



一个由谢赛宁领导,杨立昆(Yann LeCun)、李飞飞参与指导的团队,发布了一项名为Cambrian-S的研究。
这项研究让AI学会了惊讶,这或许是人工智能从反应式感知迈向预测性理解的关键一步。
这篇论文的核心,不是一个更强的模型,而是一种全新的思考方式。
研究指出,当前顶尖的多模态大语言模型(MLLMs)在理解视频时,本质上可能更像在阅读图文摘要,而非真正理解三维空间。
我们以为AI在看视频,但它们处理的往往是几张孤立的、被抽取的帧。
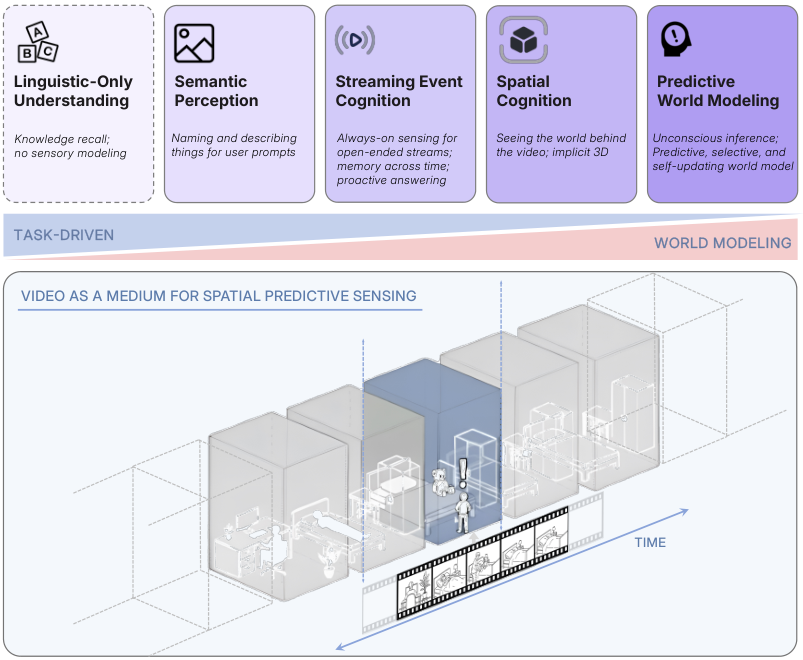
研究团队提出了一个全新的概念——空间超感知(Spatial Supersensing),旨在推动AI从被动的模式识别,进化到主动地理解和预测我们身处的这个三维世界。
多模态AI正试图摆脱对海量上下文的暴力记忆,转而学习人类大脑高效处理信息的根本机制:预测。
AI视觉理解与空间超感知
要理解什么是空间超感知,需要先看清AI视觉能力发展的几个阶段。
最初是纯语言理解阶段。这个阶段的AI是盲人,只能处理文本和符号,没有任何感知能力。
现在,我们正处于语义感知阶段。
得益于强大的视觉编码器与语言模型的结合,AI能够解析像素,识别出视频中的物体、属性和关系。这赋予了模型强大的看图说话能力,比如GPT-4o和Gemini,它们能准确描述画面内容。
但这种能力有其上限。
模型将视频看作一连串稀疏的图片,过度依赖从海量数据中学习到的文本知识进行回忆和联想,却忽视了视频作为三维世界在二维平面上连续投影的本质。
它知道这是一把椅子,那是一张桌子,但它真的理解椅子在桌子下面这个空间关系吗?当镜头移动,光影变化,它还能持续追踪并理解这个空间布局吗?
答案往往是否定的。
Cambrian-S的研究团队将空间超感知划分为一个超越当前能力的、连续的演进阶梯。
紧随语义感知之后的是流事件认知阶段。
这个阶段要求模型能处理实时、不间断的视频流,主动地解释和响应连续发生的事件。这好比让AI成为一个能随时待命的实时助手,它需要拥有对事件的持续记忆和理解力。
再往上,是隐式3D空间认知阶段。
模型必须将视频理解为三维世界的投影。它要知道什么东西存在,在什么位置,物体之间如何关联,以及这些空间关系如何随时间演变。这是当前视频模型普遍存在的短板。
最高阶段,是预测性世界建模。
这触及了智能的核心。人类大脑并非被动接收信息,而是在不断根据过去的经验预测接下来会发生什么。当现实违反了预测,我们就会感到惊喜,这种惊喜会引导我们的注意力、记忆和学习。
目前的AI系统,恰恰缺少这种能够预测未来,并利用惊喜来组织感知、辅助决策的内部世界模型。
这四个阶段,清晰地勾勒出一条从基础感知到高级认知的进化路径,也暴露了当前技术范式的天花板。
现有AI视频测试暴露了致命缺陷
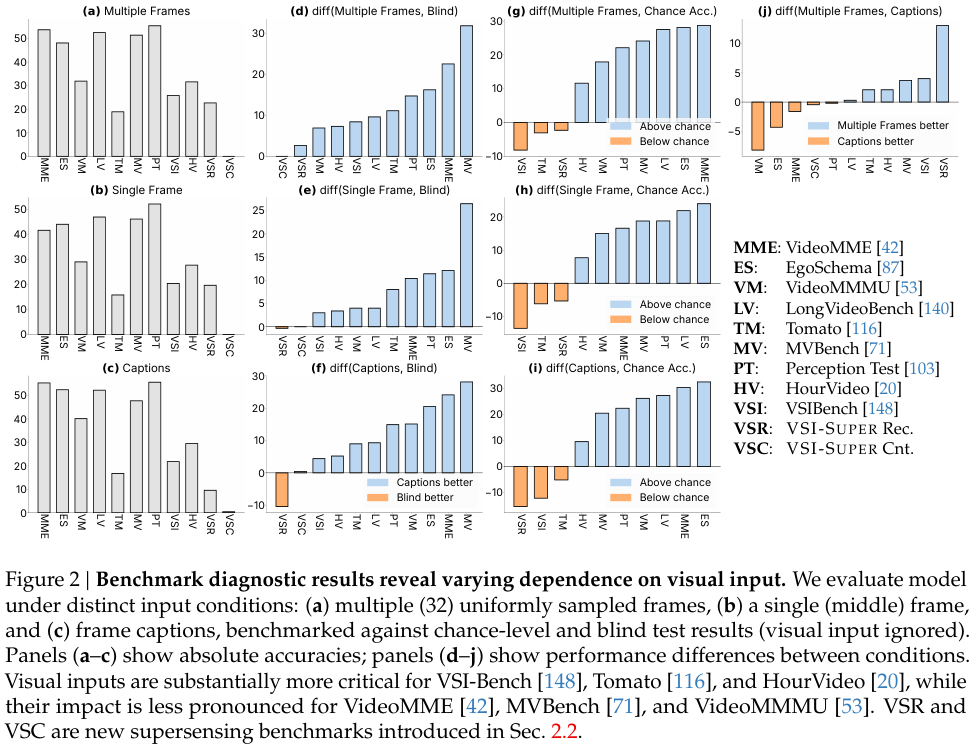
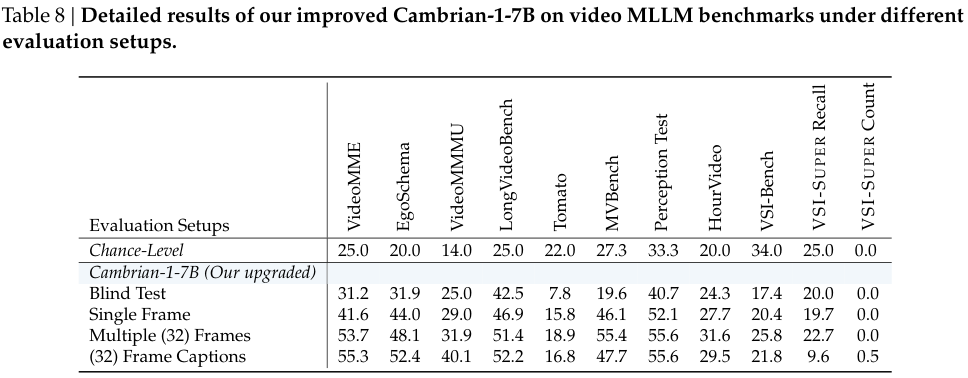
为了验证当前AI视频理解能力的真实水平,研究团队设计了一系列直击要害的诊断测试。他们没有采用更复杂的视频模型,而是使用了基于单张图像训练的多模态模型Cambrian-1,从而精准地探究各类视频基准测试到底在考什么。
测试设置了几种条件:
-
多帧输入:这是标准方法,让模型处理从视频中均匀采样的32帧图像。
-
单帧输入:只给模型看视频最中间的那一帧,考验模型对最核心视觉信息的依赖度。
-
帧字幕输入:不给图像,只给模型看对应32帧画面的文字描述。这个条件旨在揭示,在没有视觉输入的情况下,任务本身能在多大程度上被语言解决。
同时,他们引入了两个参照基线:
-
盲测:完全不给任何视觉信息,只让模型看问题。这衡量的是模型仅凭语言先验知识和题目中可能存在的偏见能答对多少。
-
机会准确率:也就是瞎猜的正确率。
结果令人深思。
一个没有经过任何视频训练的图像模型Cambrian-1,在许多视频基准测试上都能取得远超瞎猜的成绩。这说明,这些测试所考察的很多能力,通过常规的图文指令微调就能学到,并不一定需要真正的视频理解。
更关键的发现是,当输入从图像换成文字字幕后,模型的性能在多个主流基准测试(如EgoSchema、VideoMME、Perception Test等)上依然大幅领先于机会准确率。
当比较多帧输入和帧字幕输入的性能差异时,如果前者显著优于后者,说明测试需要精细的视觉感知。反之,如果两者差距不大,甚至后者更优,则表明测试更偏向于语言理解。
分析结果将多个知名基准测试归入了后一类。这意味着,这些测试在很大程度上是在考察AI从文本摘要中推断信息的能力,而不是真正的视觉空间推理。
这并不是说语言先移不重要,在很多场景下,丰富的世界知识至关重要。
但它揭示了一个事实:我们可能高估了当前AI的视频理解能力。它们或许只是更擅长根据文字线索做推理题的语言大师,而非真正的空间感知者。
新的挑战:VSI-SUPER基准测试
为了填补这一空白,研究团队推出了一个全新的基准测试——VSI-SUPER。它专门为探测长期、持续的空间智能而设计,包含两个对人类来说非常直观,但对机器极具挑战性的任务。
VSI-SUPER Recall(VSR):大海捞针式的空间记忆
这个任务要求模型观看一段长达数小时的室内环境漫游视频,然后按顺序回忆出视频中出现过的几个不寻常物体的位置。
研究人员用图像编辑技术,在视频的四个不同位置悄悄植入一些格格不入的东西。然后将这段视频与其他正常的房间导览视频拼接起来,形成一个连续、超长的视觉流。
这就像语言模型领域流行的大海捞针测试,但难度更高。它不仅要求模型在海量信息中找到针,还保留了针的视觉真实性,并要求按顺序回忆,这实质上是一个多步推理任务。为了全面评估,该测试提供了10分钟到240分钟不等的视频长度。
VSI-SUPER Count(VSC):跨场景的持续计数
这个任务测试模型在长视频中持续累积信息的能力。研究人员将多个不同房间的导览视频拼接在一起,要求模型数出所有房间里某种目标物体的总数。
这听起来简单,但对AI来说极具挑战。模型必须处理视角的不断变化、物体的重复出现以及场景的切换,同时维持一个准确的累计计数。
人类一旦理解了计数这个概念,就能将其泛化到任何数量。但后续实验表明,当前的AI缺乏这种真正的空间认知,过度依赖于从训练数据中学到的统计规律。
VSI-SUPER这两个任务的设计,直接挑战了当前AI范式的两个基本信念。
它挑战了只要模型够大、上下文窗口够长就能解决一切的信念。
VSI-SUPER的视频可以任意长,超过任何固定的上下文窗口。这意味着简单粗暴地将视频逐帧输入处理,在计算上是不可行的。人类通过选择性地关注和记忆来高效处理信息,而AI尚不具备这种能力。
它还要求模型具备泛化到全新时间和空间尺度的能力。就像学会数数的人可以数任何东西一样,AI也应该学习到计数的过程,而不是记住特定场景下的数量。
这些挑战共同指向一个结论:未来的AI不应仅仅依赖于堆数据、加参数或扩充上下文长度,而必须学习能够在无尽的视觉世界中感知和预测的内部世界模型。
Cambrian-S模型的诞生与局限
在认清现有范式的局限后,研究团队首先探索了在当前框架内能走多远。他们开发了一系列名为Cambrian-S的空间定位多模态模型。
为此,他们首先构建了一个大规模、高质量、专注于空间理解的指令微调数据集——VSI-590K。
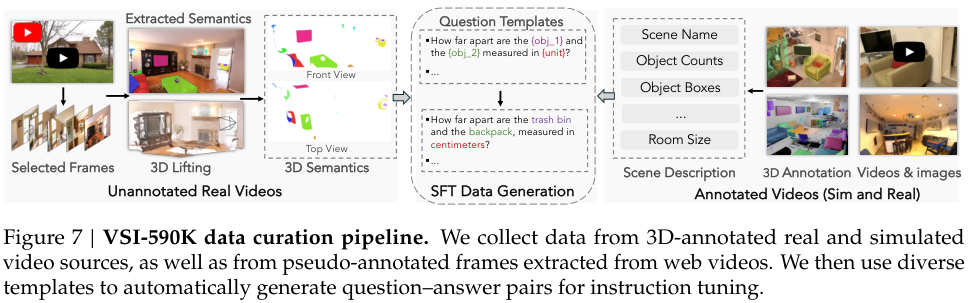
这个数据集融合了多种数据源,包括带精确3D标注的真实室内视频、程序化生成的模拟视频,以及从网络视频中通过AI模型提取的伪标注数据。
通过精心设计的问题模板,数据集覆盖了尺寸、方向、计数、距离和外观顺序等12种空间问题类型,极大地丰富了模型在空间维度上的学习素材。
基于这个数据集,Cambrian-S的训练流程分为四个阶段。
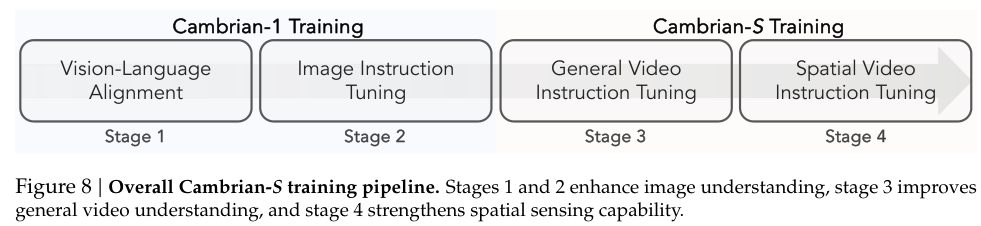
前两个阶段主要构建强大的图像理解能力。第三阶段通过一个包含300万样本的通用视频数据集,将模型的能力扩展到视频领域,打下坚实的基础。
在第四阶段,模型在一个混合语料库上进行微调,该语料库结合了专门的VSI-590K和通用的视频数据,从而重点培养其空间感知能力。
实验结果证明了这种方法的有效性。
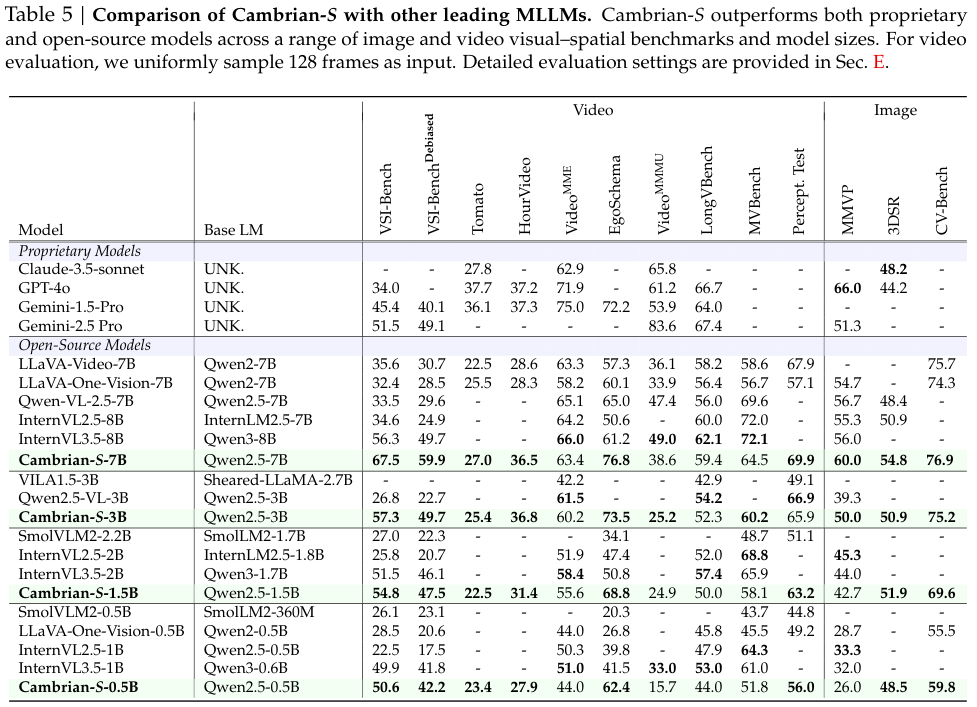
从0.5B到7B参数规模,Cambrian-S模型在多个视觉空间基准测试上,全面优于现有的开源模型,甚至包括一些专有模型。特别是在为空间理解设计的VSI-Bench上,7B模型取得了67.5%的准确率,比之前的最佳模型高出十几个百分点。
这证明,通过精心策划的数据和训练配方,模型的空间认知能力可以得到显著提升。
但这并没有解决根本问题。
尽管Cambrian-S在现有基准上表现优异,但在更具挑战性的VSI-SUPER测试上,它的性能依然非常有限。这有力地说明,仅仅依靠扩大模型规模和优化训练数据,这条路已经快走到尽头了。
真正的智能在于预测,而非看见
当前范式的局限,促使研究团队探索一条全新的路径——预测性感知(Predictive Sensing)。
这个想法的内核是,模型不应该只是被动地接收和处理信息,而应该主动地预测接下来会看到什么。当现实与预测产生偏差,即出现惊喜时,模型就利用这个信号来指导自身的注意力、记忆和学习。
研究团队提出了一个基于自监督学习的、预测下一帧画面的概念验证方案。模型利用预测误差,也就是惊喜,来做两件关键的事:管理记忆,以及分割事件。
在VSI-SUPER Recall(大海捞针)任务中,他们设计了一个惊喜驱动的记忆管理系统。
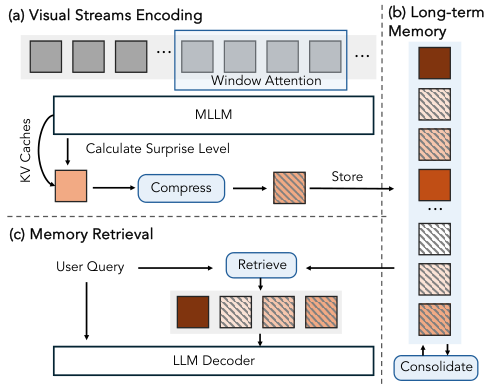
系统会持续监控模型的预测误差。当检测到强烈的惊喜信号时,比如画面中突然出现了一只本不该在客厅里的泰迪熊,系统就会将这个意外事件及其相关信息存入一个长期记忆库。
这完美模拟了人类的注意力机制。
我们更容易记住那些出乎意料的事情。通过这种方式,模型能高效利用有限的记忆资源,只存储那些最关键、最反常的信息。
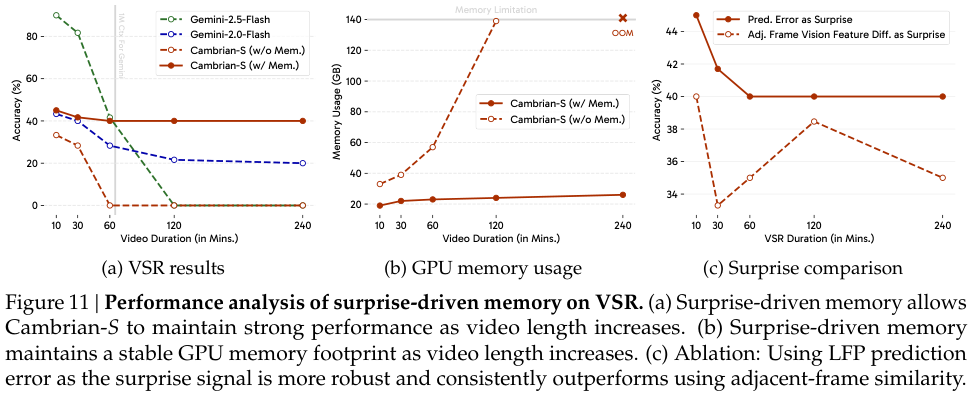
实验证明,在长达数小时的视频中,这种方法的性能远超传统的长上下文模型,后者的性能会随着视频长度的增加而急剧衰减。
在VSI-SUPER Count(跨场景计数)任务中,惊喜信号被用来做持续的视频分割。
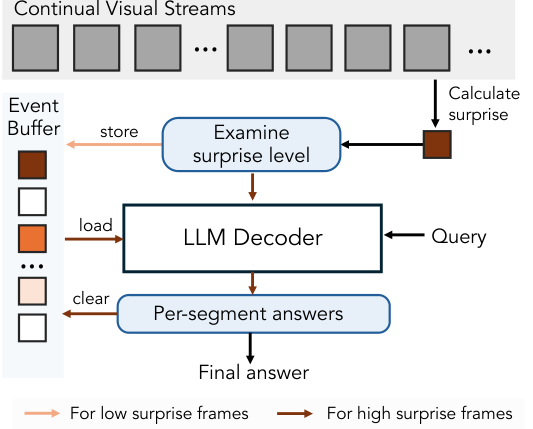
当预测误差飙升时,比如镜头从一个房间切换到另一个房间,或者一个新物体进入视野,系统就认为这是一个自然的事件边界。
它将漫长的视频流自动切分成一个个有意义的、更易于管理的事件片段。
模型可以对每个片段进行独立的计数处理,然后将结果汇总,从而在复杂的长视频中保持计数的准确性和一致性。
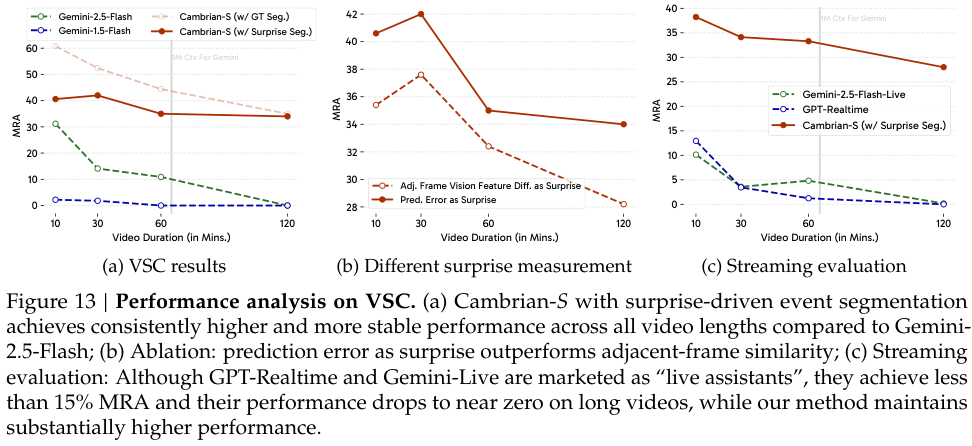
实验结果同样显示,这种方法的表现显著优于其他基线方法。
将预测性感知与传统的长视频处理方法,如扩大上下文窗口、均匀采样、关键帧提取等进行比较,在新提出的VSI-SUPER两个任务上,预测性感知都取得了压倒性的优势。
尤其是在超长视频上,它的性能保持相对稳定,而其他方法的性能则早已崩溃。
这一系列研究和实验,从提出空间超感知的理论框架,到揭示现有基准的不足,再到构建新基准和新模型,最终指向了一个激动人心的新范式。
通往真正机器智能的道路,需要的或许不是让AI看得更多,而是让它学会像我们一样,主动地去预测和理解这个世界。
参考资料:
https://github.com/cambrian-mllm/cambrian-s
https://arxiv.org/pdf/2511.04670
https://huggingface.co/collections/nyu-visionx/cambrian-s-models
https://huggingface.co/datasets/nyu-visionx/VSI-590K
https://huggingface.co/collections/nyu-visionx/vsi-super
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









