



谷歌DeepMind团队的AI智能体CodeMender,在过去半年里,已经悄无声息地为72个开源项目贡献了安全补丁,其中有些项目的代码量甚至达到了450万行。
直到10月6日,谷歌DeepMind才正式把CodeMender推到了台前。

它不是一个简单的代码扫描工具,而是一个能独立思考、自主行动的智能体,专门负责揪出软件里藏得最深、最要命的安全漏洞,然后把它修好。
CodeMender干活有两把刷子。
“反应式安全防护”:就像是急诊室医生,哪里出了问题就火速冲向哪里。一旦有新的安全漏洞被发现,CodeMender会立刻分析、定位并生成修复补丁,赶在坏人利用它之前把门堵上。
“主动式安全加固”:就好比是养生专家,不治已病治未病。CodeMender会主动审查现有的代码,把一些老旧、有潜在风险的写法,用更安全的数据结构和API重写一遍。直接铲除某一类漏洞滋生的土壤,实现釜底抽薪式的安全。
这种“有病治病,无病强身”的组合,让CodeMender成了软件安全领域里的多面手。
“前辈”们的肩膀
CodeMender的诞生,背后是DeepMind在AI安全领域好几年的铺垫。
它的前身,可以追溯到一个叫“Project Naptime”(午睡计划)的项目。这个计划最初是专门用来评估大语言模型在网络攻击方面的能力,看看它们到底有多大“破坏力”。
摸清了底细后,这个项目升级成了“Big Sleep”(深度睡眠)。这是谷歌的顶尖黑客团队Project Zero(零号项目)和DeepMind联手搞的一个大动作。
2024年10月,Big Sleep一战成名。它在全世界广泛使用的数据库软件SQLite里,成功挖出了一个以前谁都不知道的内存安全漏洞。这是一个能被黑客实实在在利用的漏洞。
这个漏洞在SQLite正式发布新版本之前就被发现了,开发人员当天就把它修复了。全世界数以亿计的用户,在毫不知情的情况下,躲过了一次潜在的安全风险。
Big Sleep的成功,给CodeMender指了一条明路。它采用了一种叫做“变体分析”的策略。简单说,就是不让AI像无头苍蝇一样满世界乱找漏洞,而是给它一个明确的起点。
比如,拿一个已经修复过的漏洞作为“案宗”,让AI去代码库里寻找其他长得像、原理类似的“在逃”漏洞。
这种方法极大降低了AI的工作难度,让它能从一个具体的、有根据的理论出发:“这儿以前犯过错,别的地方很可能还有类似的坑”。
CodeMender还站在了另一个巨人,OSS-Fuzz的肩膀上。
OSS-Fuzz是谷歌搞了很久的一个开源软件持续模糊测试平台。所谓“模糊测试”,你可以想象成一个不知疲倦的测试员,把各种千奇百怪、乱七八糟的数据一股脑地塞给一个程序,看它会不会崩溃或者出现异常。这种简单粗暴的方法,在发现未知漏洞方面效果出奇地好。
到2025年5月,OSS-Fuzz已经累计帮助超过1000个开源项目,找出了超过13000个漏洞和50000个bug。它支持从C/C++、Rust、Go到Python、Java等几乎所有主流编程语言。
后来,OSS-Fuzz团队也开始拥抱AI。他们发现,可以用大语言模型来自动编写模糊测试的“靶子”,也就是那些专门用来测试特定功能的小程序。AI写的这些“靶子”,比人写的更刁钻、更全面,能覆盖到很多人注意不到的代码角落。
2024年11月,AI加持的OSS-Fuzz交出了一份惊人的成绩单。它利用AI生成和增强的测试目标,新发现了26个漏洞。其中一个甚至藏在支撑了半个互联网基础设施的关键加密库OpenSSL里。这26个漏洞,每一个都是自动化漏洞发现的里程碑,因为它们都是AI的功劳。
有了这些“前辈”的探索和积累,CodeMender的出现就显得水到渠成了。
拆解CodeMender的大脑和工具箱
CodeMender的核心大脑,是一个叫做Gemini Deep Think的模型。
这是谷歌Gemini 2.5系列里的顶级型号。它的特点是会“并行思考”,能同时测试多个假设,并且通过强化学习不断优化自己的决策。它的上下文窗口达到了惊人的100万个令牌,输出也能达到19.2万个令牌,处理超长、超复杂的代码毫无压力。
光有大脑还不够,得有趁手的工具。CodeMender的工具箱里装满了各种高级程序分析工具,让它在动手改代码之前,能像个经验丰富的老工程师一样,对代码进行深入的推理和诊断。

这些工具包括:
-
静态分析:像X光一样,在不运行代码的情况下扫描代码的结构,找出潜在的问题。
-
动态分析:让代码跑起来,像心电图一样实时监测它的行为,看有没有异常。
-
差分测试:同时运行新旧两个版本的代码,比较它们的输出差异,防止修复了一个bug又引入了新bug。
-
模糊测试:前面提到的,用海量的随机数据去冲击程序,挖掘潜在的崩溃点。
-
SMT(可满足性模理论)求解器:这是一种强大的数学工具,能解决复杂的逻辑约束问题,帮助AI在修改代码时做出最优决策。
有了这些工具,CodeMender就能系统地检查代码的模式、控制流和数据流,从而精准定位到漏洞的根本原因。
更有意思的是,CodeMender还采用了“多代理系统”的架构。你可以把它想象成一个高效的专家团队。团队里有不同分工的AI代理,每个代理都是一个特定领域的专家。比如,有一个“批评家”代理,它专门负责比较原始代码和修改后的代码,吹毛求疵地检查修复方案会不会引入新的问题。一旦发现不妥,“批评家”就会提出意见,主程序代理再根据反馈进行自我纠正。
这种团队协作模式,让CodeMender能并行处理多个任务,效率极高。
它不只是找茬,还负责善后
CodeMender修复漏洞的流程,堪称典范。
它会像一个侦探一样,利用调试器、源代码浏览器等工具,层层深入,直捣黄龙,找到问题的根源。
DeepMind的官方博客里举了两个例子。
一个例子里,有个程序崩溃了,报告显示是堆缓冲区溢出。但CodeMender通过分析调试器输出和代码,发现真凶并非如此,而是在解析XML元素时,一个堆栈管理出了错。最终的补丁可能只改了几行代码,但找到这个根本原因的过程却相当复杂。CodeMender做到了。
另一个例子更夸张。CodeMender不仅找到了一个复杂的对象生命周期问题的根源,甚至还搞懂了那个项目里一套完全自定义的、用来生成C代码的系统,并对它进行了修改。这已经超出了简单修复的范畴,进入了重构的领域。
找到问题、修复问题还只是第一步,保证修复方案的质量是关键。
大语言模型虽然强大,但偶尔也会“犯糊涂”。在代码安全这个高风险领域,任何一点小差错都可能造成巨大的损失。CodeMender有一套严格的自动验证流程,确保它提交的每一个补丁都是高质量的。
这个流程会从多个维度进行检查:补丁是不是真的解决了问题的根本原因?功能上是不是正确的?会不会导致其他功能出现倒退(回归)?代码风格是不是符合项目规范?
前面提到的那个“批评家”AI代理在这里就派上了大用场。它会被配置成一个“功能等效性”的评判员,来验证修改后的代码功能和原来一模一样。一旦检测到验证失败,主代理就会立刻根据“批评家”的反馈进行自我纠正,重新思考修复方案。
CodeMender还能主动出击,重写现有代码,提升代码的“免疫力”。
几年前,一个广泛使用的图像压缩库libwebp中爆出了一个名为CVE-2023-4863的严重漏洞。黑客可以利用这个漏洞,制作一张“有毒”的图片。用户只要看到这张图片,什么都不用点,手机就可能被完全控制。这就是所谓的“零点击”攻击,让人防不胜防。当时这个漏洞被用在一个针对iPhone的攻击链BLASTPASS中,引起了轩然大波。
CodeMender被部署到libwebp项目后,干了一件大事。它主动给代码加上了-fbounds-safety注释。这个注释的作用,是告诉编译器在编译代码时,自动给数组和指针加上边界检查。这样一来,即使代码逻辑有瑕疵,黑客也无法再利用缓冲区溢出或下溢来执行恶意代码。
加上了这个注释后,像CVE-2023-4863这类漏洞,以及项目中绝大多数其他的缓冲区溢出问题,就永远失去了被利用的机会。
把它和传统的人工审计、静态分析放在一起比,区别一目了然:

再看看它和其他AI安全工具的对比:
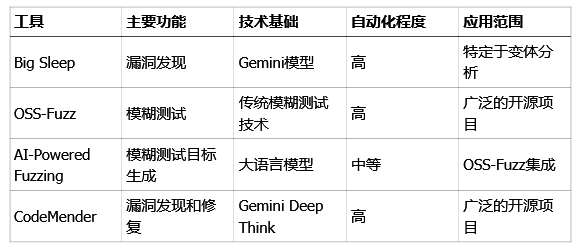
CodeMender的创新是全方位的:它既能救火也能防火;它有严格的自我审查机制,保证工作质量;它还是一个团队在作战,而不是单打独斗。
目前,所有由CodeMender生成的补丁,在提交给开源社区之前,都会由DeepMind的真人研究员再审查一遍。
他们正在逐步扩大这个流程,并主动联系各大开源项目的维护者,提供CodeMender生成的补丁,并根据社区的反馈不断迭代和改进。
他们的最终目标,是把CodeMender打造成一个所有软件开发者都能使用的工具,帮助大家守护好自己的代码库。
CodeMender的出现,给整个软件世界请了个24小时在线的专职安全专家。
参考资料:
https://deepmind.google/discover/blog/introducing-codemender-an-ai-agent-for-code-security
https://googleprojectzero.blogspot.com/2024/10/from-naptime-to-big-sleep.html
https://github.com/google/oss-fuzz
https://security.googleblog.com/2023/08/ai-powered-fuzzing-breaking-bug-hunting.html
https://security.googleblog.com/2024/11/leveling-up-fuzzing-finding-more.html
https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-2-5-Deep-Think-Model-Card.pdf
https://www.upguard.com/blog/libwebp-cve-2023
https://www.ox.security/blog/what-you-need-to-know-about-the-libwebp-exploit
https://citizenlab.ca/2023/09/blastpass-zero-click-exploit-chain-used-to-deliver-predator-spyware/
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









