






 本文深入探讨了MySQL数据库中的MyISAM与InnoDB存储引擎的区别,包括事务支持、锁机制等方面。同时,详细介绍了索引类型如B+树和哈希索引,以及覆盖索引和回表的概念。还涵盖了事务隔离级别及其对锁的影响,以及如何通过间隙锁和下一键锁确保数据一致性。此外,讨论了数据库分库分表策略、数据归档的方法和主从同步原理,以及解决主从延迟的方案。
本文深入探讨了MySQL数据库中的MyISAM与InnoDB存储引擎的区别,包括事务支持、锁机制等方面。同时,详细介绍了索引类型如B+树和哈希索引,以及覆盖索引和回表的概念。还涵盖了事务隔离级别及其对锁的影响,以及如何通过间隙锁和下一键锁确保数据一致性。此外,讨论了数据库分库分表策略、数据归档的方法和主从同步原理,以及解决主从延迟的方案。
[大厂我来了]BAT500强-MySQL数据库索引夺命14问
大厂我来了]BAT500强-MySQL数据库索引夺命14问
1、说说MyISAM和InnoDB的区别?
- MySQL默认采用的是MyISAM。
- InnoDB支持事务,MyISAM不支持事务。
- InnoDB支持行锁和表锁,MyISAM不支持行锁,只支持表锁。
- InnoDB支持外键,MyISAM不支持外键。
- InnoDB的主键范围更大,最大是MyISAM的2倍。
- InnoDB不支持全文索引,而MyISAM支持全文索引。
- InnoDB是聚集索引,数据文件是和(主键)索引绑在一起,MyISAM是非聚集索引,索引和数据文件是分离的
- InnoDB不保存表的行数,执行select count(*) from table时需要全表扫描,而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件)
- MyISAM支持GIS数据(Point,Line,Polygon,Surface),InnoDB不支持。
2、说说MySQL的索引有哪些?
从数据结构角度
- B+树索引(O(log(n))):
- 一种特殊的平衡多路查找树。
- 非叶子节点只存储键值信息,不存储数据。
- 所有数据都存放在叶子节点中。
- 所有叶子节点之间都有一个指针相连,头尾也相连,形成闭合环状结构。
- hash索引:
- 仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。
- 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到叶子节点
- Hash 索引的查询效率要远高于 B-Tree 索引
从物理存储角度
- 聚集索引(clustered index)
- 一个表只能有一个聚集索引
- 聚集索引存储记录是物理上连续存在的
- 索引的叶节点就是数据节点
- 非聚集索引(non-clustered index)
- 一个表可以存在多个非聚集索引
- 非聚集索引物理存储不按照索引排序,改变时不影响整个表的物理存储顺序
- 非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块
从逻辑角度
- 主键索引:主键索引是一种特殊的唯一索引,不允许有空值
- 普通索引:针对某个列的简单索引
- 复合索引:复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
- 唯一索引:约定列的内容不能相同的索引
- 空间索引:只能在MyISAM引擎的非NULL时使用,是对空间数据类型的字段建立的索引
3、知道覆盖索引和回表吗?
覆盖索引并不是一种索引类型,准确的来说应该是一个动词。
覆盖索引指的是在一次查询中,如果一个索引包含所有需要查询的字段的值,我们就称之为覆盖索引,而不再需要回到表中去再查询额外的数据。
而要确定一个查询是否是覆盖了索引,我们只需要explain sql语句看Extra的结果是否是“Using index”即可。
所以为了提高查询效率,避免回表查询,建议给警察查询的字段、作为查询条件的字段、用作排序的字段都添加对应索引,可以是单列索引,也可以是复合索引。
4、联合索引的设计有哪些规则?
- 用于索引的列最好是那些出现在WHERE子句、JOIN子句、ORDER BY或GROUP BY子句中的列
- 最左前缀原则,在查询数据时从联合索引的最左边(第一个)开始匹配,把主键、唯一键、常量等放在最前面。
5、MySql中索引与锁有什么关系?
MyISAM 都是使用表锁,每操作一条记录就要锁定整个表,导致性能较低,并发不高。
所以一般关注的都是InnoDB的锁,InnoDB 采用了行级锁。也就是你需要修改哪行,就可以只锁定哪行。
在Mysql中,行级锁并不是直接锁数据记录,而是锁索引。
InnoDB 行锁是通过给索引项加锁实现的,如果一条sql 语句操作了主键索引,Mysql 就会锁定这条主键索引;
如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。
如果没有索引,InnoDB 会通过隐藏的聚簇索引来对记录加锁。
如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表级锁一样。
而锁又分为共享锁和排它锁,为了解决有锁的情况不能加锁,又有了意向共享锁和意向排它锁。
InnoDB针对UPDATE、DELETE和INSERT语句涉及的数据集加意向排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;
事务可以通过以下语句显示给记录集加锁:
- SELECT … LOCK IN SHARE MODE 添加共享锁
- 在读取的行上设置一个共享锁,其他的session可以读这些行,但在你的事务提交之前不可以修改它们。
- 如果这些行里有被其他的还没有提交的事务修改,你的查询会等到那个事务结束之后使用最新的值。
- SELECT … FOR UPDATE 添加排它锁
- 会锁住行及任何关联的索引条目,和执行 update 语句相同加锁相同。
- 其他的事务在对这些行执行 update 操作会被阻塞。
这样的锁又叫做悲观锁,悲观的认为总是会发生并发冲突。相对而言就有比较乐观的锁乐观锁,认为不太可能发生并发冲突问题。
乐观锁使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。
实现乐观锁常用方法:
-
版本号(version)
即为数据增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。
当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据,然后人为解决问题,如:重新读再写。
-
时间戳(timestamp):
和版本号基本一样,只是通过时间戳来判断而已,注意时间戳要使用数据库服务器的时间戳不能是业务系统的时间。
6、事务隔离级别对锁有没有影响?
默认情况下,MySQL用户执行的每一条SQL语句都会被当成单独的事务自动提交。
mysql 默认隔离级别是REPEATABLE-READ,oracle、sql server默认隔离级别是 read commited。
而锁本就是事务隔离级别的一种实现方式。
- 事务只能为自己获取或释放锁,不能为另一个事务获取释放锁。
- 事务隔离级别不会影响排它锁,修改数据会加排它锁,直到事务提交排它锁才会释放。
- 但是如果隔离级别是读未提交隔离级别有排它锁,但是其他事务可以读
- 事务隔离级别会影响共享锁,如:是否需要共享锁?拥有共享锁多长时间?锁定多大粒度的资源?
7、说说事务的隔离级别和特征?
事务四大特性
-
原子性(Atomicity)
事务包含的所有操作要么全部成功,要么全部失败回滚。
-
一致性(Consistency)
事务中无论读多少次,每次读取的数据都是一致的,哪怕其他事务已经修改了数据。
-
隔离性(Isolation)
多个事务之间互不干扰,一个事务也不能操作其他事务,每个事务独立正常运行。
-
持久性(Durability)
一个事务一旦被提交了,所有的操作都应是永久不变的,即使数据库发送错误。
-
Read uncommitted
读未提交,一个事务可以读取另一个未提交事务的数据,叫做脏读。
-
Read committed
读已提交,一个事务只能读取另一个事务已经提交的数据,所以在一个事务中多次读取同一个数据的结果不同,叫做不可重复读。主要是受到update的影响。
-
Repeatable read
可重复读,一个事务中读取同一个数据永远是相同的,即使后来被其他事务修改了,叫做可重复读,实现方式加锁或者版本号。但是会出现读的同时新增数据,读到结果不是全部结果,叫做幻读。
-
Serializable 序列化
事务串行化顺序执行,读写都加排它锁,可以避免脏读、不可重复读与幻读,效率低。
MySQL默认使用Repeatable read,所以主要分析一下Repeatable read隔离级别的特征。
- MySQL的InnoDB引擎下,同一事务内对同一个数据所有读取读取由第一次读取建立的 快照(副本),这样就能保证同一事务内的一致性。
- 为了达到一致性的目的,InnoDB使用使用 间隙锁或 next-key 锁 来为事务加锁。
- 对于锁定
SELECT(SELECT…FOR UPDATE或SELECT…LOCK IN SHARE MODE)、UPDATE和DELETE三种语句:- 如果搜索条件是唯一索引: 只锁定查找到的索引记录,而不锁定它之前的间隙。
- 其他范围类型搜索条件: 锁定扫描的索引范围,使用 间隙锁或 next-key 锁 来阻止其他会话插入范围所覆盖的间隙。
8、那你说说间隙锁和下一键锁?
-
间隙锁( gap lock)
一个用于锁当前匹配的索引记录之间所有next指针、第一个索引前next指针、最后一个索引后的next指针的锁。需要注意的是唯一索引是不会有间隙索引的。
-
下一键锁(next-key lock)
是记录锁(record lock)和间隙锁( gap lock)的组合,即锁间隙也锁索引记录。
9、说说你们是怎么分库分表?
- 垂直分库
- 微服务分库,一个服务一个库
- 垂直分表
- 如果表字段比较多,将不常用的放到一张表、数据较大的放到另一张表、扩展的放到扩展表。
- 水平分表
- 将最新的数据分离出新的表。
- 如:日订单1000万条,可以用user_id作为sharding_key,查询最近3个月的订单,超过3个月的做归档处理,那么3个月的数据量就是9亿,可以分1024张表,那么每张表的数据大概就在100万左右。查询数据的时候经过hash(user_id),然后对1024取模,就可以落到对应的表上了。
10、那你们是怎么实现数据归档的
根据某个时间点对数据表做归档。
在当前的数据库新建表用于存储历史数据,然后再对生产表做一个清理操作。
如果有条件的话可以把归档的数据放在一台新的数据库服务器上。
真正实时的时候,建议创建存储过程分页批量操作,并且创建时间,在夜间2点自动执行。
-
方法一: 复制表并且按照条件插入数据(此种方法除了主键索引不包括其他索引)
CREATE TABLE lime_survey_549656_20211001 as select * from lime_survey_549656 where submitdate < "2021-10-01 00:00:00"; ALTER TABLE lime_survey_549656_20211001 change id id int primary key auto_increment; -
方法二: 创建一张空表,结构和索引和原表一样
create table lime_survey_549656_20211001 like lime_survey_549656; INSERT INTO lime_survey_549656_20211001 select * from lime_survey_549656 where submitdate < "2021-10-01 00:00:00";
11、分表后的ID怎么保证唯一性的呢?
-
主键自增
-
设置步长,比如1024张表我们分别设定每张表的初始值和1024的基础步长,每张表的id就不会冲突,如:
1 + 1024 = 1025 2 + 1024 = 1026 ...
-
-
UUID
- 好处就是本地生成,不要基于数据库来了;
- 坏处就是,UUID 太长了、占用空间大,作为主键性能太差了;更重要的是,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作
-
分布式ID(雪花算法)
- 是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的 long 型的 id,1 个 bit 是不用的 + 用其中的 41 bit 作为毫秒数 + 用 10 bit 作为工作机器 id + 12 bit 作为序列号。
12、分表后非sharding_key的查询怎么处理呢?
-
可以做一个mapping表,比如这时候商家要查询订单列表怎么办呢?不带user_id查询的话你总不能扫全表吧?所以我们可以做一个映射关系表,保存商家和用户的关系,查询的时候先通过商家查询到用户列表,再通过user_id去查询。
-
打宽表,一般而言,商户端对数据实时性要求并不是很高,比如查询订单列表,可以把订单表同步到离线(实时)数仓,再基于数仓去做成一张宽表,再基于其他如es提供查询服务。
-
数据量不是很大的话,比如后台的一些查询之类的,也可以通过多线程扫表,然后再聚合结果的方式来做。。
List<Callable<List<User>>> taskList = Lists.newArrayList(); for (int shardingIndex = 0; shardingIndex < 1024; shardingIndex++) { taskList.add(() -> (userMapper.getProcessingAccountList(shardingIndex))); } List<ThirdAccountInfo> list = null; try { list = taskExecutor.executeTask(taskList); } catch (Exception e) {} public class TaskExecutor { public <T> List<T> executeTask(Collection<? extends Callable<T>> tasks) throws Exception { List<T> result = Lists.newArrayList(); List<Future<T>> futures = ExecutorUtil.invokeAll(tasks); for (Future<T> future : futures) { result.add(future.get()); } return result; } }
13、说说mysql主从同步原理
主从复制也叫MySQL Replication,是MySQL的原生功能,这也是最简单最有效的方式。
实现原理:
- master提交完事务后,将记录写入binlog(Binary Log)。
- slave连接到master。
- master创建dump线程,将binglog推送到slave。
- slave启动一个IO线程读取同步过来的master的binlog,记录到自己的relay log中继日志中。
- slave再开启一个sql线程读取relay log事件并在slave执行,完成同步。
- slave记录自己的binglog
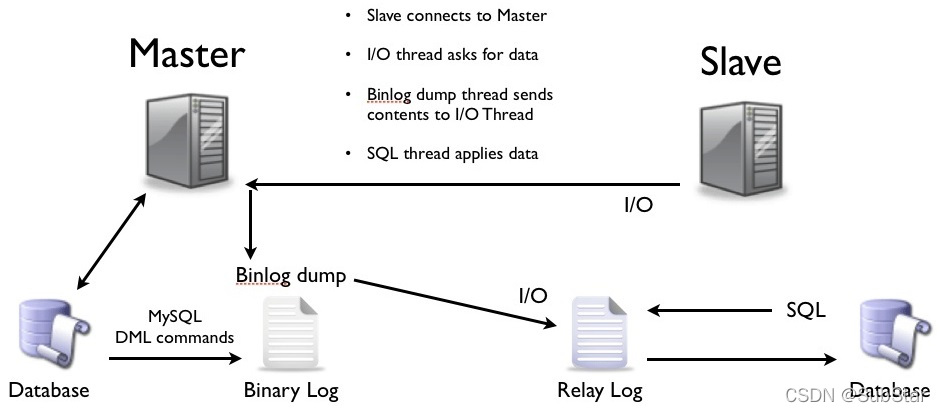
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
-
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
-
半同步复制
从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
14、那主从的延迟怎么解决呢?
所谓延迟原因,比如下面这些
- Slave需要同步的数据量大。
- slave的大型query语句产生了锁等待。
- 网络传输延迟。
MySql数据库从库同步的延迟解决方案
- 架构方面
- 业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
- 单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
- 服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
- 不同业务的mysql物理上放在不同机器,分散压力。
- 使用比主库更好的硬件设备作为slave总结,mysql压力小,延迟自然会变小。
- 硬件方面
- 采用好服务器,比如4u比2u性能明显好,2u比1u性能明显好。
- 存储用ssd或者盘阵或者san,提升随机写的性能。
- 主从间保证处在同一个交换机下面,并且是万兆环境。
- mysql主从同步加速
- sync_binlog在slave端设置为0
- –logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
- 直接禁用slave端的binlog
- slave端,如果使用的存储引擎是innodb,innodb_flush_log_at_trx_commit =2
相关参数说明
首先在服务器上执行show slave satus;可以看到很多同步的参数:
Master_Log_File: SLAVE中的I/O线程当前正在读取的主服务器二进制日志文件的名称
Read_Master_Log_Pos: 在当前的主服务器二进制日志中,SLAVE中的I/O线程已经读取的位置
Relay_Log_File: SQL线程当前正在读取和执行的中继日志文件的名称
Relay_Log_Pos: 在当前的中继日志中,SQL线程已读取和执行的位置
Relay_Master_Log_File: 由SQL线程执行的包含多数近期事件的主服务器二进制日志文件的名称
Slave_IO_Running: I/O线程是否被启动并成功地连接到主服务器上
Slave_SQL_Running: SQL线程是否被启动
Seconds_Behind_Master: 从属服务器SQL线程和从属服务器I/O线程之间的时间差距,单位以秒计。
从库同步延迟情况出现的
show slave status显示参数Seconds_Behind_Master不为0,这个数值可能会很大
show slave status显示参数Relay_Master_Log_File和Master_Log_File显示bin-log的编号相差很大,说明bin-log在从库上没有及时同步,所以近期执行的bin-log和当前IO线程所读的bin-log相差很大
mysql的从库数据目录下存在大量mysql-relay-log日志,该日志同步完成之后就会被系统自动删除,存在大量日志,说明主从同步延迟很厉害


















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











