



大语言模型的层级计算序列精确映射了人类大脑处理语言的毫秒级时间动态。

普林斯顿大学,谷歌研究,纽约大学,哈佛大学等,研究通过对比人类颅内脑电数据与大语言模型的内部状态,发现人工智能处理语言的深浅层级,与人类大脑理解语言的先后时间顺序存在惊人的高度一致性。
AI精确镜像了人类思维的时间流
大语言模型的出现为理解人类大脑如何处理自然语言提供了全新的计算框架。
传统的心理语言学模型长期依赖于对符号表征的规则操作,通过层级树结构来解析语言。
大语言模型截然不同,它将词汇及其上下文编码为连续的数值向量,即嵌入(Embedding)。
这些嵌入通过层层非线性变换构建,生成了复杂的语言结构表征。
这种层级化的模型结构及其产生的表征,让机器具备了翻译和类人文本生成的能力。
大语言模型体现了语言处理的三个基本原则:基于嵌入的词汇上下文表征、下一个词的预测以及基于误差修正的学习。
神经科学研究已经开始在人脑中寻找这些计算原则的神经相关物。
源自大语言模型的上下文嵌入为预测自然语言处理过程中的神经反应提供了强大的模型。
例如,下额叶回(IFG)的神经反应似乎与特定模型(如GPT-2 XL)的上下文嵌入保持一致。
自发的词前预测现象已在人类大脑的电生理和成像研究中被发现,这些预测与模型的预测高度吻合。
对于意外出现的词汇,语言区域会表现出神经活动的增强,这表明大脑在理解语言时存在误差反应。
这些结果凸显了大语言模型作为人类语言理解认知模型的潜力。
研究的核心在于探索大语言模型实现的序列化层级过程是否与人类大脑理解语言的神经时间动态共享同一套逻辑。
换句话说,当人类聆听自由语音时,大脑内部的时间动态是否遵循模型诱导的层级结构。
研究利用了皮层电图(ECoG)卓越的时空分辨率,证明了人脑处理口语叙事的内部时间进程,与大语言模型中非线性逐层变换的内部序列相匹配。
研究团队在受试者聆听30分钟口语叙事时,记录了沿颞上回和下额叶回(IFG)的语言区域的神经活动。
研究人员将同样的叙事输入到高性能的大语言模型中,并提取了模型所有层级中每个词的上下文嵌入。
通过使用GPT-2 XL来展示大语言模型与大脑之间的基本相似性,并将结果推广到开源模型Llama-2,支持了模型与大脑处理语言方式之间存在关键相似性的论点。
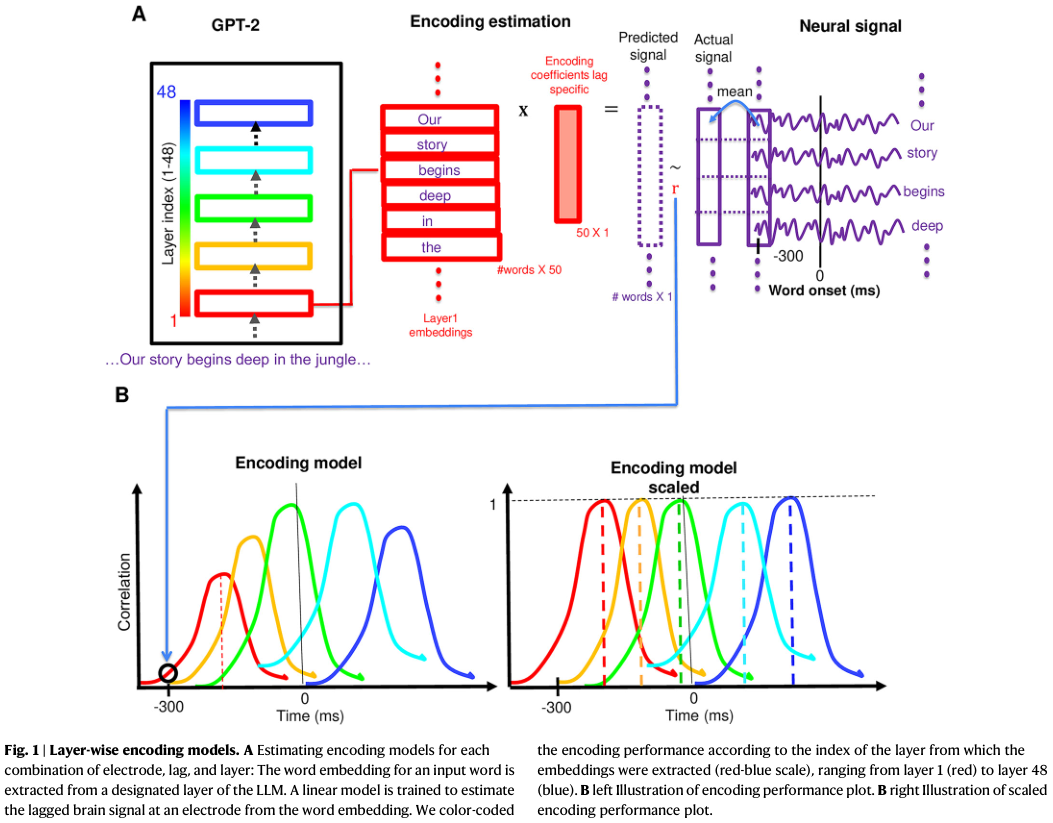
研究人员将大语言模型层级间的内部嵌入序列映射到人类受试者在自然语言理解过程中记录的神经反应上。
为了进行这种比较,研究测量了线性编码模型的性能,这些模型被训练用于根据每一层的嵌入来预测随时间演变的神经活动。
性能指标是真实神经信号与编码模型预测的神经信号之间的相关性。
在下额叶回(IFG)内,编码结果观察到了一个清晰的时间序列:较浅层的模型层级在词汇出现初期达到编码性能峰值,而较深层的模型层级则在更晚的时间点达到峰值。
这一发现表明,大语言模型层级间的变换序列映射到了高级语言区域信息处理的时间动态上。
大语言模型的空间层级结构可以被用来模拟语言理解的时间动态。
随后,这一分析被应用到语言处理层级中的其他区域,验证了信息随着时间尺度增加而累积的现有理论,即从听觉区域向句法和语义区域层级递进。
中间层级最能预测皮层活动的发现得到了复现。
ECoG记录所带来的更高时间分辨率揭示了大语言模型嵌入的逐层序列与自然语言理解过程中皮层活动的时间动态之间的精确对齐。
这项研究通过展示大语言模型中的逐层计算序列与自然语言处理过程中人脑电活动之间的联系,为大语言模型与人类大脑共享计算原则提供了有力证据。
从听觉皮层到布罗卡区的动态神经映射
研究团队收集了9名癫痫患者的皮层电图(ECoG)数据,其中7名患者的电极位于预定义的感兴趣区域(ROI)。
患者聆听了一段30分钟的音频播客("Monkey in the Middle", NPR 2017)。
神经数据经过预处理以反映高伽马波段信号。之前的研究通常从GPT-2 XL的最终隐藏层提取嵌入来预测大脑活动,并发现这些上下文嵌入优于静态(即非上下文)嵌入。
在此基础上,本研究通过使用从GPT-2 XL和Llama-2的所有隐藏层提取的上下文嵌入,对播客中每个词的神经反应进行了建模。
研究聚焦于沿腹侧语言处理流的四个区域:拥有28个电极的中部颞上回(mSTG)、13个电极的前部颞上回(aSTG)、46个电极的下额叶回(IFG)以及6个电极的颞极(TP)。
所选电极均显示出对静态GloVe嵌入具有显著的编码性能。
鉴于先前的研究报告称,对于大语言模型正确预测的词汇,编码结果有所改善,研究分别对正确预测和错误预测的神经反应进行了建模。
如果GPT-2 XL将最高概率分配给实际出现的下一个词,则认为预测正确。播客中有1709个这样的词,被称为“前1预测”或“预测词”。
对于下额叶回(IFG)中的每个电极,研究针对GPT-2 XL的每一层(1-48层)在每个滞后时间(-2000毫秒至2000毫秒,以25毫秒为增量)进行了编码分析。
随后,将IFG内所有电极的编码性能进行平均,得到每一层的单一平均编码时间进程。
通过对电极和滞后时间进行平均,获得了每一层的平均编码性能。显著性评估使用了自举重采样法。
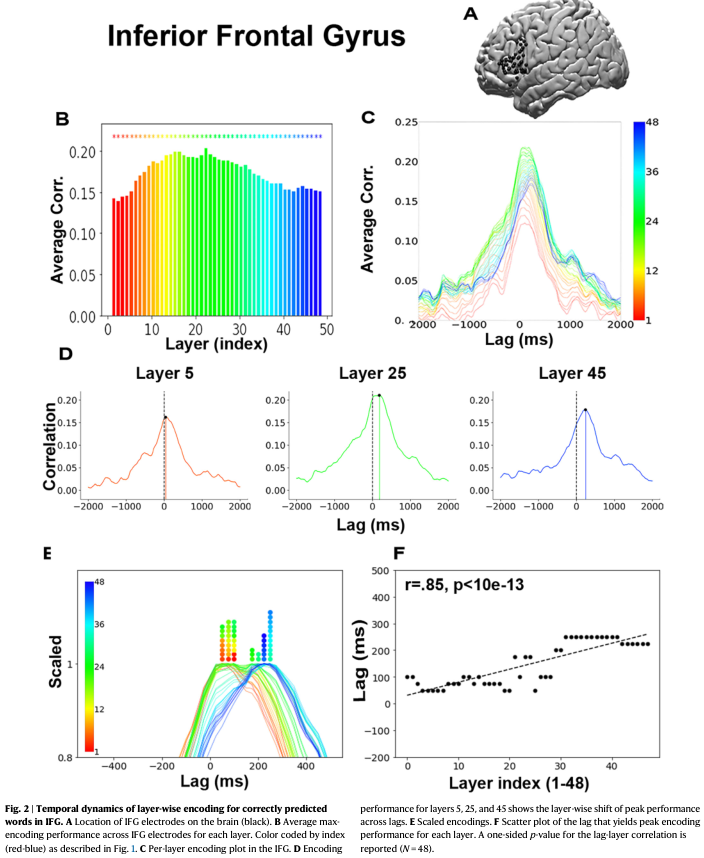
在IFG中,编码模型的峰值平均相关性出现在中间层第22层。
这印证了功能磁共振成像(fMRI)的近期发现,即编码性能在中间层达到峰值,呈现倒U型曲线。
ECoG记录的精细时间分辨率揭示了一个特定的动态模式。
所有48层在IFG中都产生了稳健的编码,在4000毫秒窗口的边缘编码性能接近于零,而在词汇出现前后性能增强。
观察每一层的编码结果随滞后时间的变化,揭示了一个有序的动态过程:早期层级(如第5层,红色)的峰值编码性能倾向于先于中间层级(如第25层,绿色),随后是晚期层级(如第45层,蓝色)。
为了可视化这种跨滞后时间的时间序列,研究将每一层的编码性能归一化,使其峰值性能缩放为1。
为了定量验证这一主张,研究计算了层级索引(1-48)与产生该层峰值相关性的滞后时间之间的皮尔逊相关系数。
这产生了一个强显著的正相关(r=0.85,p < 10e-13)。
这种程序产生的结果被称为“滞后-层级相关性”。使用斯皮尔曼相关性也获得了类似的结果(r=0.80)。
研究还进行了非参数分析,将层级索引置换100,000次(保持产生峰值相关性的滞后时间固定),并将滞后时间与这些打乱的层级索引相关联。
使用这种相关性的零分布,计算了实际相关性的百分位,得到了p < 10e-5的显著性。
使用Llama-2复现了结果,支持了大语言模型诱导的层级结构与人脑之间普遍相似性的主张。
尽管观察到层级索引与该层峰值相关性滞后时间之间存在稳健的对应关系,但某些层级组在相同的滞后时间达到了最大相关性。
这种非线性可能是由于GPT-2 XL的48层与各个语言区域内的转换之间匹配的不连续性造成的。
这也可能是由于ECoG测量的时间分辨率虽然很高,但仍是以50毫秒的分辨率进行分箱的。更高分辨率的数据可能会区分这些层级。
大语言模型的中间层比早期或晚期层能更好地拟合神经信号。
中间层嵌入在各个滞后时间上始终优于其他层。
回归分析确定,大脑活动与早期及晚期层嵌入之间的相关性并非源于它们与“最佳”中间层(第22层)的相似性。
显著的相关性归因于它们独立编码的独特信息。这一发现强调了每一层嵌入对理解语言理解神经动态的独立和独特贡献。
研究比较了另外三个语言感兴趣区域的时间编码序列:从接近早期听觉皮层的mSTG开始,沿着腹侧语言流向上移动到aSTG和TP。
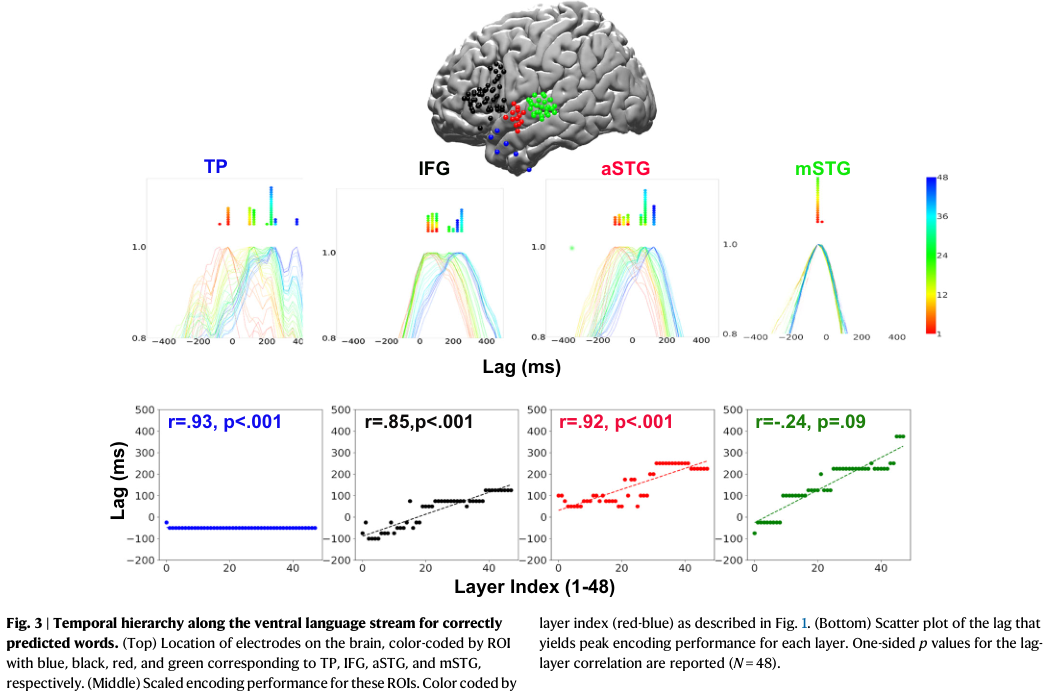
在mSTG中没有观察到明显的时间结构证据。这表明在IFG中观察到的时间动态是区域特异性的,并不发生在语言处理层级的早期阶段。
除了IFG,研究在aSTG(r = 0.92)和TP(r = 0.93)中也发现了同样的有序时间动态证据。这些效应在不同电极和患者中都是稳健的。
结果表明,语言区域的神经活动通过一系列非线性变换进行,这些变换与深度语言模型中的非线性变换相匹配。
一种替代假设是,滞后-层级相关性是由于更基本的网络属性造成的,即早期层代表前一个词,晚期层代表当前词,而中间层携带两个词的线性组合。
为了测试这一解释,设计了一个控制分析,通过在第一层和最后一层的嵌入之间线性插值生成了10,000组46个中间伪层。计算了每组的滞后-层级相关性。
结果表明,实际的滞后-层级相关性显著高于线性插值层获得的相关性。这表明,GPT-2 XL凭借其非线性变换,比执行前一个词和当前词嵌入之间线性变换的简单模型更好地捕捉了大脑动态。
不同大脑区域的时间尺度探索显示,沿着腹侧语言层级,时间尺度逐渐增加。
对于每个ROI,计算了编码最大化滞后集合的标准差作为时间尺度的代理。mSTG和aSTG之间以及aSTG和TP之间存在显著差异。
基于层级的编码模型在TP中表现出最大的区域内时间分离,第1层的峰值(约-100毫秒)与第48层的峰值(约400毫秒)之间相差超过500毫秒。
深度学习模型超越传统心理语言学符号系统
传统上,神经语言学采用系统化的方法,将人类语言分解为语音、形态、句法和语义的层级表征。
每一层表征由特定的符号特征组成。尽管这些语言表征水平之间存在已知的相互作用,但研究实验室通常专注于分别研究这些组件,进行针对个别子领域的实验。
在本研究中,研究团队为该心理语言学层级内的每个水平开发了向量表征,利用该框架为基准数据集生成心理语言学嵌入。
音素(Phonemes)是语言中可区分声音的最小单位。音素由特征描述。
为了生成音素表征,首先将每个词拆分为国际音标(IPA)格式的音素。使用ipapy为每个音素创建了一组33个二元特征。辅音特征类别包括发声、发音部位和发音方式,元音特征类别包括高度、后度、发声和圆唇度。
为了获得一致的嵌入大小,取这些特征的并集形成音素嵌入。将每个词的音素特征向量连接成一个更大的词级音素嵌入。
由于词汇具有不同数量的音素,取播客中单个词的最大音素数量(17),并用零填充其他嵌入,使得跨词汇的嵌入大小一致(总共561 = 17乘以33)。
语素(Morphemes)是语言中意义的最小单位。每个词由一个或多个语素组成。
对于形态学嵌入,使用polyglot将播客中的每个词转换为一组语素。提取播客中包含的所有语素集合(1042个),并对此集合进行独热编码。对于每个词,按顺序连接该词中语素的独热编码。
由于词汇具有不同数量的语素,用零将此嵌入填充到最大嵌入长度(独热编码大小乘以播客中任何词的最大语素数量,总共1042 × 6 = 6252)。
对于句法嵌入,使用了Spacy的词性(POS)分类器。
Spacy使用通用POS标签集,包含形容词、副词、感叹词等17个元素。Spacy还使用更细粒度的TAGs,包含36个细化标签。Spacy解析器识别输入句子及相关的句法层级(即为每个句子创建一个解析树),将每个标记与其句法父节点(即该标记所属句子的解析树的头部)及其后代关联。
使用标记本身、头部以及最左侧和最右侧后代标记的POS和TAG来为标记创建8维句法嵌入。然后对该嵌入进行独热编码,得到大小为212的嵌入。
如果一个词被标记化为多个标记,计算每个标记的独热编码嵌入并将它们平均以获得该词的嵌入。
对于语义嵌入,再次使用了Spacy训练好的模型。
该模型在OntoNotes 5数据集上进行命名实体识别训练,从而捕获底层嵌入表征中的语义方面。通过Spacy API访问解析输入标记的张量属性(96维)。对于由多个标记组成的词,平均得到的96维嵌入。
这些程序产生了一个4级层级,其中每个词都有针对每个级别的精心策划的嵌入。
重复了基于编码的分析。在编码之前,应用PCA将嵌入的维度减少到50。为了防止泄漏,分别对每一层和每个训练-测试分割应用PCA,投影仅从训练数据中学习。
结果表明,大语言模型嵌入比这些心理语言学方法诱导的精心策划的嵌入与大脑的相关性更高。
此外,虽然心理学精心策划的嵌入确实与神经反应相关,但出现的时间动态似乎与大脑中的时间过程不一致。
在所描述的实现中,结果表明大语言模型诱导的嵌入比经典的符号方法更好地模拟了大脑的时间动态。
这强调了深度学习模型在捕捉大脑动态方面的优势。虽然存在许多其他可能的音素-语素-句法方法的实现,但这为社区测试它们提供了一个基准。
重塑计算神经科学的认知框架
本研究公开发布一个包含词汇刺激和在语言理解实验期间跨多个电极测量的相应神经反应的综合数据集。
该数据集包括每个词的向量表征,允许对大脑中的语言处理进行编码分析。详细编码分析的包含,特别是标准编码、缩放编码和滞后-层级图,为研究社区提供了基础资源。
研究结果为大语言模型和人类大脑在处理自然语言方面共享计算原则提供了证据。
通过利用ECoG在拟合大语言模型上下文嵌入方面的卓越时间分辨率,发现大语言模型(GPT-2 XL和Llama-2)学习的逐层变换映射到了大脑中高级语言区域的时间动态。
无论是预测词还是未预测词,结果都得到了复现,进一步增强了其稳健性。
这一发现通过展示对口语的神经反应与大语言模型中语言的层级处理之间的对应关系,揭示了大语言模型与大脑处理语言之间的重要联系。
研究指出了基于Transformer的大语言模型与人类大脑在计算内部序列实现上的差异。
大语言模型依赖于Transformer架构,这种神经网络架构是为了在训练期间并行处理成百上千个词而开发的。
虽然基于Transformer的大语言模型按层顺序处理词汇,但研究发现了人类大脑中类似顺序处理的证据,但这是在给定的皮层区域内相对于词汇出现的时间而言的。例如,在高级语言区域(如IFG和TP),时间处理序列对应于大语言模型中的逐层处理序列。
这种对应关系源于语言模型中跨层的非线性变换,并不是前一个词和当前词之间简单线性插值的结果。
特别是大语言模型中间层的编码性能非常强,尤其是在mSTG区域。
这种高度相关的模式与之前的发现一致,强调了中间大语言模型层在捕捉相关神经活动方面的稳健性。
mSTG的卓越性能可能归因于其低级听觉和语音处理特性,这些特性本质上涉及较少的时间不确定性或噪声,导致与大语言模型输出的相关性更清晰。
大语言模型与人类大脑之间的另一个根本区别在于用于训练这些模型的数据特征。
人类不是通过阅读文本来学习语言的,而是通过与其社会环境的多模态互动来学习的。
训练这些模型所用的文本量相当于数百年(或数千年)的人类听力。
一个悬而未决的问题是,当大语言模型在更像人类的输入上训练时表现如何:不是文本数据,而是口语、多模态、具身且沉浸在社会行动中。
尽管存在明显的架构差异,但它们内部计算序列的趋同值得注意。
经典心理语言学理论提出了用于语言处理的基于规则的符号系统,而大语言模型提供了一种截然不同的方法——通过在上下文中预测语言使用来通过统计学习语言。
这种意想不到的映射(层级序列到时间动态)为理解大脑和开发更好地模仿人类语言处理的神经网络架构开辟了途径。
未来的一个关键研究问题是如何将我们在语言区域和大语言模型中观察到的非线性神经变换的动态序列与经典基于规则的语言学研究中描述的语言过程的可解释结构对齐。
这项研究提供了大语言模型与人类大脑之间共享内部计算的有力证据,并建议范式转变——从语言的符号表征转向关注上下文嵌入和统计语言模型。
然而,最近的证据强调了它们在捕捉复杂句子结构和复制经验人类处理效应方面的局限性。
这些发现强调了系统评估作为认知模型的大语言模型的重要性,以划定其优势和表达边界。
同时,大语言模型已证明有能力近似传统的语言表征,这表明有机会协调深度学习方法与传统心理语言学框架。
通过可解释性努力弥合这些方法,可能会对人类认知过程和语言表征的本质提供更深入的见解。
参考资料:
https://www.nature.com/articles/s41467-025-65518-0
https://arxiv.org/pdf/2310.07106
END

















 2410
2410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









