



EmotiVoice的安装部署及其接口使用
前言
本文介绍linux系统安装EmotiVoice服务的流程,及在python代码中调用其接口的使用
一、EmotiVoice的下载安装
参考下面链接文章
https://mp.weixin.qq.com/s/kcVYp3EF52E3qD5qzpl9Og
代码开源地址:https://github.com/netease-youdao/EmotiVoice
方式一:Docker启动
第一种使用Docker启动,Docker镜像更新于2024年1月4号。如果你使用了老的版本,推荐运行如下命令进行更新:
docker pull syq163/emoti-voice:latest
docker run -dp 127.0.0.1:8501:8501 -p 127.0.0.1:8000:8000 syq163/emoti-voice:latest
方式二:本地部署
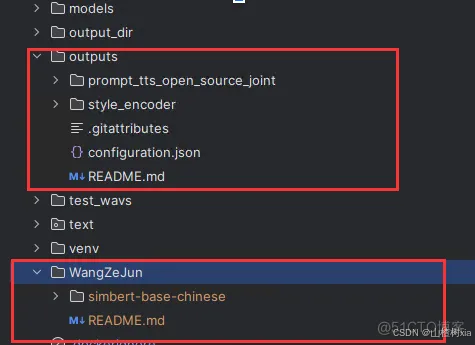
第二种安装方式涉及到的文件可以在下面链接中找到下载
https://www.modelscope.cn/models/syq163/WangZeJun/files
https://www.modelscope.cn/models/syq163/outputs/files
下载后文件放置具体位置如下
现在打开浏览器,导航到 http://localhost:8501 ,就可以体验EmotiVoice强大的TTS功能。
二、接口使用
1.python环境配置
从gitHub下载文件后,安装requirements.txt中的包
2.接口使用
从2024年的docker镜像版本开始,通过http://localhost:8000/可以使用类OpenAI TTS的API功能。
代码如下(示例):
import requests
# 准备请求的数据,这里以中文文本为例
data = {
'input': '你好世界,这是一段测试语音', # 要合成的文本
'voice': '8051',
'prompt': '',
'language': 'zh_us',
'model': 'emoti-voice',
'response_format': 'mp3',
'speed': 1.0
# 其他参数可以根据需要添加,如语速、音量等
}
# 发送请求到EmotiVoice的HTTP API
response = requests.post('http://localhost:8000/v1/audio/speech', json=data)
# 检查响应状态码
if response.status_code == 200:
# 成功,获取音频数据
audio_data = response.content
# 保存音频数据到文件
with open('output_audio.mp3', 'wb') as audio_file:
audio_file.write(audio_data)
print('音频文件已保存为 output_audio.mp3')
else:
# 错误处理
print('请求失败,状态码:', response.status_code)
一切无误的话,会生成output_audio.mp3文件
总结
我是在麒麟v10用docker部署的服务,由于硬盘容量限制第二种本地部署方式没有尝试,有兴趣的朋友可以自行尝试。

















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









