#coding:utf-8
import scrapy
import xlwt, lxml
import re, json
import matplotlib.pyplot as plt
import numpy as np
import pylab
from scipy import linalg
import sklearn
'''
Traditional Machine Learning Package
Supervised/Unsupervised/Reinforcement
分类和回归/聚类和压缩(降维)
sklearn
keras
xgboost
Deep Learning
PCA->t-SNE降维
The simplest Sklearn workflow
train_x(N*d),train_y(N*1),test_x,test_y=getData()
model=somemodel()【SVM() LASSO()...】
model.fit(train_x,train_y)
predictions=model.predict(test_x)
score=score_function(test_y,predictions)
'''
#sklearn.datasets--IRIS分类150个数据
from sklearn.datasets import load_iris
iris=load_iris()
dict_keys=iris.keys()
print(dict_keys)
#Digits(8*8)--MLIST<sklearn>
#MLIST(28*28)--<Tensorflow>
#Generating Synthetic Data
#from sklearn.datasets import make_...
# Unsupervised Transformer
# 1.transformer.fit(X_train)
#2.X_train_transf=transformer.transform(X_train)
#3.X_test_transf=transformer.transform(X_test)
# Feature Scaling--规范化
#Scikit-learn API
#TF-IDF
# Grid Search
#seanborn包--heatmap
#CNN
#1.local connectivity
#2.shared weights(parameter sharing)
#3.pooling & subsampling
#Word2vec
#Gennsinm包
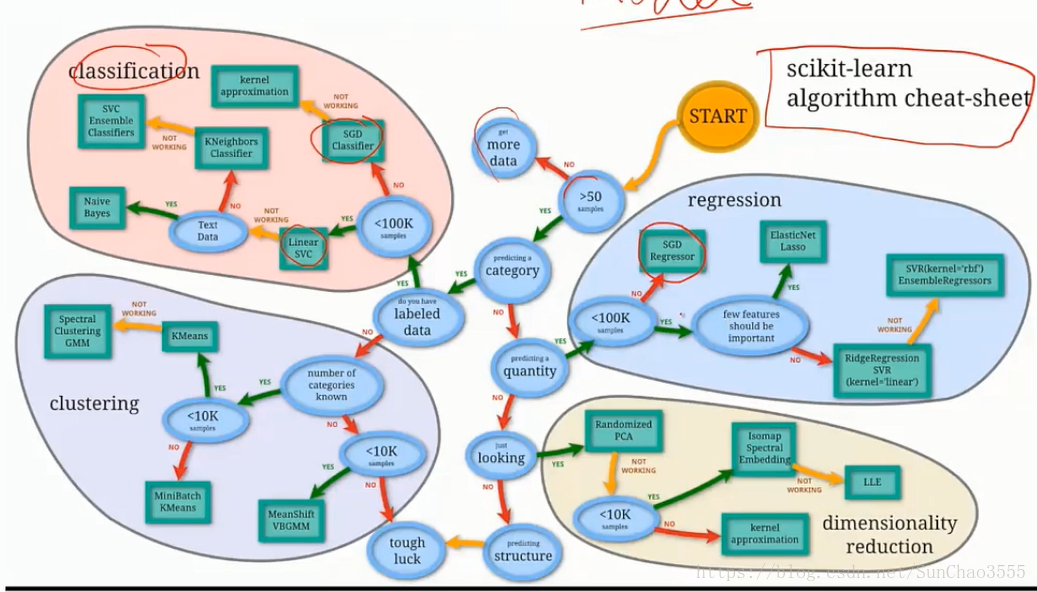








 本文介绍了机器学习和深度学习的基本概念,包括监督学习、无监督学习和强化学习等传统机器学习方法,并探讨了使用Python进行数据分析及模型训练的工作流程。此外,还涉及了一些常用的机器学习库如sklearn、keras和xgboost的应用。
本文介绍了机器学习和深度学习的基本概念,包括监督学习、无监督学习和强化学习等传统机器学习方法,并探讨了使用Python进行数据分析及模型训练的工作流程。此外,还涉及了一些常用的机器学习库如sklearn、keras和xgboost的应用。

















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









