




第一章 Python 爬虫之验证码平台的使用
前言
在 Python 爬虫领域,Selenium 作为自动化测试工具的 “跨界应用”,早已成为处理动态网页和交互式场景的核心技术。然而,当面对网站的验证码防御体系时,即使是 Selenium 也常常陷入困境 —— 无论是传统的图形验证码、滑块拼图还是点选识别,这些看似简单的人机验证机制,实则是爬虫开发者绕不开的 “技术关卡”。如何高效、稳定地突破这些限制,成为爬虫项目能否落地的关键。验证码平台的出现,为这一难题提供了系统性解决方案。这类平台通过整合人工打码、AI 识别、机器学习等技术,将原本需要人工干预的验证码识别过程转化为 API 调用,从而实现 Selenium 自动化流程的无缝衔接。
一、验证码平台
目前主流验证码平台有结合超级鹰、CapSolver 等,这里介绍图鉴验证码平台:http://www.ttshitu.com/?spm=null
二、使用步骤
1.创建账号
按照指示步骤填写信息即可,首次使用的用户有十次免费验证的机会
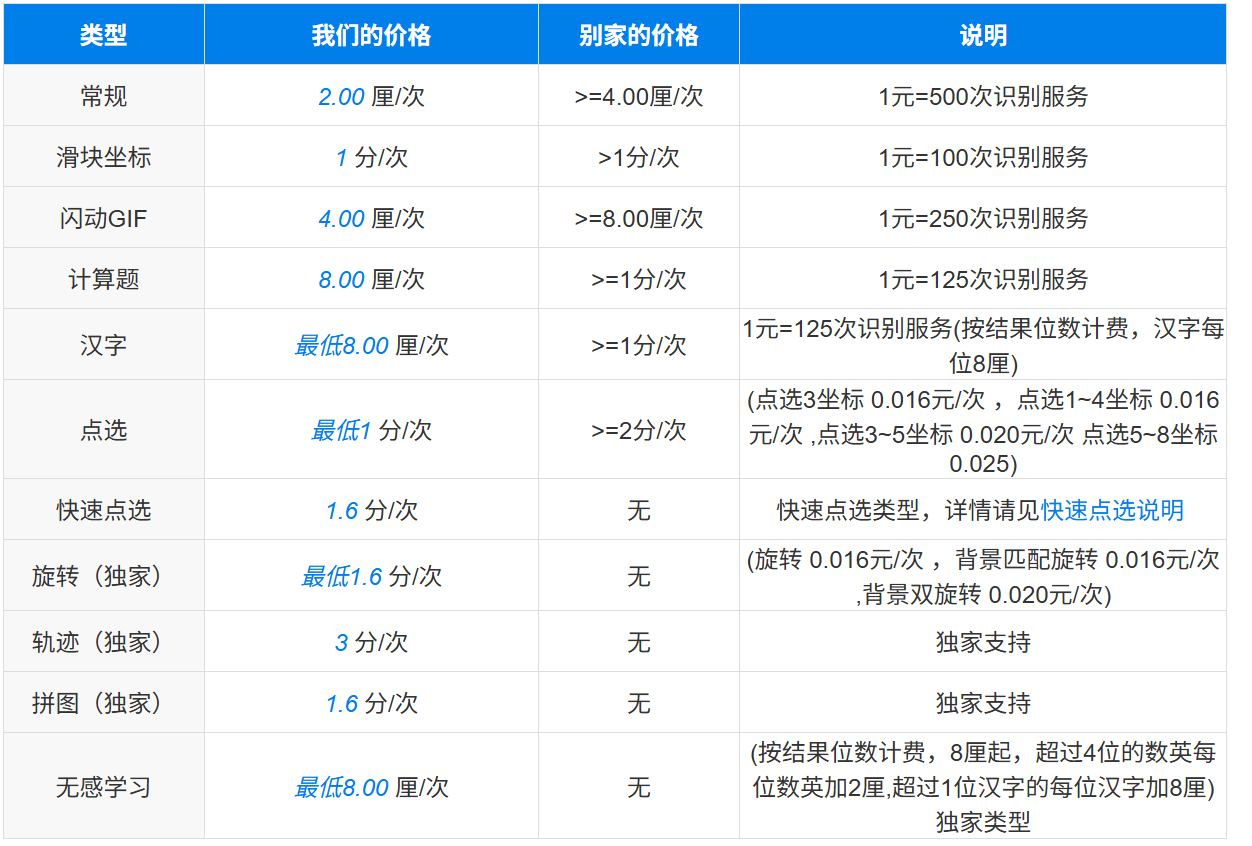
一元钱差不多就有一百次的识别服务,基本够用了。
2.基本使用方法
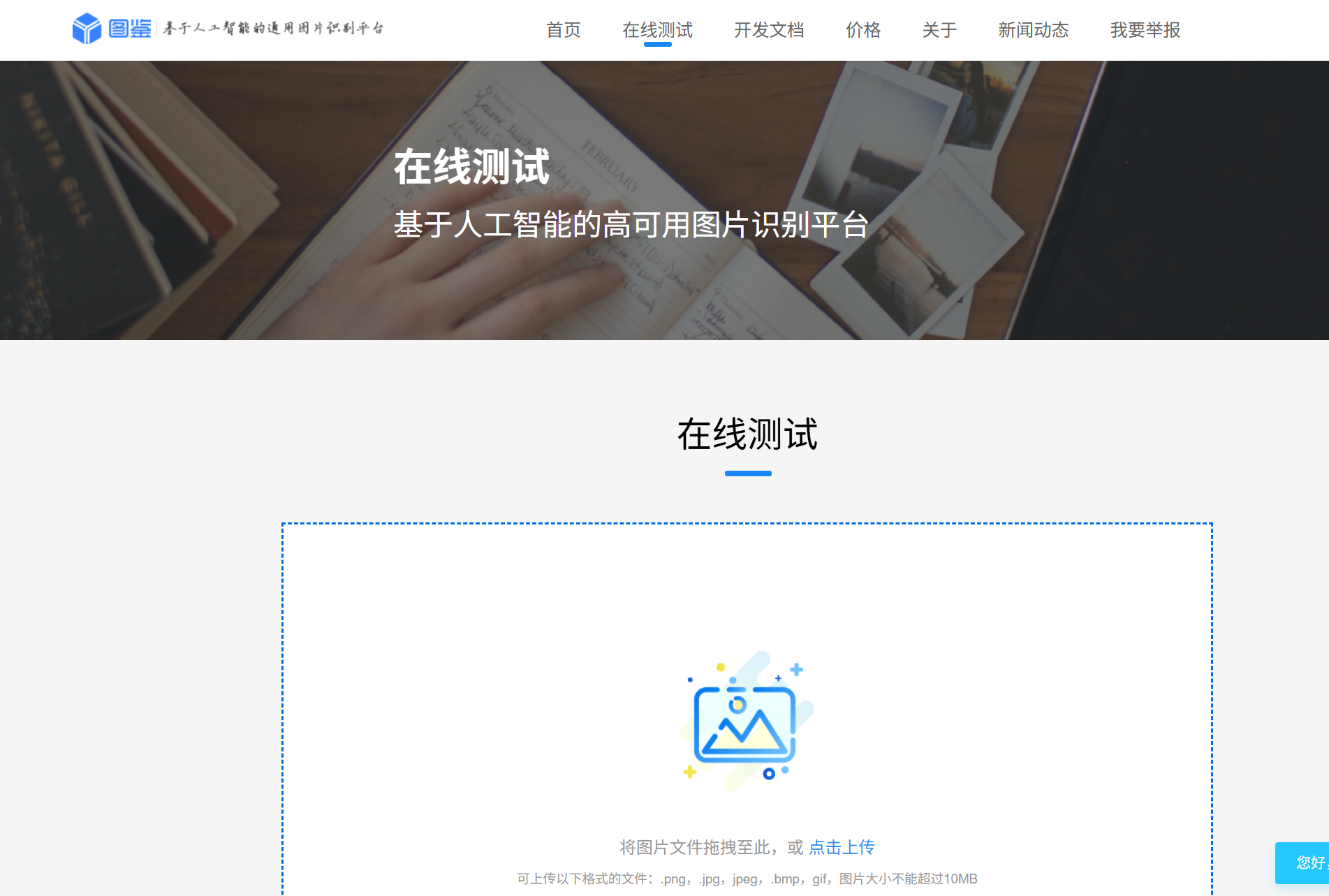
点击顶部在线测试,将图片拖入指定区域即可
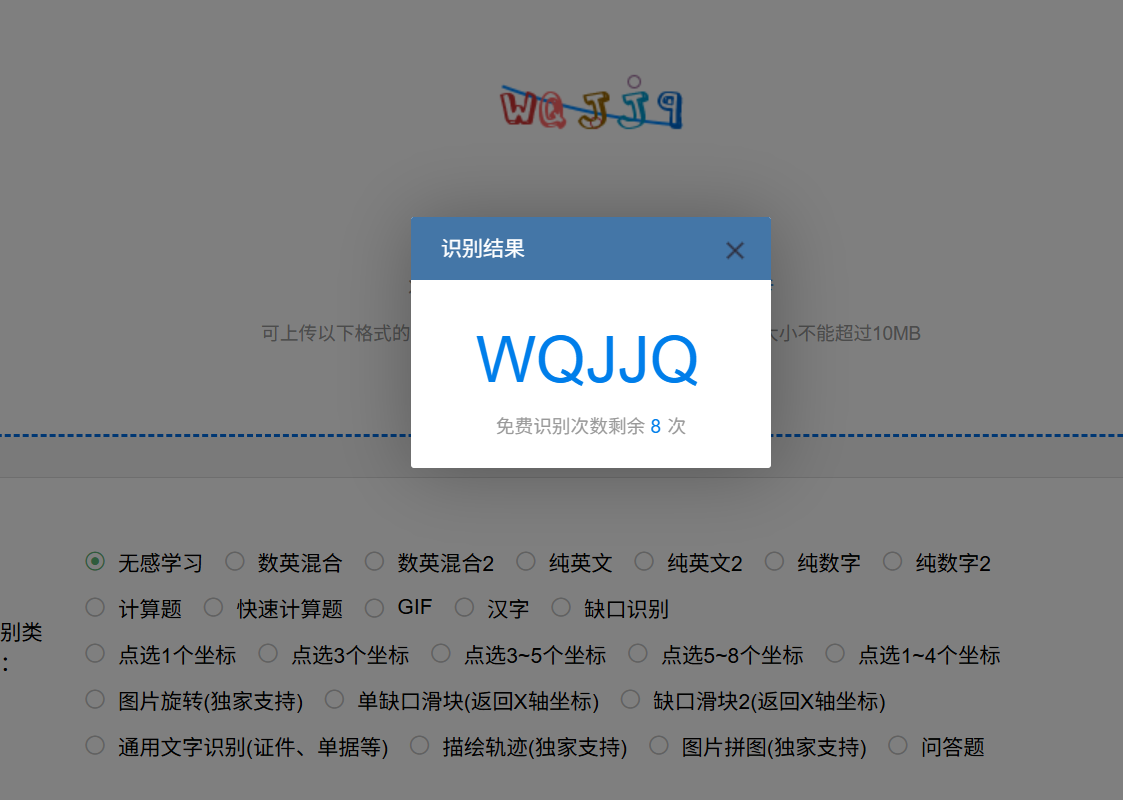
当然,识别平台也不是百分百识别准确,若识别错误,多尝试几次即可,一般验证码也是不区分大小写的。
三.在vscode中调用
我们回到验证码平台,进入开发者文档
下拉找到Python的脚本,复制全部脚本,粘贴到vscode中
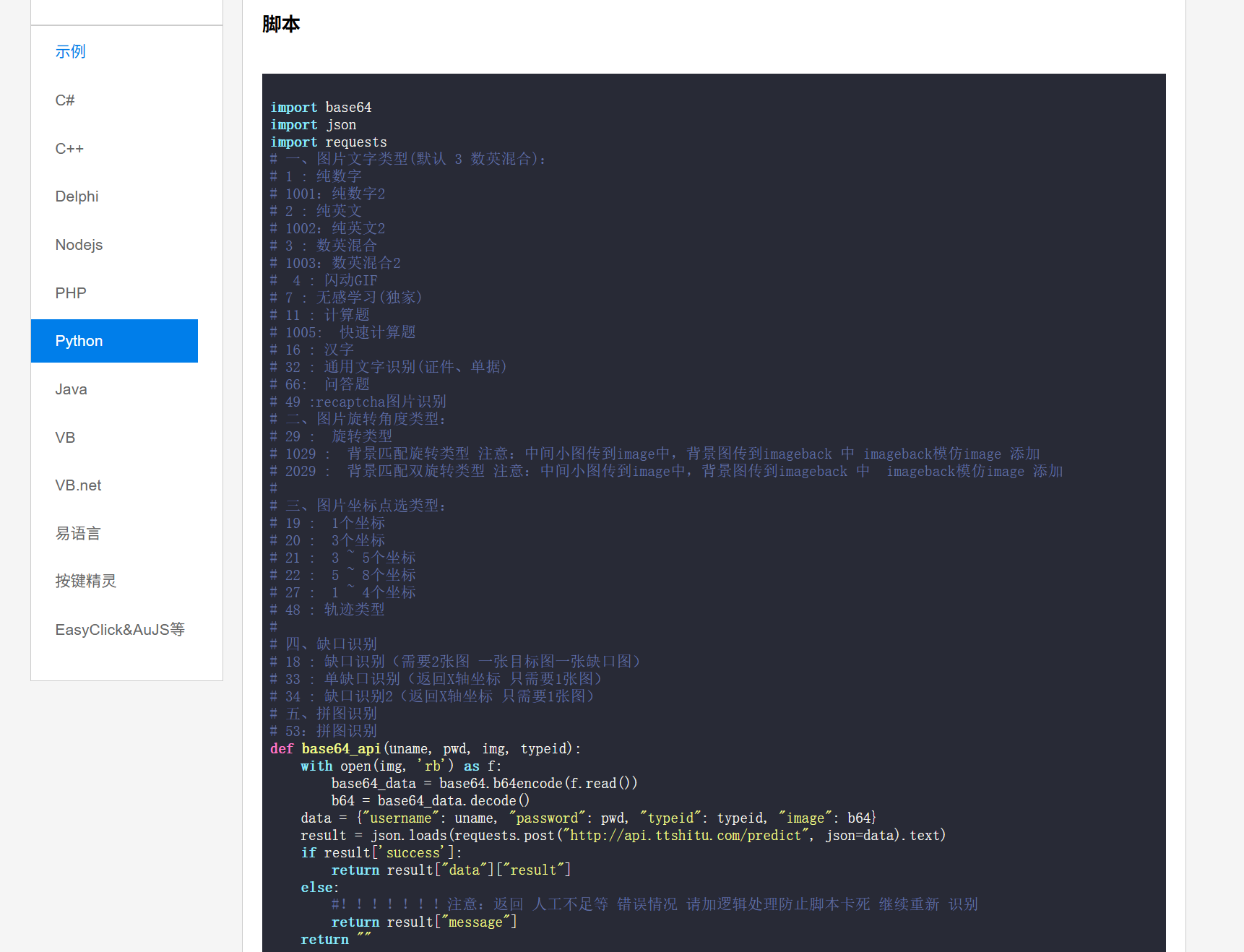
我们只需要在指定地方按照提示填入信息即可

img_path后面的地址改为需要验证的验证码图片的地址,result中填入自己的账号,密码,推荐将typeid后面的参数改为7(无感学习),是该平台独家的,较为好用。其他的都不用管,然后运行代码。
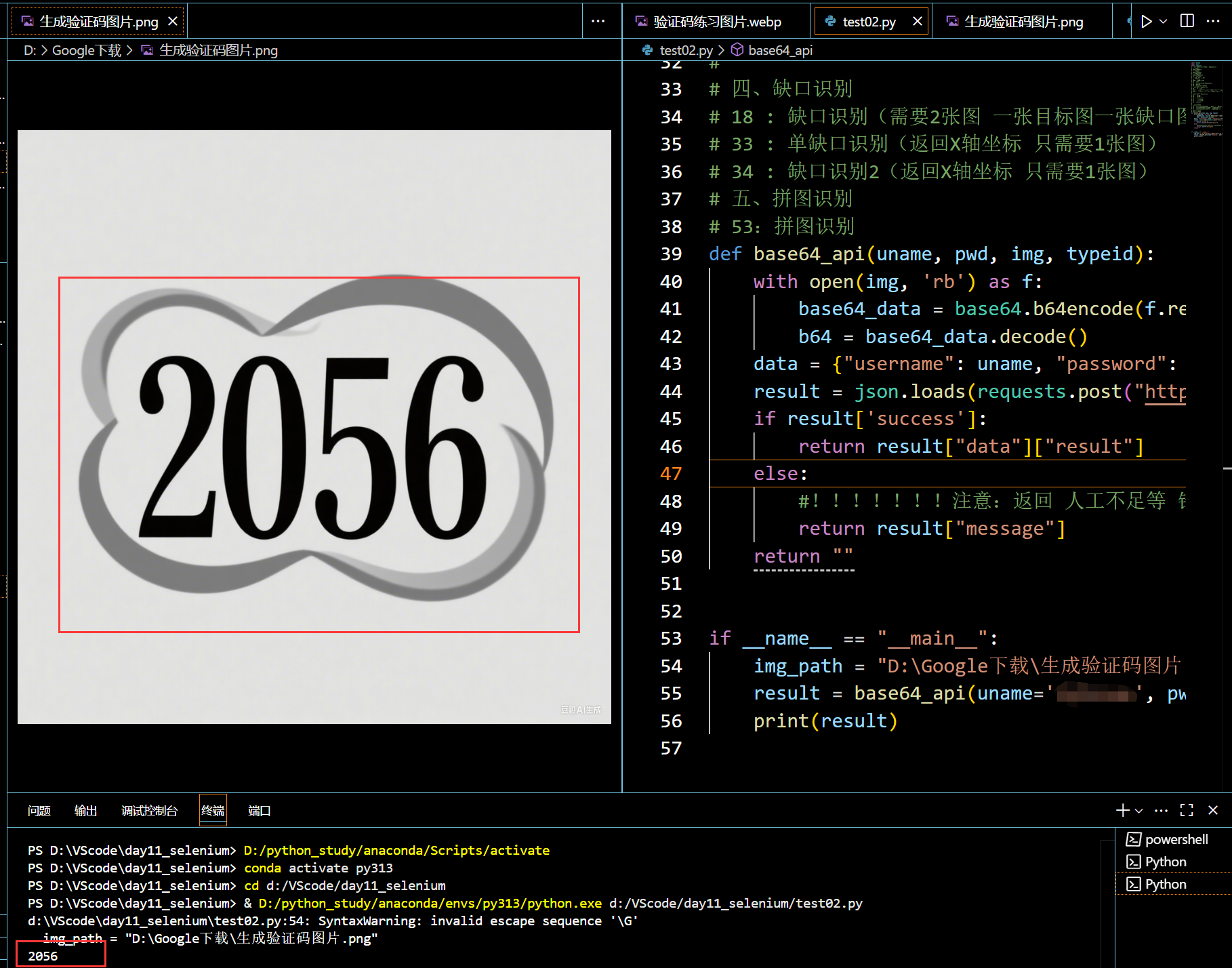
注意图片的格式,按要求上传(不能是.webp等),如图,整个验证码识别完成并正确
总结
需始终牢记的是,技术应用的边界在于合规。无论使用何种工具,均需以尊重网站 robots 协议、不破坏服务稳定性为前提。下一章节将继续讲selenium与验证码平台结合使用,希望能帮助到你,若有不足之处也请指出。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









