






 文章介绍了贪心法的概念,作为一种多步求解方法,它在优化问题中广泛应用,如货箱装船问题、最短路径问题、哈弗曼编码等。贪心法通过每步选择局部最优解,逐步构建全局解,但并不保证总能得到精确的最优解。例如,在货箱装船问题中,通过按重量升序装载集装箱可以找到最优解;而在最短路径问题中,Dijkstra算法利用贪心策略寻找非负权重图的最短路径。
文章介绍了贪心法的概念,作为一种多步求解方法,它在优化问题中广泛应用,如货箱装船问题、最短路径问题、哈弗曼编码等。贪心法通过每步选择局部最优解,逐步构建全局解,但并不保证总能得到精确的最优解。例如,在货箱装船问题中,通过按重量升序装载集装箱可以找到最优解;而在最短路径问题中,Dijkstra算法利用贪心策略寻找非负权重图的最短路径。
*贪心法的概念:(记忆)
贪心法是一种多步求解的方法
每步按照局部优化的策略选择解(元组)的一个分量
算法以第n步结束时构造出的解(元组)作为问题的解
这种局部优化的策略又称为“贪心标准”
注意:优化策略一般要选简单的
不回溯,一旦一个分量选定,不可尝试其他可能
贪心法常用于求解优化问题:
应用:
(1)货箱装船问题
(2)背包问题
(3)拓扑排序问题
(4)哈弗曼编码问题
(5)最短路径问题
(6)最小代价生成树
(7)偶图覆盖问题
优化问题可描述如下:
问题的解:元组形式
约束条件
目标函数
优化解:是目标函数极大或极小的可行解,对应的目标函数值称为优化值
很多优化问题是NP-难度问题,计算上可行的方法是求其近似解,贪心法是求近似解的主要途径
贪心法主要是为了减小开销,不一定得到精确的优化解
货箱装船问题:
题目描述:船的载重量有限,将n个集装箱
(重量wi,1<=i<=n)装在船上,使装入的数量最多。
问题的解:(x1,x2,……,xn)xi=0,1 0代表不装,1代表装
一共有2^n种状态(不考虑是否能装下)
暴力搜索2^n次,也可以找到解(复杂度2 ^n)
约束条件:∑(i=1,n)wixi<=c
目标函数:∑(i=1,n)xi
贪心法:优先选轻的
先排序:(复杂度)nlogn
从轻往重的装:(线性复杂度)Θ(n)
货箱装船问题的贪心解是最优解的证明:
设货箱装船问题的最优解是(y1,…yn)
如最优解不含箱子1,用箱子1替换最优解中的某一个箱子得到一个新的解
- 替换是必须的:因为如果箱子1还能装入船中,则(y1,…,yn)不是最优解
- 因为箱子1是最轻的,所以替换后的解仍是可行的
- 替换后的解装入的箱子数等于最优的装箱数,所以它仍是最优解
- 替换后新的最优解和贪心解都包含箱子1
反复替换将得到一个最优解,等于贪心解
替换次数是有穷的
`
活动安排问题:
问题描述:只有一个公共场所资源,一次只能有一个活动占用,要求安排的活动尽可能多 。
各活动的起始时间和结束时间存储于数组s和f中,且按结束时间的非减序排列。
每次总是选择具有最早结束时间的相容活动加入到可行解中。(相容:两个活动没有相交的部分)
最大化策略:使得剩余时间最大化
排序:(复杂度)nlogn
活动安排:(复杂度)Θ(n)
机器调度问题:
用尽可能少的资源完成所有任务,每个任务有一个时间区间(起始和终止)
题目描述:n个任务和足够多的机器,任何时间一个机器只能执行一个任务,求占用机器数最少的可行分配。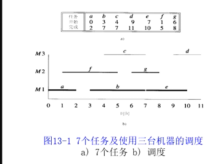
按起始时间排序:a->f->b->c->g->e->d
隐含的思想:(贪心策略)优先选旧机器,尽可能不用新机器(任务不相容时才使用新的机器)
要使每个机器的最小可用时间点尽可能早(最小可用时间点即该机器上上个任务的结束时间)
注意:当两个旧机器都与要新放的任务相容,应优先选最小可用时间最小的那个机器(如任务d分给了M3而不是M2) 当两个旧机器当前的最小可用时间相等且与要新放的任务相容,则应优先选最旧的机器(该机器对应的数组位置靠前)(如任务e分给了M1而不是M3)
先排序(按开始时间从小到大排序)
使用min-堆存放每台机器的最小可用时间,即该时间后可分配新任务
复杂度:nlogn(排序和堆操作)。
在活动安排和机器调度问题上,上述贪心算法总能得到整体最优解。
最短路径问题:
一个有向图,求从源节点s到目的结点d的最短路
贪心策略:从源节点开始,选与源节点相邻且最近的下一节点q,选与q相邻且距q最近且不在之前所选路径上的下一节点,重复该过程。
0/1背包问题:
货箱装船问题是0/1背包问题的特例:pi=1
不能保证得到最优解
问题描述:背包容量c,n件物品,物品重量wi,效益值pi
要使装的总效益值最高。
问题的解:(x1,……,xn) 约束条件:∑(i=1,n)wixi<=c 目标函数:∑(i=1,n)wipi
贪心策略:
(1)优先装效益值大的
(2)优先装轻的
(3)密度贪心法:优先装效益值密度(pi/wi)最大的
伪代码:
1.将物品按密度从小到大排序
2.for(i=1;i<n;i++)
if(物品i可以装进背包) xi=1(装入)
else xi=0(舍弃);
复杂度:O(nlogn)
- c=11,w=(2,4,6,5),p=(6,10,12,9)
- 优化解为(1,1,0,1)
注意:若当前效益密度所对应的物品装不进,应继续往后看,若后面的可以装进,则装进背包。
误差:|优化值-贪心值|/优化值*100%
K-优化算法:误差控制在1/(k+1)*100%之内(有一点点穷举的思想)
预先装入不超过k的商品数,对其余商品用贪心法
- 算法时间复杂度随k的增大而增大:
- 需要测试的子集数目为O(n^k)
- 每个子集做贪心法需时间O(n)
- 因此当k>0时总的时间开销为O(n^k+1)
哈弗曼编码问题:
哈弗曼编码:用字符在文件中出现的频率表来建立一个用0、1串表示各字符的最优表示方式。
用短的编码代表出现频率高的字符,用长的代表出现频率低的字符
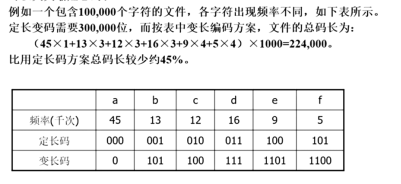
二叉树可以作为字符到0/1串的桥梁:使频率高的字符尽量接近树的顶部
前缀码:对每一个字符规定一个0/1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。
构造最优前缀码的贪心算法,由此产生的编码方案即哈夫曼编码

共n-1次合并
算法可用最小堆实现优先队列,初始化优先队列O(nlogn)(排序),由于最小堆的插入和删除均需要O(logn),n-1次合并(选最小并插入和删除)总共需要O(nlogn)。因此哈弗曼编码的计算时间为O(nlogn)。
拓扑排序:
根据任务的有向图建立建立拓扑序列的过程称为拓扑排序。
使用栈的伪代码:
1.计算每个顶点的入度
2.将入度为0的顶点入栈
3.while(栈不空)
{
任取一入度为0的顶点放入拓扑序列中;
将与其相邻的顶点入度减1;
如有新的入度为0的顶点出现,将其放入栈中;
}
如有剩余的顶点,则该图有环路;
使用邻接矩阵复杂度:Θ(n^2)
使用邻接表复杂度:Θ(n+e)
单源最短路径:
题目描述:一个有向图,找出从源节点s到图中所有其他节点的最短路径及其长度。
Dijkstra’s最短路算法:
如果链路权值非负,则最短路的子路径也是最短路。
贪心策略:按最短路长度从小到大依次求解。
基本步骤:
1.维护一个集合S,该集合源节点到其他节点的最短路已知,初始时该集合为空
2.从V-S结点中找一结点v,满足源节点到该节点距离最小
3.更新v的临界点到源节点的距离值
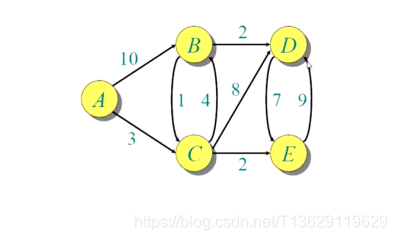
维护一个集合S
| Q | A B C D E |
|---|---|
| 0 ∞ ∞ ∞ ∞ | |
| S:{} | |
| `找一个最短路(A到A最短,把A放到集合中去) | |
| 更新源节点A到A的相邻点B,C的距离` | |
| Q | A B C D E |
| – | – |
| 0 10 3 ∞ ∞ | |
| S:{A} | |
在结点B,C,D,E中,源节点到C的距离最小,选C结点作为v结点放入S中,更新源节点A到C节点相临节点B,D,E的距离 | |
| Q | A B C D E |
| – | – |
| * 7 3 11 5 | |
| S:{A,C} | |
在结点B,D,E中,源节点到E的距离最小,选E结点作为v结点放入S中,更新源节点A到E节点相临节点D的距离 | |
| Q | A B C D E |
| – | – |
| * 7 * 14 5 | |
| S:{A,C,E} | |
在结点B,D中,源节点到B的距离最小,选B结点作为v结点放入S中,更新源节点A到B节点相临节点D的距离 | |
| Q | A B C D E |
| – | – |
| * 7 * 9 * | |
| S:{A,C,E,B} | |
| `在结点D中,源节点到D的距离最小,选D结点作为v结点放入S中,D节点在V-S中无相临节点,无需更新源节点A到D节点相临节点距离 | |
| 此时V-S为空,算法结束` | |
| Q | A B C D E |
| – | – |
| * * * 9 * | |
| S:{A,C,E,B,D} | |
| Q | A B C D E |
| – | – |
| * * * * * |

















 4868
4868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









