



MiroThinker发布第一个版本时,高难度基准测试表现超GPT5,作为深度研究模型,实现了单次任务多达600次工具调用。
刚刚,MiroThinker发布v1.5,登顶最强搜索智能体。
MiroThinker v1.5通过交互式扩展这个维度,在30B与235B参数规模下打破了单纯依赖模型尺寸的传统定律,重新定义了智能体在复杂环境中的推理与搜索能力。
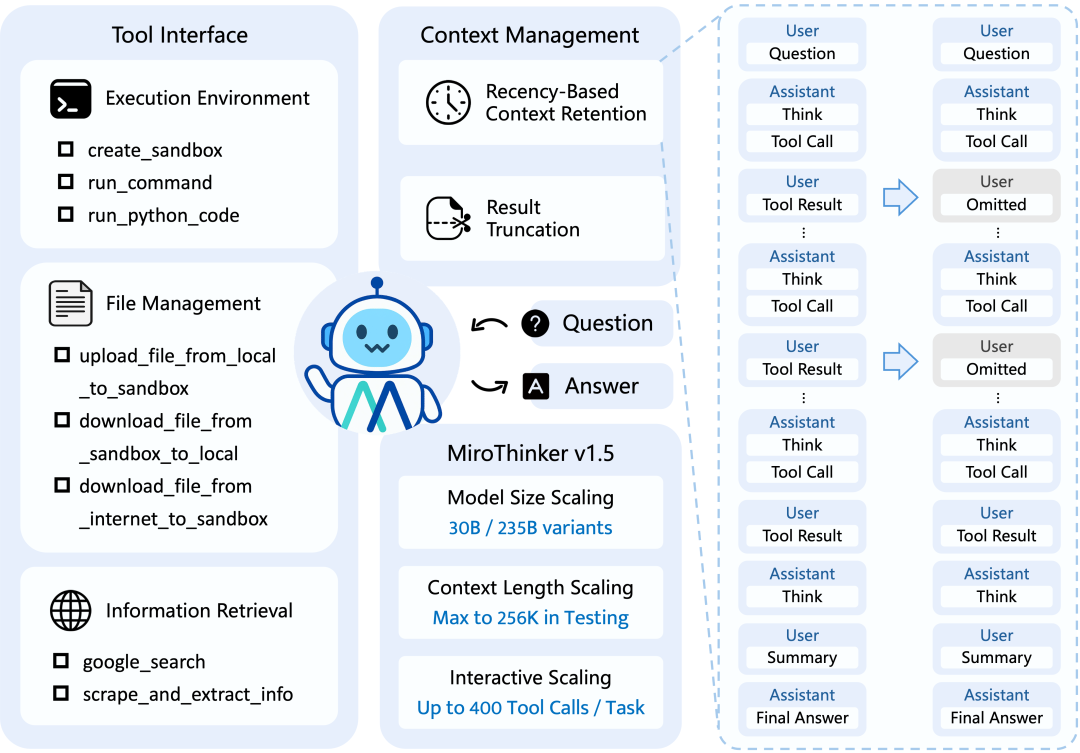
MiroThinker v1.5推进了工具增强型推理和信息检索能力的发展,它不再局限于传统的模型参数堆叠,而是开创了一条通过环境交互来提升智能的新路径。
交互式扩展
MiroThinker v1.5引入了交互式扩展(Interactive Scaling)这一核心概念,将其作为模型性能提升的第三个关键维度,这与以往那些仅在模型大小或上下文长度上做文章的智能体形成了鲜明对比。
交互式扩展的本质在于系统性地训练模型,使其能够处理更深层次、更高频次的智能体与环境之间的交互。
这种扩展方式模拟了人类在解决陌生问题时的认知过程,即通过不断的试错和反馈来修正路径。
MiroThinker利用环境反馈和外部信息获取来纠正错误并优化推理轨迹。
在传统的模型训练中,模型往往是一次性生成的,而在交互式扩展的框架下,模型学会了在输出结果之前进行多轮的自我审视和外部验证。
这种机制使得模型在面对复杂问题时,能够像一个严谨的研究员一样,通过多步操作来逼近真相,而不是简单地基于概率生成一个似是而非的答案。
实证结果充分证明了这种交互式扩展的有效性。
随着模型与环境交互的深度和频率增加,其在多个基准测试中的性能呈现出可预测的提升趋势。
这表明,智能能力的提升不再仅仅依赖于计算资源的堆砌,更取决于模型如何有效地利用外部工具来延伸其认知边界。
MiroThinker v1.5支持256K的上下文窗口,这为其进行长程推理(Long-horizon Reasoning)提供了充足的记忆空间。它能够处理深度多步分析,并在单次任务中处理高达400次的工具调用(Tool Calls)。
400次工具调用意味着模型可以在一个任务中进行数百次的搜索、浏览、代码执行和数据对比,这种高强度的交互能力使得它能够胜任那些需要极高耐心和细致程度的科研级任务。
无论是梳理庞大的法律文档,还是追踪复杂的金融链路,MiroThinker都能通过这种高频交互保持逻辑的连贯性和目标的准确性。
搜索与推理新高度
在衡量智能体综合能力的各项基准测试中,MiroThinker v1.5展现出了令人瞩目的通用研究性能。
它在多个高难度榜单上均取得了世界领先的成绩,特别是在浏览与搜索相关的任务中,其表现甚至超越了部分闭源模型。
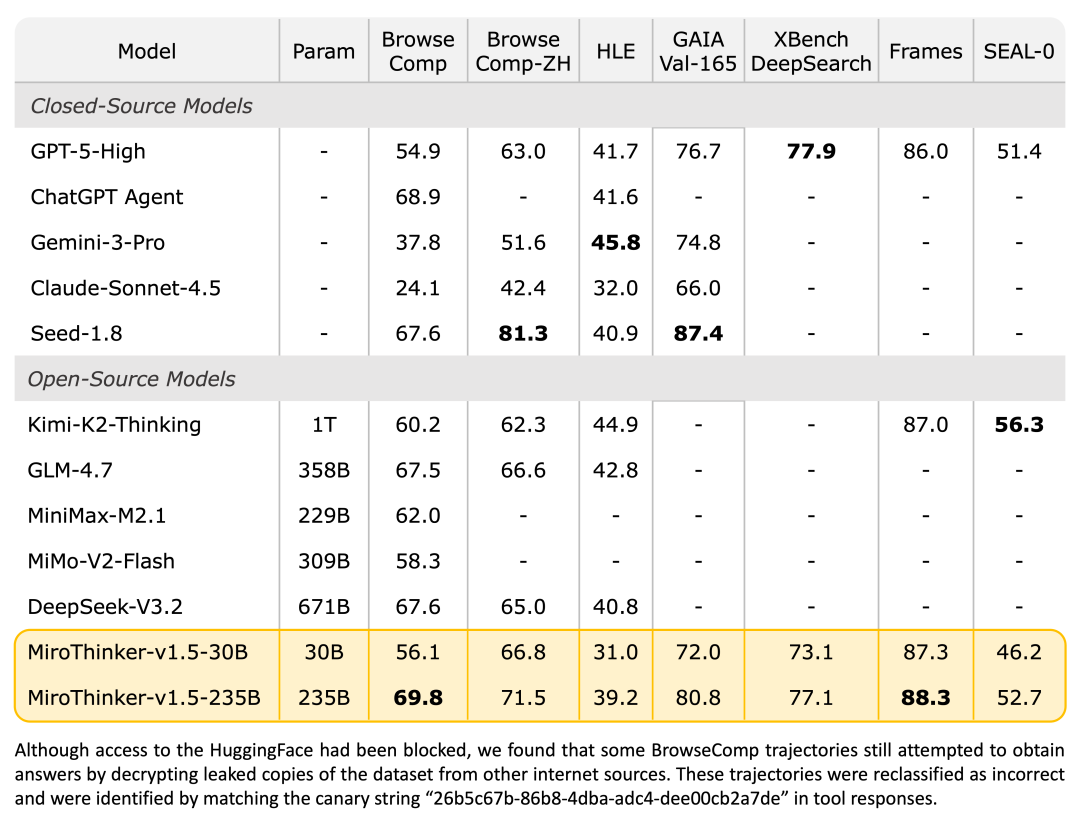
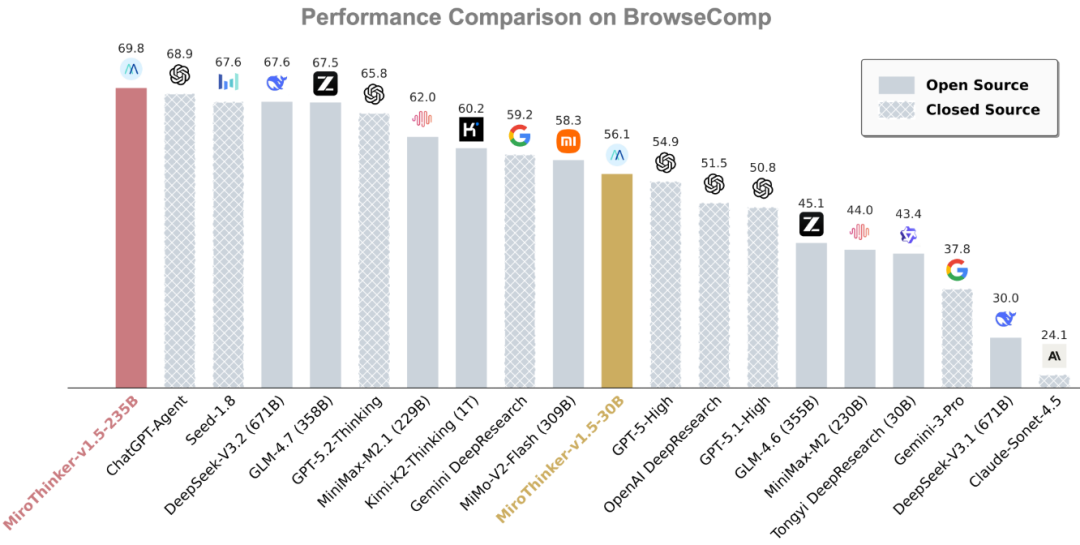
MiroThinker v1.5在HLE、BrowseComp、GAIA等多个权威基准测试中超越了GPT-5-High、Gemini-3-Pro等顶尖模型。
HLE(Humanities & Law Exams)主要测试模型在人文与法律领域的长文本理解与逻辑推理能力,这是一个对准确性和上下文关联度要求极高的领域。
在BrowseComp和BrowseComp-ZH这两个专注于网页浏览和信息检索的基准上,MiroThinker分别取得了69.8%和71.5%的高分。
在GAIA-Val-165基准测试中,MiroThinker v1.5更是达到了80.8%的得分。GAIA(General AI Assistants)是一个极具挑战性的基准,旨在评估通用AI助手在解决现实世界复杂问题时的能力。
MiroThinker v1.5发布了30B和235B两个参数规模的版本。
30B版本基于Qwen3-30B-A3B-Thinking-2507微调,适合资源受限但追求高效率的场景;而235B版本基于Qwen3-235B-A22B-Thinking-2507,旨在提供极致的推理能力和任务处理深度。
双版本的策略,配合一套全面的工具和工作流,灵活地支持了多样化的研究设置和计算预算,使得无论是个人开发者还是大型研究机构,都能找到适合自己的智能体解决方案。
架构设计支撑长程复杂任务
MiroThinker v1.5的强大不仅源于其训练理念的革新,更离不开其底层架构对工具使用(Tool Use)和复杂工作流的精心设计。
为了实现高效的智能体与环境交互,模型采用了一套标准化的XML包裹JSON的格式来描述和组织所有工具。这种设计确保了模型在解析指令和执行操作时的一致性与兼容性。
在推荐的系统提示词(System Prompt)中,MiroThinker被定义为一个拥有特定工具集的高级AI助手。
它必须严格遵守“一次一步”的原则,即每条消息只能使用一个工具,并根据上一个工具的执行结果来决定下一步的操作。这种步步为营的策略,有效地避免了幻觉的产生,确保了推理过程的扎实可靠。
模型支持MCP,通过MCP,MiroThinker可以调用诸如tool-python服务器下的create_sandbox(创建沙箱)和run_python_code(运行Python代码)等功能。
例如,在处理数据分析任务时,模型可以先申请一个Linux沙箱,设定超时时间,然后在这个安全隔离的环境中运行Python代码,并获取标准输出或错误信息。这种沙箱机制极大地提升了执行代码类任务的安全性和稳定性。
此外,MiroThinker还集成了强大的搜索与抓取能力。
通过search_and_scrape_webpage服务器下的google_search工具,模型可以执行精细化的网络搜索。
它不仅支持基础的查询字符串,还能通过gl(地区)、hl(语言)、tbs(时间过滤器)等参数来精准定位信息。
对于搜索到的网页,模型可以利用jina_scrape_llm_summary服务器下的scrape_and_extract_info工具,直接从URL中抓取内容并利用大语言模型(LLM)提取特定信息。这种从搜索到抓取再到提取的一条龙服务,正是其在BrowseComp基准上取得高分的关键技术支撑。
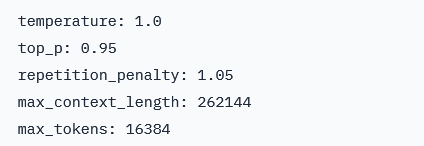
对于本地部署,官方推荐使用SGLang或vLLM框架。推理参数推荐:
MiroThinker v1.5的交互式扩展、强大的工具链集成以及灵活的部署方案,助力开发者构建自己的定制化专属智能体系统。
参考资料:
https://huggingface.co/miromind-ai/MiroThinker-v1.5-235B
https://huggingface.co/miromind-ai/MiroThinker-v1.5-30B
https://github.com/MiroMindAI/MiroThinker


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









