
=
1
t
−
1
α
t
j
⋅
[
h
j
c
j
]
\left[\begin{array}{c} \tilde{h}_{t} \\ \tilde{c}_{t} \end{array}\right]=\sum_{j=1}^{t-1} \alpha_{tj} \cdot\left[\begin{array}{l} h_{j} \\ c_{j} \end{array}\right]
[h~tc~t]=j=1∑t−1αtj⋅[hjcj]
而计算权重的时候,也是对已经输入的位置计算:
α
t
j
=
exp
(
e
t
j
)
∑
k
=
1
t
exp
(
e
t
k
)
\alpha_{tj}=\frac{\exp \left(e_{tj}\right)}{\sum_{k=1}^{t} \exp \left(e_{tk}\right)}
αtj=∑k=1texp(etk)exp(etj)
也就是说,这种注意力机制只关注前面的词,故被称为Masked Self Attention。
5 MultiHead Self Attention
我们先来介绍一下句子嵌入(sentence embedding):把一段可变长度的文本,用一个固定长度的向量来表示。论文《A structured self-attentive sentence embedding》则提出了一种方法,把文本用固定维度的矩阵来表示,这篇文章更重要的是,提出了多头注意力机制。
假设一条句子有n个单词,经过词嵌入后,可以表示成:
s
=
(
w
1
,
w
2
,
.
.
.
,
w
n
)
s=(w_1, w_2, ... , w_n)
s=(w1,w2,...,wn)
这里
w
i
w_i
wi 是词嵌入向量。
将序列
s
s
s 输入一个双向LSTM网络:
h
t
→
=
L
S
T
M
→
(
w
t
,
h
t
−
1
→
)
h
t
←
=
L
S
T
M
←
(
w
t
,
h
t
+
1
←
)
\begin{array}{l} \overrightarrow{h_t}=\overrightarrow{L S T M}\left(w_{t}, \overrightarrow{h_{t-1}}\right) \\ \overleftarrow{h_{t}}=\overleftarrow{L S T M}\left(w_{t}, \overleftarrow{h_{t+1}}\right) \end{array}
ht=LSTM(wt,ht−1)ht=LSTM(wt,ht+1)
这里
h
t
→
\overrightarrow{h_t}
ht 和
h
t
←
\overleftarrow{h_{t}}
ht 都是维度为u的向量,令:
h
t
=
[
h
t
→
,
h
t
←
]
h_t = \left[\overrightarrow{h_t}, \overleftarrow{h_{t}}\right]
ht=[ht,ht]
则
h
t
h_t
ht 是维度为2u的向量。
令:
H
=
[
h
1
h
2
.
.
.
h
n
]
H= \left[\begin{array}{c} h_{1} \\ h_{2} \\ ... \\ h_{n} \end{array}\right]
H=
h1h2...hn
则 H 的维度为(n, 2u)。
按下式计算
h
1
h_1
h1、
h
2
h_2
h2、……、
h
n
h_n
hn的权重:
a
=
softmax
(
w
s
2
tanh
(
W
s
1
H
T
)
)
a=\operatorname{softmax}\left(w_{s2} \tanh \left(W_{s 1} H^{T}\right)\right)
a=softmax(ws2tanh(Ws1HT))
这里
W
s
1
W_{s 1}
Ws1的维度为(da, 2u),
H
T
H^{T}
HT的维度为(2u, n),
w
s
2
w_{s 2}
ws2 的维度为(1, da),那么 a 的维度为(1, n)。
上面的公式相当于将下面两步合并了:
e
=
w
s
2
tanh
(
w
s
2
tanh
(
W
s
1
H
T
)
)
e=w_{s2} \tanh \left(w_{s2} \tanh(W_{s 1} H^{T})\right)
e=ws2tanh(ws2tanh(Ws1HT))
a
i
=
exp
(
e
i
)
∑
k
=
1
n
exp
(
e
k
)
a_{i}=\frac{\exp \left(e_{i}\right)}{\sum_{k=1}^{n} \exp \left(e_{k}\right)}
ai=∑k=1nexp(ek)exp(ei)
这里
e
e
e 不再是一个标量,而是一个向量。
m
=
a
H
m=aH
m=aH
m的维度为(1, 2u),它相当于将
h
1
h_1
h1、
h
2
h_2
h2、……、
h
n
h_n
hn 进行线性组合,其中
h
i
h_i
hi 的权重为
a
i
a_i
ai,m 就是我们前面说的上下文向量
c
t
c_t
ct。
m是一个向量,它的长度与输入序列的单词个数无关,只与LSTM输出的隐藏层维度有关,因此,它实现了句子嵌入。
现在我们用
W
s
2
W_{s 2}
Ws2 替代
w
s
2
w_{s 2}
ws2,
W
s
2
W_{s 2}
Ws2 是一个维度为(r, da)的矩阵,即相当于将上述求 a 的过程重复 r 次,那么有:
A
=
softmax
(
W
s
2
tanh
(
W
s
1
H
T
)
)
A=\operatorname{softmax}\left(W_{s2} \tanh \left(W_{s 1} H^{T}\right)\right)
A=softmax(Ws2tanh(Ws1HT))
这里 A 的维度为(r, n),
M
=
A
H
M=AH
M=AH
M 的维度为 (r, 2u),此时我们实现了将一个句子变成了一个矩阵,它的维度与输入的单词个数无关。
一个 m 只能反应句子语义中的一个方面或者组成部分,为了表示句子的整体语义,可以使用多个 m 来表示句子的不同方面,这就是所谓的多头注意力机制,有点类似于CNN里的多通道,每个通道处理不同的信息。
这里是 r 个头,将 r 个 m 拼接成 M,相当于对 h 1 h_1 h1、 h 2 h_2 h2、……、 h n h_n hn 做了 r 次线性组合,然后将这 r 次的结果合并成一个矩阵。
6 Key-Value Attention
Michał Daniluk等人在《FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING》中认为,在带有注意力机制的语言生成模型中,RNN或者LTSM每一个时步输出一个 h(有的文献中是 s,例如Bahdanua Attention),在我们前面介绍的注意力机制中,这个 h 既要作为键(key)从历史记忆中获取上下文向量(作者是把对过去隐藏层向量进行加权得到上下文向量的过程,看成是使用 Key-Value 的方式从过去的记忆中进行查询的过程),又要用于预测下一个单词(token),还要传输给下一个时步(当前时步的 h h h 就是下一时步的 h t − 1 h_{t-1} ht−1)。这种对 h 的过度使用使得模型训练变得困难,作者随即提出,可以把 h 分成多份,仅让一部分去计算注意力分数,一部分计算上下文向量,另一部分专注于预测下一个单词,这就是Key-Value Attention的思想。我们看下面介绍能更清楚的理解。
假设语言模型是基于LSTM,LSTM在
t
t
t 时刻的输出为
h
t
∈
R
k
\boldsymbol h_t \in \mathbb{R}^{k}
ht∈Rk ,这是影藏层向量,还不能直接用于预测单词分布。此时有个长度为 L 的滑动窗口,它把前面 L 步的隐藏层向量给圈了出来,得到一个矩阵
Y
t
=
(
h
t
−
L
,
h
t
−
L
+
1
,
.
.
.
,
h
t
−
1
)
∈
R
k
×
L
\boldsymbol{Y_t}=(\boldsymbol{h}_{t-L}, \boldsymbol{h}_{t-L+1}, ... , \boldsymbol{h}_{t-1}) \in \mathbb{R}^{k \times L}
Yt=(ht−L,ht−L+1,...,ht−1)∈Rk×L,那么可以使用注意力的方式,在
t
t
t 时刻预测下一个单词的概率分布(即输入第 t 个单词,然后预测第 t+1 个单词,语言模型就是这样的):
M
t
=
tanh
(
W
Y
Y
t
+
(
W
h
h
t
)
1
T
)
∈
R
k
×
L
α
t
=
softmax
(
w
T
M
t
)
∈
R
1
×
L
r
t
=
Y
t
α
T
∈
R
k
h
t
∗
=
t
a
n
h
(
W
r
r
t
+
W
x
h
t
)
∈
R
k
y
t
=
softmax
(
W
∗
h
t
∗
+
b
)
∈
R
∣
V
∣
\begin{aligned} \boldsymbol{M}_{t} & =\tanh \left(\boldsymbol{W}^{Y} \boldsymbol{Y}_{t}+\left(\boldsymbol{W}^{h} \boldsymbol{h}_{t}\right) \mathbf{1}^{T}\right) & & \in \mathbb{R}^{k \times L} \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{w}^{T} \boldsymbol{M}_{t}\right) & & \in \mathbb{R}^{1 \times L} \\ \boldsymbol{r}_{t} & =\boldsymbol{Y}_{t} \boldsymbol{\alpha}^{T} & & \in \mathbb{R}^{k} \\ \boldsymbol{h}_{t}^{*} & =tanh(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{h}_{t}) & & \in \mathbb{R}^{k}\\ \boldsymbol{y}_{t} & =\operatorname{softmax}\left(\boldsymbol{W}^{*} \boldsymbol{h}_{t}^{*}+\boldsymbol{b}\right) & & \in \mathbb{R}^{|V|} \end{aligned}
Mtαtrtht∗yt=tanh(WYYt+(Whht)1T)=softmax(wTMt)=YtαT=tanh(Wrrt+Wxht)=softmax(W∗ht∗+b)∈Rk×L∈R1×L∈Rk∈Rk∈R∣V∣
其中
W
Y
,
W
h
,
W
r
,
W
x
∈
R
k
×
k
W^Y, W^h, W^r, W^x \in \mathbb{R}^{k \times k}
WY,Wh,Wr,Wx∈Rk×k,
w
∈
R
k
w \in \mathbb{R}^k
w∈Rk,
W
∗
∈
R
∣
V
∣
×
k
W^* \in \mathbb{R}^{|V| \times k}
W∗∈R∣V∣×k,
b
∈
R
∣
V
∣
b \in \mathbb{R}^{|V|}
b∈R∣V∣ ,这些都是可训练参数,而
1
∈
R
L
\mathbf{1} \in \mathbb{R}^L
1∈RL,是全为1的向量。上述过程示意图:
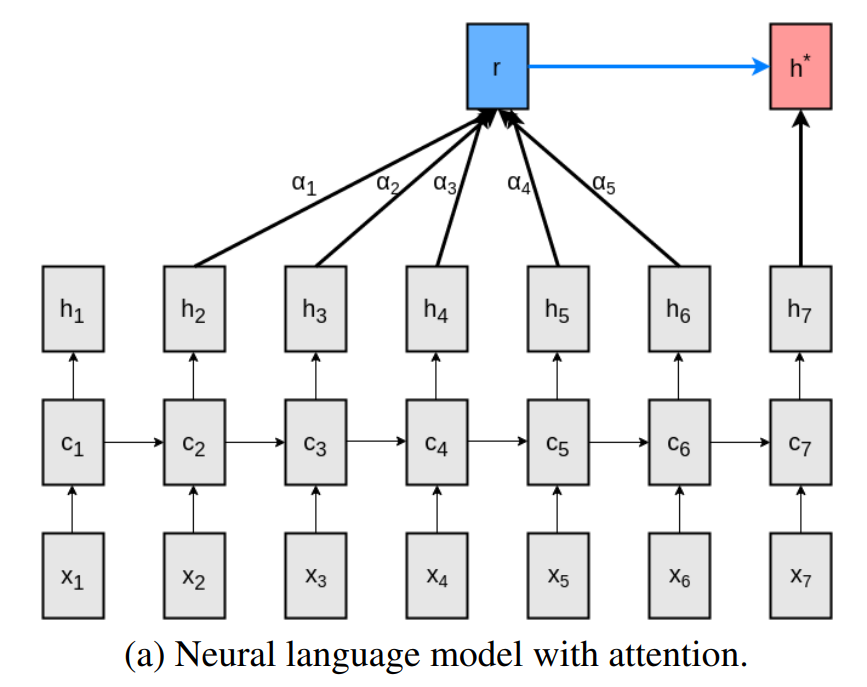
可以看到,这里 h t \boldsymbol h_t ht 在 h t ∗ = t a n h ( W r r t + W x h t ) \boldsymbol{h}_{t}^{*} =tanh(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{h}_{t}) ht∗=tanh(Wrrt+Wxht) 中,既要用于计算上下文向量 r t \boldsymbol r_t rt,又要用于计算 h t ∗ \boldsymbol{h}_{t}^{*} ht∗,以便预测下一个单词。
Michał Daniluk等人的工作,就是对这些功能解耦。所谓解耦,就是让不同的功能有各自独立的可训练参数,CV中有个名为YOLOX的模型,它们的检测头设计,也有解耦的思想在里面,让分类、位置和置信度得分在不同的路径中预测,思想和这个类似。
他们先把 h 分成了两份,一份称为 key 用来计算注意力权重,另一份称为 value,用来计算上下文向量和下一个单词的分布,上述注意力机制改进如下:
[
k
t
v
t
]
=
h
t
∈
R
2
k
M
t
=
tanh
(
W
Y
[
k
t
−
L
⋯
k
t
−
1
]
+
(
W
h
k
t
)
1
T
)
∈
R
k
×
L
α
t
=
softmax
(
w
T
M
t
)
∈
R
1
×
L
r
t
=
[
v
t
−
L
⋯
v
t
−
1
]
α
T
∈
R
k
h
t
∗
=
tanh
(
W
r
r
t
+
W
x
v
t
)
∈
R
k
\begin{aligned} {\left[\begin{array}{c} \boldsymbol{k}_{t} \\ \boldsymbol{v}_{t} \end{array}\right] } & =\boldsymbol{h}_{t} & & \in \mathbb{R}^{2 k} \\ \boldsymbol{M}_{t} & =\tanh \left(\boldsymbol{W}^{Y}\left[\boldsymbol{k}_{t-L} \cdots \boldsymbol{k}_{t-1}\right]+\left(\boldsymbol{W}^{h} \boldsymbol{k}_{t}\right) \mathbf{1}^{T}\right) & & \in \mathbb{R}^{k \times L} \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{w}^{T} \boldsymbol{M}_{t}\right) & & \in \mathbb{R}^{1 \times L} \\ \boldsymbol{r}_{t} & =\left[\boldsymbol{v}_{t-L} \cdots \boldsymbol{v}_{t-1}\right] \boldsymbol{\alpha}^{T} & & \in \mathbb{R}^{k} \\ \boldsymbol{h}_{t}^{*} & =\tanh \left(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{v}_{t}\right) & & \in \mathbb{R}^{k} \end{aligned}
[ktvt]Mtαtrtht∗=ht=tanh(WY[kt−L⋯kt−1]+(Whkt)1T)=softmax(wTMt)=[vt−L⋯vt−1]αT=tanh(Wrrt+Wxvt)∈R2k∈Rk×L∈R1×L∈Rk∈Rk
结构如下图:
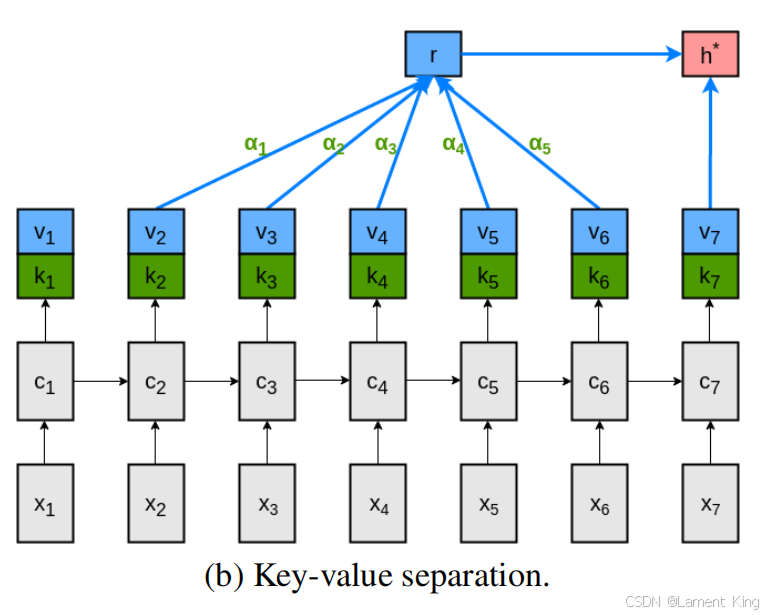
key 和 value 分离后,对于 v i v_i vi,既要在第 i i i 个时步用于计算下一个单词的分布,即 h i ∗ = tanh ( W r r i + W x v i ) h_i^{*} =\tanh (W^{r} r_{i}+W^{x} v_{i}) hi∗=tanh(Wrri+Wxvi)
又要在后续的 L L L 个时步中,用于计算上下文向量 r k \boldsymbol{r}_k rk,即 r k = [ v k − L ⋯ v k − 1 ] α T r_k =[v_{k-L} \cdots v_{k-1}] {\alpha}^{T} rk=[vk−L⋯vk−1]αT, k ∈ [ i + 1 , i + L ] k \in \mathbb [i+1, i+L] k∈[i+1,i+L]
因此可以把 value 的两个功能进一步解耦,从其中分出一部分(命名为 predict )专门用来预测下一个单词的分布,最后的注意力机制计算过程如下:
[
k
t
v
t
p
t
]
=
h
t
∈
R
2
k
M
t
=
tanh
(
W
Y
[
k
t
−
L
⋯
k
t
−
1
]
+
(
W
h
k
t
)
1
T
)
∈
R
k
×
L
α
t
=
softmax
(
w
T
M
t
)
∈
R
1
×
L
r
t
=
[
v
t
−
L
⋯
v
t
−
1
]
α
T
∈
R
k
h
t
∗
=
tanh
(
W
r
r
t
+
W
x
p
t
)
∈
R
k
\begin{aligned} {\left[\begin{array}{c} \boldsymbol{k}_{t} \\ \boldsymbol{v}_{t} \\ \boldsymbol{p}_{t} \end{array}\right] } & =\boldsymbol{h}_{t} & & \in \mathbb{R}^{2 k} \\ \boldsymbol{M}_{t} & =\tanh \left(\boldsymbol{W}^{Y}\left[\boldsymbol{k}_{t-L} \cdots \boldsymbol{k}_{t-1}\right]+\left(\boldsymbol{W}^{h} \boldsymbol{k}_{t}\right) \mathbf{1}^{T}\right) & & \in \mathbb{R}^{k \times L} \\ \boldsymbol{\alpha}_{t} & =\operatorname{softmax}\left(\boldsymbol{w}^{T} \boldsymbol{M}_{t}\right) & & \in \mathbb{R}^{1 \times L} \\ \boldsymbol{r}_{t} & =\left[\boldsymbol{v}_{t-L} \cdots \boldsymbol{v}_{t-1}\right] \boldsymbol{\alpha}^{T} & & \in \mathbb{R}^{k} \\ \boldsymbol{h}_{t}^{*} & =\tanh \left(\boldsymbol{W}^{r} \boldsymbol{r}_{t}+\boldsymbol{W}^{x} \boldsymbol{p}_{t}\right) & & \in \mathbb{R}^{k} \end{aligned}
ktvtpt
Mtαtrtht∗=ht=tanh(WY[kt−L⋯kt−1]+(Whkt)1T)=softmax(wTMt)=[vt−L⋯vt−1]αT=tanh(Wrrt+Wxpt)∈R2k∈Rk×L∈R1×L∈Rk∈Rk
结构图如下:
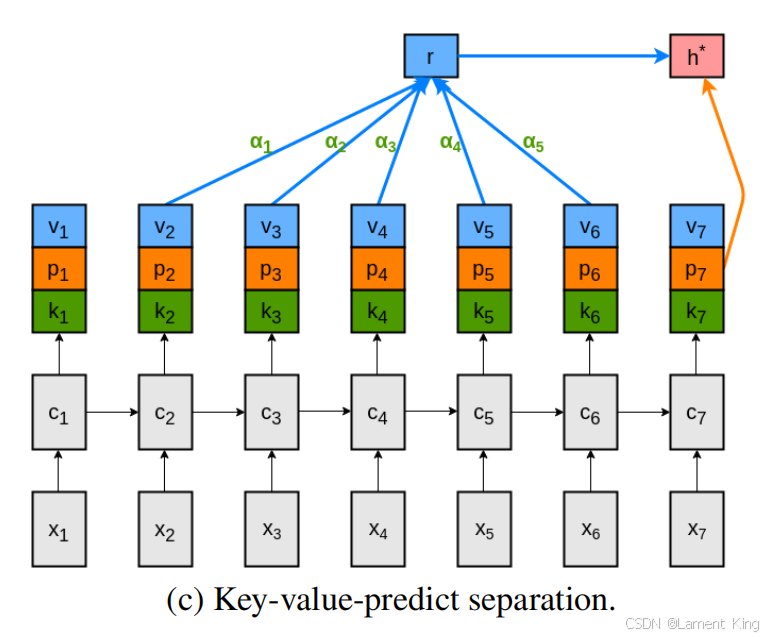
后面的 transformer 中的 QKV 注意力机制,其原型是来自于Key-Value注意力机制,并没有使用P,而是加了一个Query,这个我们会在下篇文章中介绍。
7 ResNet
这个熟悉CV的同学都知道,来源于何凯明的神作《Deep Residual Learning for Image Recognition》。ResNet中的残差块示意图如下:
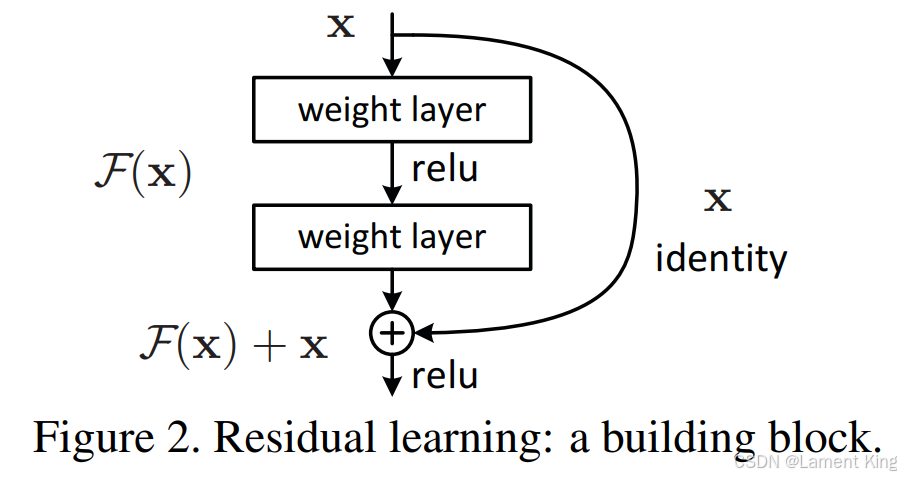
在它出现之前,CNN的网络层数不能太深,太深的话,靠近输出的层会出现梯度消失,导致参数更新困难,有了ResNet之后,因为短连接的存在,很好地解决了这个问题,使模型可以设计的更深。
8 总结
本文主要介绍的是 Transformer 的一些先修知识,通过这些知识,可以更好的理解 transformer 的结构和原理。本文读完之后,需要知道EncoderDecoder和Bahdanau Attention,什么是加性注意力机制,什么是点乘注意力机制,什么自注意力机制,什么是交叉注意力机制,什么是Mask自注意力机制,什么是多头注意力机制,什么是KV注意力机制。
https://zhuanlan.zhihu.com/p/690984212
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Effective Approaches to Attention-based Neural Machine Translation
Long Short-Term Memory-Networks for Machine Reading
A structured self-attentive sentence embedding
FRUSTRATINGLY SHORT ATTENTION SPANS IN NEURAL LANGUAGE MODELING
Deep Residual Learning for Image Recognition


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









