






 在语音问答系统中,因每类训练数据量少,传统分类器易过拟合,故研究小样本学习。介绍了小样本学习基本概念,评价了一篇相关论文,阐述了 few - shot 算法通过对比图像特征识别,zero - shot 算法通过对比图像描述和图像识别,还给出了算法结构和目标函数。
在语音问答系统中,因每类训练数据量少,传统分类器易过拟合,故研究小样本学习。介绍了小样本学习基本概念,评价了一篇相关论文,阐述了 few - shot 算法通过对比图像特征识别,zero - shot 算法通过对比图像描述和图像识别,还给出了算法结构和目标函数。
前言
在语音问答系统领域,很多时候,每一个类所拥有的训练数据量是很少的,采用传统的分类器进行训练,很可能出现overfitting,为了应对这种问题,最近要研究一下小样本学习。
关于小样本学习的基本概念,可以参看https://www.chainnews.com/articles/650132977783.htm,该综述中还提到了每种类型算法中的典型算法。
论文评价
论文链接:https://arxiv.org/pdf/1711.06025.pdf
这篇论文结构简单,没有很多技巧,但是效果好,理论清晰,是一篇很赞的文章,很喜欢这类文章。
few-shot 算法
- few-shot: 通过对比图像与图像之间的特征来实现识别;
- zero-shot:通过对比对图像的描述和图像来实现识别;
- 该论文框架也可适用于zero-shot, 本节主要针对few-shot讲解
该论文采用一个深度网络,该网络包含两个模块:embedding module和relation module。
embedding module 负责将support set中的图像和batch中的图像进行编码(其实就是提取各自的特征),relation module的任务是以这两个特征为输入,判断两个图像的匹配得分,1表示是同一个类,0表示为不同类。
算法整体结构:
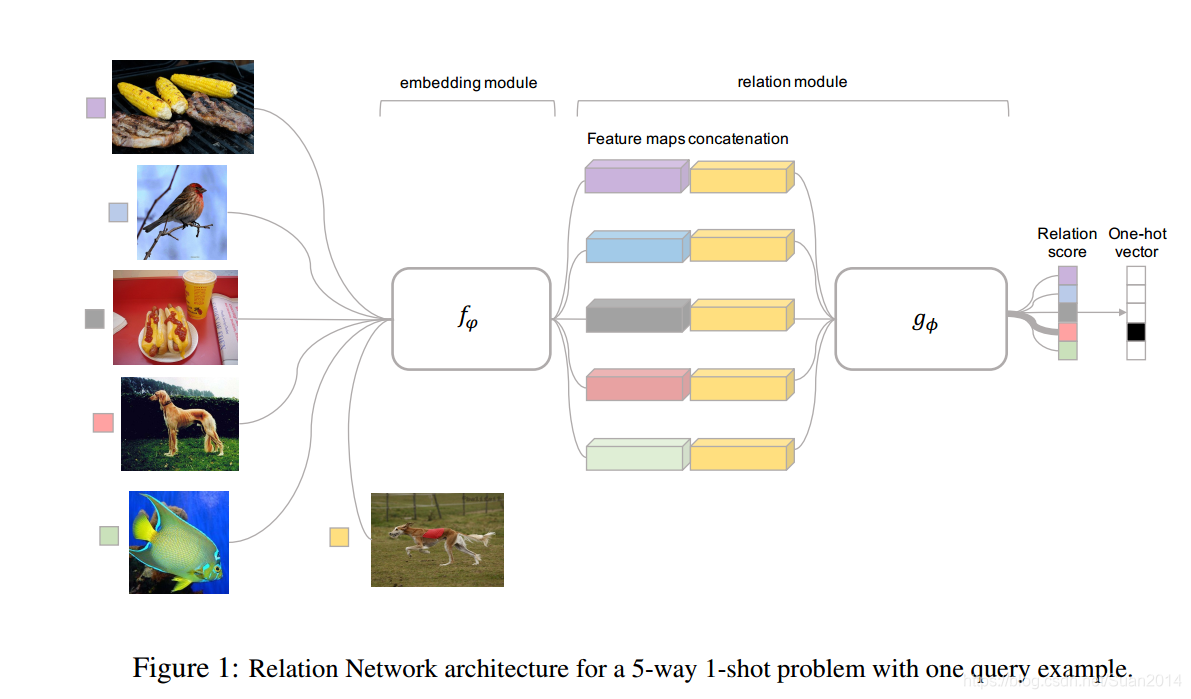
上图中
f
ψ
f_{\psi}
fψ代表embedding module,
g
ϕ
g_{\phi}
gϕ代表relation module, 训练时 C-way k-shot中, 每个类中的1张query image(如上图中穿最下方穿红衣服的狗狗)通过embedding module得到其feature,该类support set中的k个images 都通过embedding module 得到k个features,将该k个features的对应元素求和得到该类的feature,将该类的feature和query image的feature进行concatenate送到relation module,relation module得到一个得分,利用MSE作为目标函数,上述过程用公式表示如下:
r
i
,
j
=
g
ϕ
(
C
(
f
ψ
(
x
i
)
,
f
ψ
(
x
j
)
)
)
r_{i,j}=g_{\phi}(C(f_{\psi}(x_i),f_{\psi}(x_j)))
ri,j=gϕ(C(fψ(xi),fψ(xj)))
其中,
C
C
C代表concatenation,
r
i
,
j
r_{i,j}
ri,j代表得分。
目标函数为:
a
r
g
m
i
n
ψ
,
ϕ
∑
i
i
=
m
∑
j
j
=
n
(
r
i
,
j
−
1
(
y
i
=
=
y
j
)
)
argmin_{\psi,\phi}\sum_{i}^{i=m}\sum_{j}^{j=n}(r_{i,j}-1(y_i==y_j))
argminψ,ϕi∑i=mj∑j=n(ri,j−1(yi==yj))
其中,
y
j
y_j
yj代表query image的类别标签,
y
i
y_i
yi代表support set中第i类的标签。
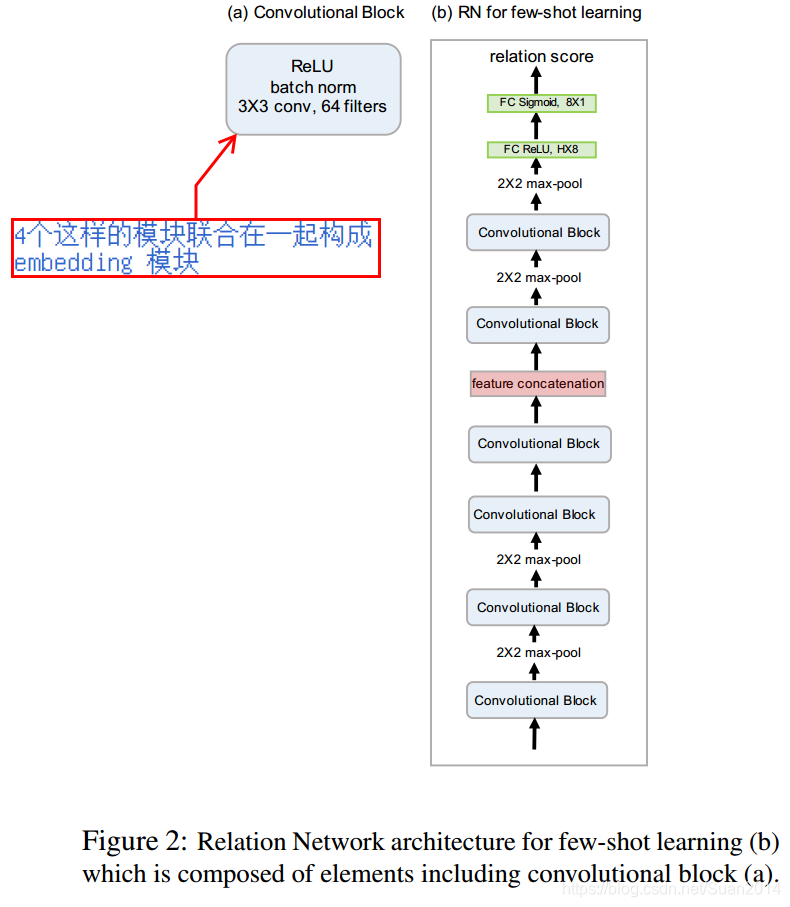
具体的网络结构如下图所示:
zero-shot
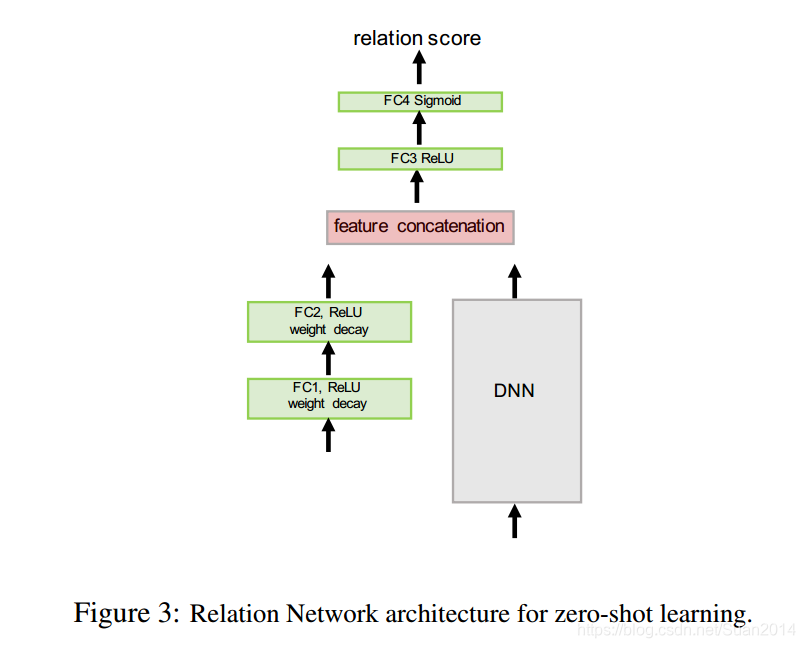
DNN用作处理image的embedding module, 可采用imageNet上训练好的InCeption v2或者ResNet101,左侧输入语义向量。


















 694
694




 到【灌水乐园】发言
到【灌水乐园】发言









