



目录
前言
动态数据蕴含着巨大的商业价值与研究意义,能否高效、精准地获取它们,直接影响着企业决策、市场分析乃至学术研究的深度与广度。
然而,动态数据的抓取并非易事。与静态网页数据相比,动态数据多由 JavaScript 渲染生成或通过 AJAX 异步加载,传统基于 HTML 解析的爬虫技术往往束手无策。此时,Python 凭借其丰富的爬虫生态成为解决这一难题的利器,Selenium、Pyppeteer 等库通过模拟浏览器行为,为动态数据抓取提供了技术支撑。但在实际应用中,开发者仍需面对反爬机制升级、环境配置复杂、维护成本过高等挑战。本文将给大家推荐一个比较好用的第三方平台来帮助大家获取动态数据。
一、第三方平台
二、使用步骤
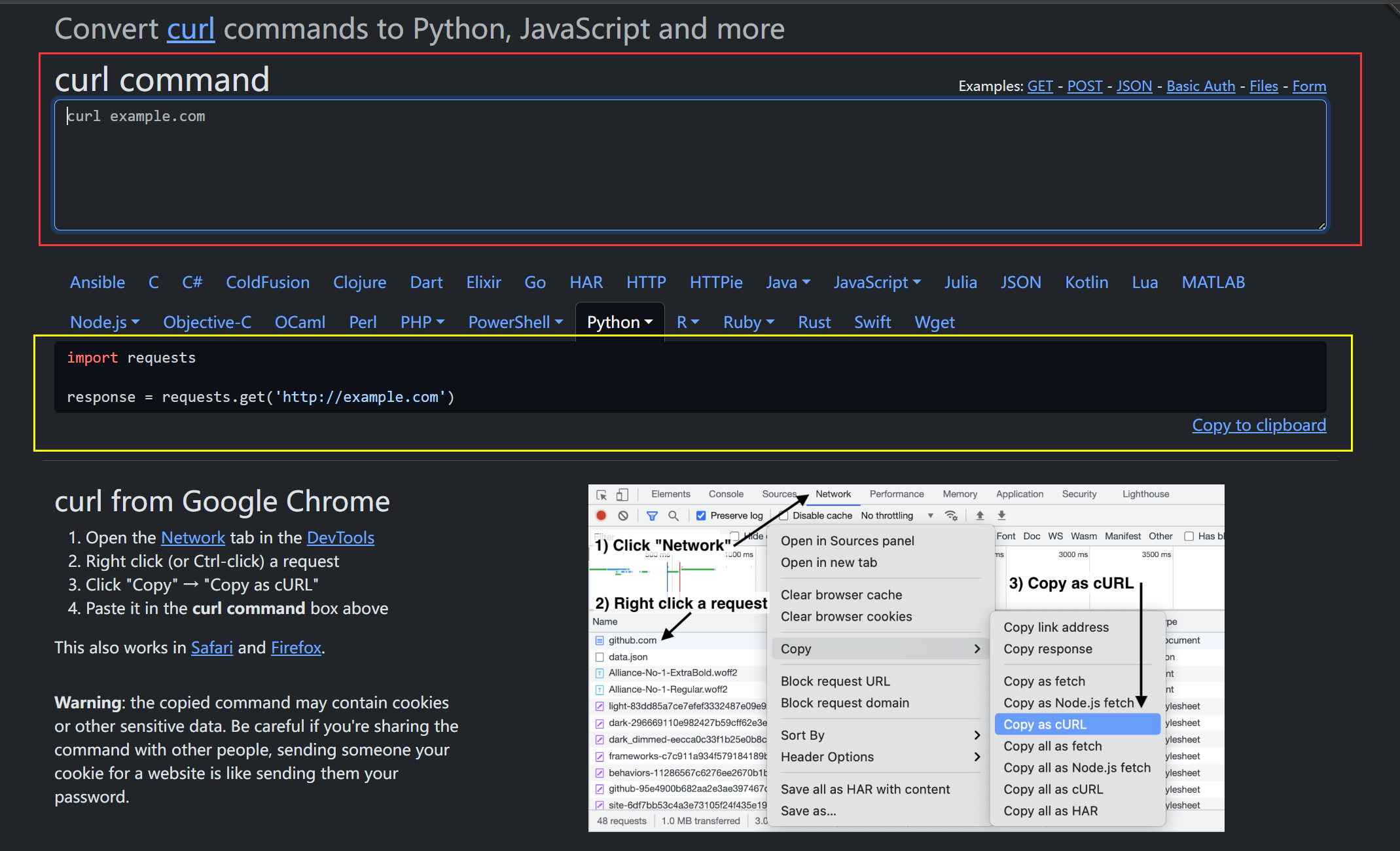
1.访问网址
点击链接进入主页面,红色区域部分就是我们需要传递的参数,黄色区域部分是它响应的Python代码。接下来我们以抖音点赞和取消点赞为例简单介绍一下如何使用。
2.创建文件
打开我们的开发者工具vscode中,创建文件。(注意后缀为.py)
3.寻找参数
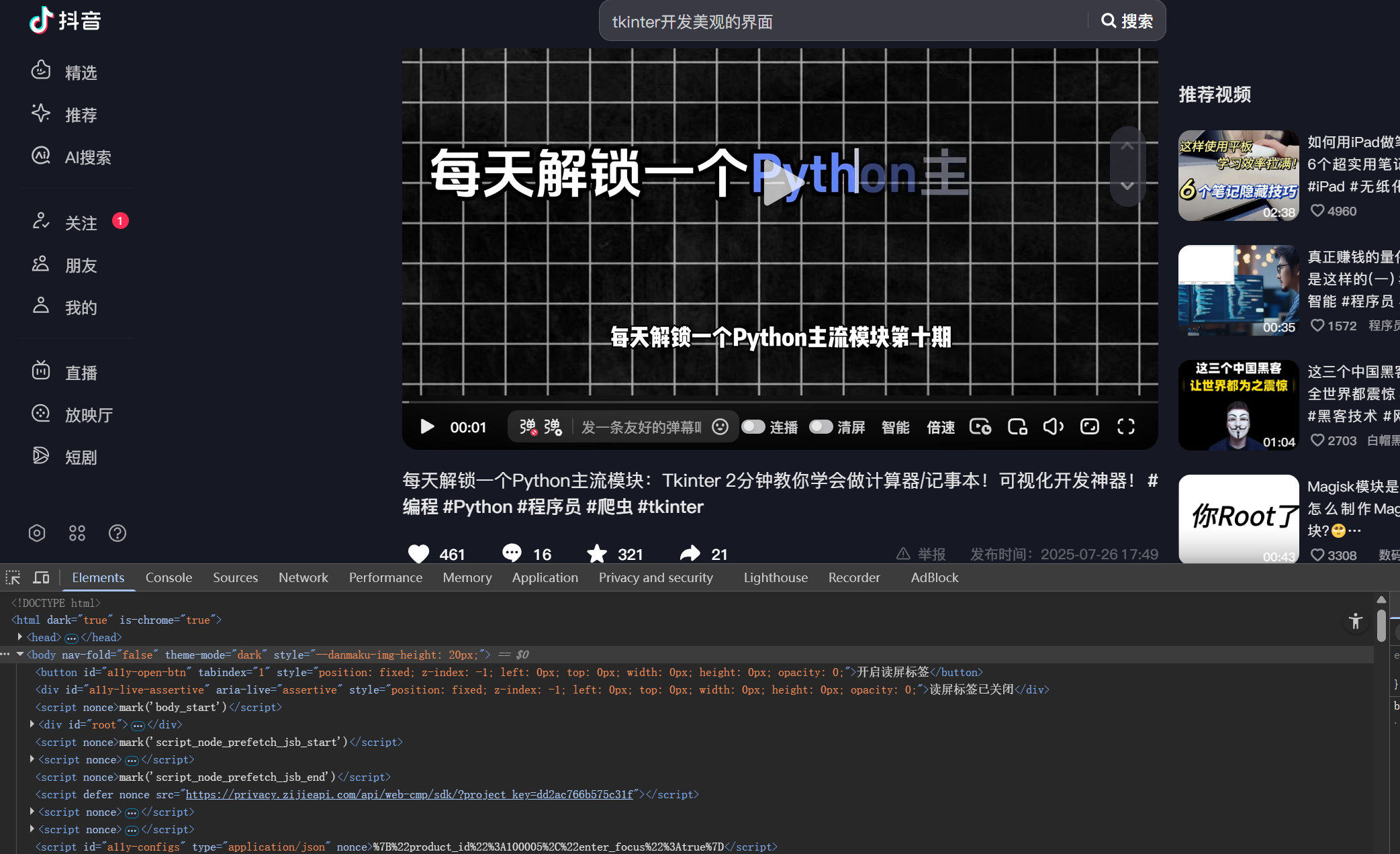
打开抖音,右键单击页面,在点击进入详情页。

在详情页中按F12或者右键单击页面空白处再点击检查(可能要等待响应一会儿)
可以看到我们这会儿是没有点赞的,然后单击network,(图中红色部分),然后点击黄色按钮,再进行点赞,然后立刻点击红色按钮以防止继续获取抓取数据导致数据过多
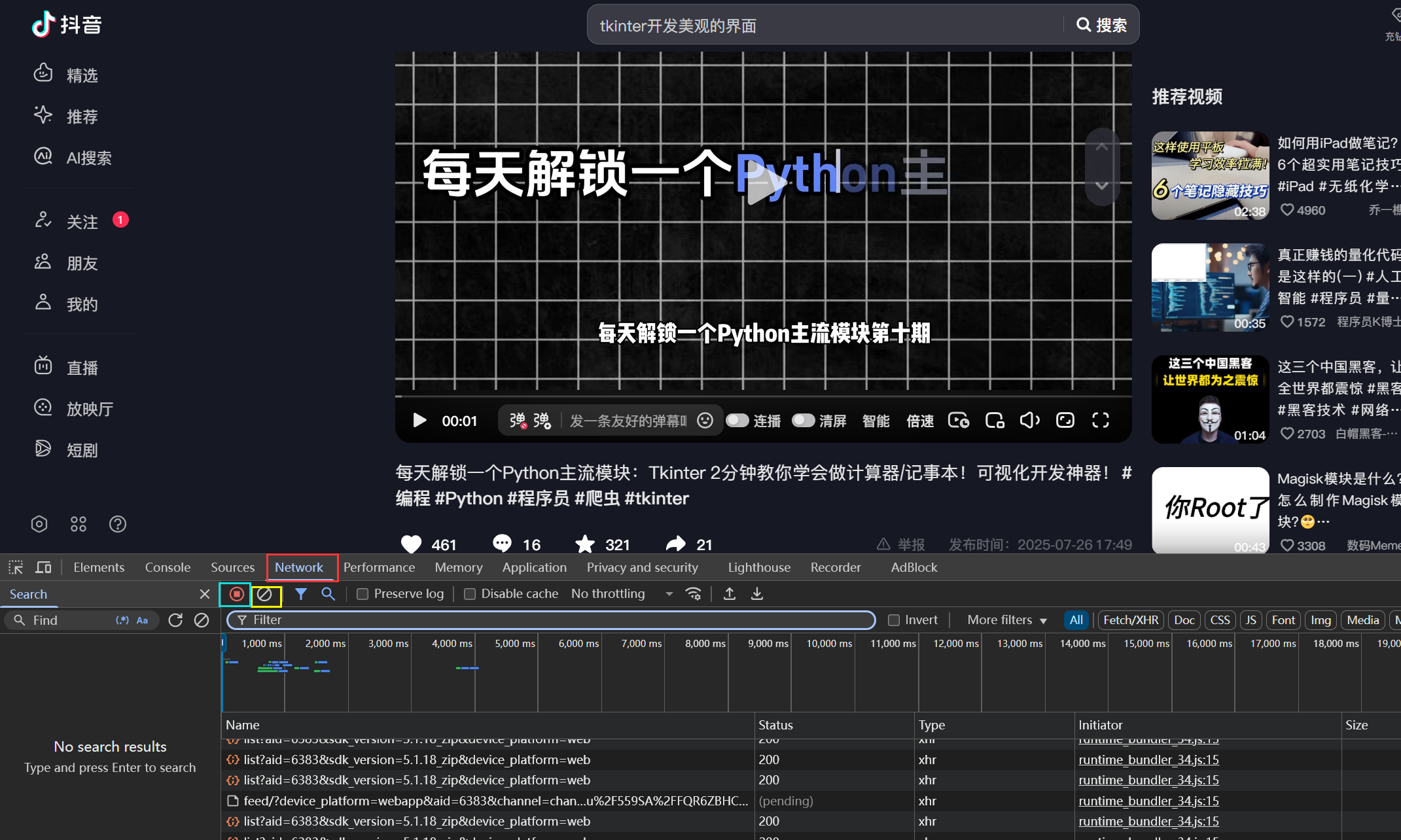

点赞的响应数据通常是digg开头的,list一般是评论之类的东西,我们单击图中以digg开头的响应数据,再点击preview简单看一下,应该没问题。
继续右键单击这条响应数据,找到Copy,然后找到Copy as cURL(bash),此时我们已经复制了需要传递的参数,然后回到刚才介绍的第三方平台,在红色区域中粘贴刚才复制的参数即可,下方黄色部分会返回给我们Python代码,然后复制这段Python代码,回到开发者工具中,在刚才创建的Python文件中粘贴代码即可(由于这段代码涉及个人数据,就不截图了),然后在抖音中取消我们刚才的点赞再运行文件就可看到点赞成功。
取消点赞的实现也同理,不再赘述。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了获取动态数据的第三方平台的使用,而获取动态数据往往是我们Python爬虫中经常遇到的情形,这为我们的Python爬虫提供了便捷。希望能帮助到你,若有不明之处也欢迎交流。


















 4592
4592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









