



Relation Network (RN)
计算机视觉领域的模型需要大量的标注数据和多次迭代来训练它们的大量参数。由于标注成本过高,严重限制了它们对新类的鲁棒性,对于某些新的类别和稀有的类别,其标注数据的代价更高。相比之下,人类只需要少量的有监督学习就能很好的识别物体,甚至不需要学习。比如儿童很容易通过一张图片或者“带着条纹的马”这些描述来知悉斑马的概念,这些都是机器做不到的,因此也激起了研究小样本学习的热潮。同时代的小样本学习方法经常是将训练分解为辅助的元学习阶段,这个阶段可转移知识以良好初始条件、嵌入或优化策略的形式来完成学习。
在此之前许多方法采用元学习和学会学习的策略从一系列辅助的任务上来迁移知识。比如 MAML 通过在少量的梯度衰减步骤中调配参数来高效地微调在稀疏数据上的模型的权重,每一个目标问题在微调后都驱动基本模型的更新,即更好的初始化模型。以 RNN-Memory 为基础的模型,RNN 循环遍历一个问题的实例并加速在隐藏激活层和额外的 memory 的知识获得,新的实例的类别通过比较存储在 memory 里历史信息获得,需要在许多不同任务上训练 RNN 的权重,虽然吸引人,但是这种结构面临着必须保证可靠存储所有的长距历史信息的挑战。还有以嵌入和度量为基础的方法,致力于学习一系列的投射函数,用来处理 query 和已有实例的匹配。
本文提出了一种端到端训练的关系网络。在训练阶段,可以学习一个深度距离度量来比较 episode 内的图片,学习用于比较 query 和已知样本的嵌入模块和深度非线性度量模块。测试阶段,通过计算 query images 和已知类别的少数实例(sample)的度量来对该实例进行分类,without further updating the network(任何模型测试阶段不是都不需要?这里说的可能是泛化到新数据集后的微调)。具体来说,用该模型两个部分来学习如何比较 query image 和少量的标注样本(sample)。第一个部分 embedding module 用来产生 query 和类别实例的表征,这些表征被送入第二个部分 relation module 来判别是否属于同一类别。
RN 网络结构
包含三个数据集:训练集、支持集和测试集,支持集和测试集在同一标注空间内,训练集有其自己的标注空间并不与前者有交集。利用训练集的一种有效方法是通过基于 episode 的训练来模拟小样本的学习设置。在每一次训练的迭代中,随机抽取 C 类,每类包含 K 个有标签实例,作为 sample 集,这 C 类中剩下的有标签实例作为 query 集。sample/query 用来模拟测试推理阶段的 support/test 。如果需要,sample/query 训练过的模型可以用 supprt 集进行微调。
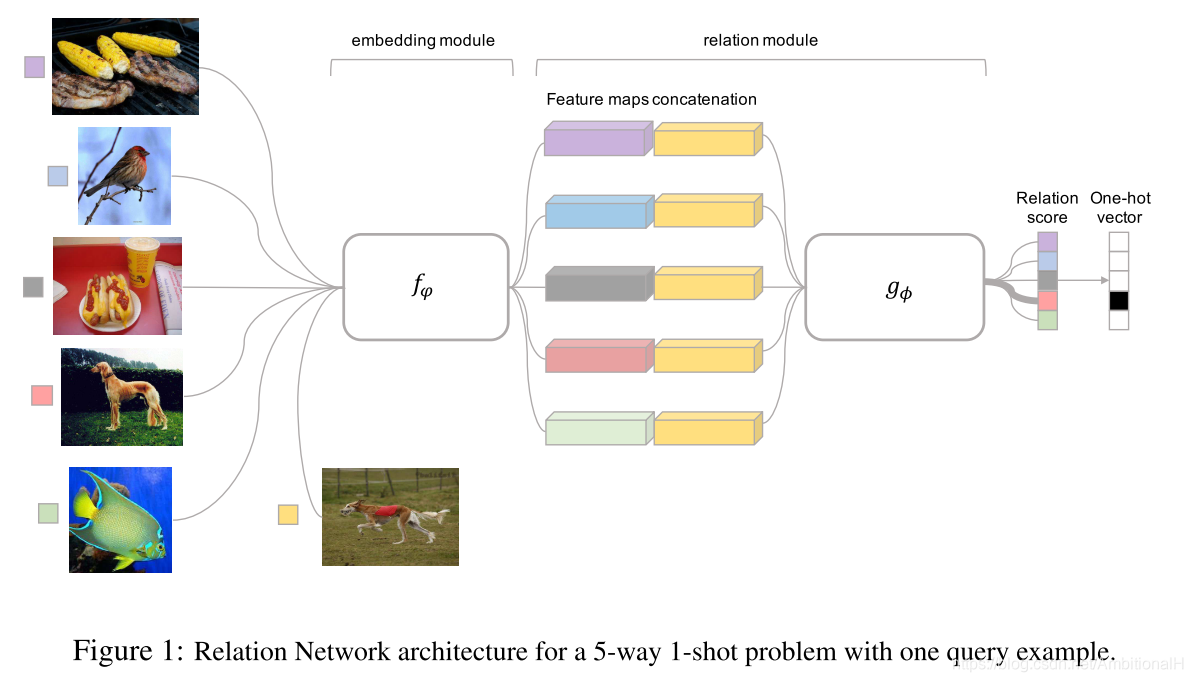
以 1-shot 为例,网络包含 embedding module(f,可以看作特征提取)和 relation module(g,可以看作距离度量),第一列是 sample set,右侧下方的是 query set,将其分别送入 f 中,提取到对用的特征。将提取到的 sample set 的特征和 query set 的特征在通道域进行 concatenation。将 concatenation 后的特征输入到 g 中,每一个特征向量产生一个 softmax 得分。得分最高的即为网络判断出的类别。
![]()
同样的方法,对于 k-shot,将同一类别经过 f 得到的特征进行元素级加法,再送入 g 中。损失函数使用均方误差:
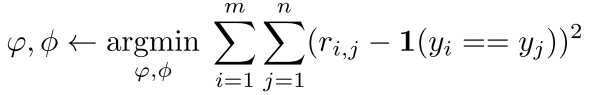
分类问题使用 MSE 损失函数不妥当,因为和激活函数 Sigmoid 同时使用有可能会产生梯度消失。但是网络的输出是 softmax 的得分,因此使用 MSE 也无大碍。
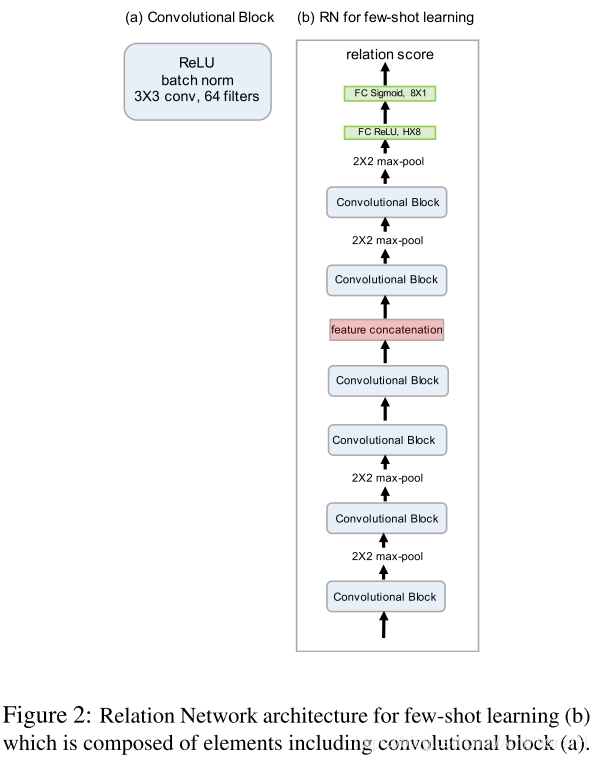
为了公平,采用和在此之前小样本方法采用的四个卷积块作为 embedding module,每个卷积块包换64个3*3卷积核、一个 batch norm和一个 ReLU 激活函数,其网络结构为:
实验结果
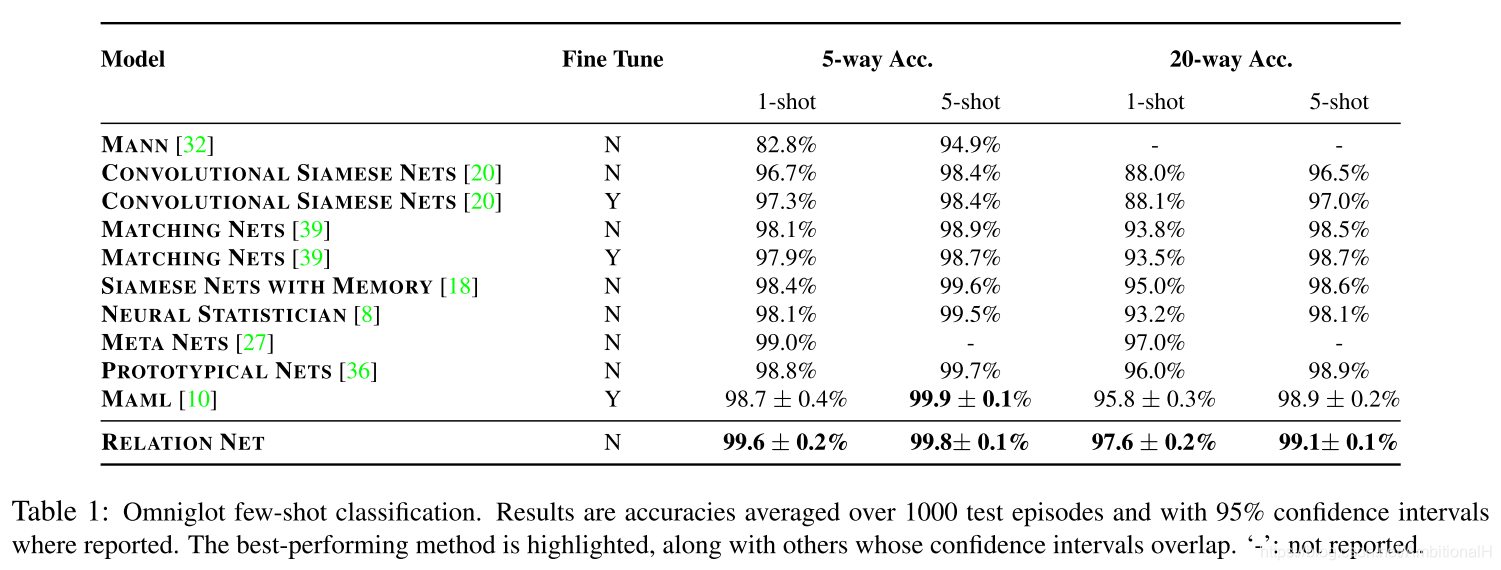
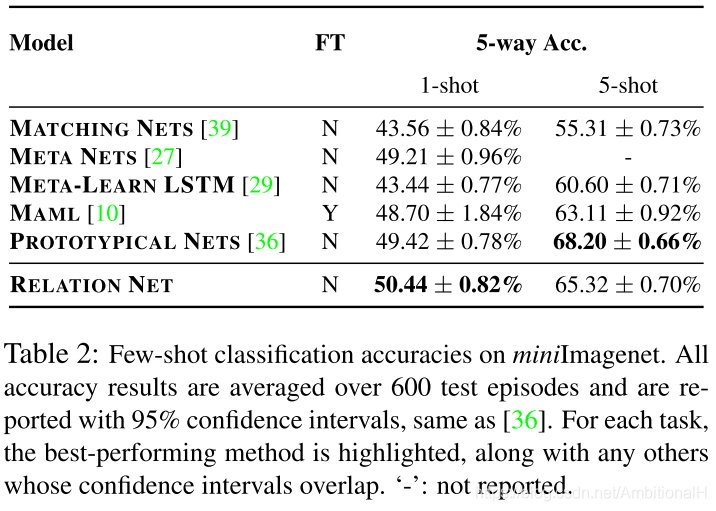
做了两个任务上的实验:few-shot 分类在 Omniglot 和 miniImagenet 这两个数据集上和 zero-shot 分类,后者不关注。第一个数据集是英文手写字符数据集,取得了不错的效果:
第二个数据集包含60000张带颜色的图片,共有100个类,每类600张图片。分别取出其中的64、16和20类作为训练、验证和测试集,验证集仅用来监视泛化性能。
作者还分析了这种结构有高精度的原因,与之前方法的距离度量不同,本文的方法距离度量是通过深度学习网络得到的,因此不用选取具体的度量函数(感觉这种方法可以用到上一篇的网络中),还用一张图来证明他的观点:

补充:
-
均方差(MSE)不适合分类问题,而交叉熵(cross-entropy)不适合回归问题。
参考:https://blog.youkuaiyun.com/weixin_41888969/article/details/89450163、https://blog.youkuaiyun.com/weixin_41888969/article/details/89450163
-
batch norm 原理
将数据归一化到同一分布,同时保留归一化前数据的特征。参考:https://blog.youkuaiyun.com/qq_25737169/article/details/79048516
- Sigmoid 函数和 softmax 函数
Sigmoid =多标签分类问题=多个正确答案=非独占输出(而对于多标签分类而言,一个样本的标签不仅仅局限于一个类别,可以具有多个类别,不同类之间是有关联的。比如一件衣服,其具有的特征类别有长袖、短袖等属性,这两个属性标签不是互斥的,而是有关联的)。Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)。
在二分类情况下,Sigmoid函数针对两点分布提出。神经网络的输出经过它的转换,可以将数值压缩到(0,1)之间,得到的结果可以理解成分类成目标类别的概率P,而不分类到该类别的概率是(1 - P),这也是典型的两点分布的形式。Softmax函数本身针对多项分布提出,当类别数是2时,它退化为二项分布。而它和Sigmoid函数真正的区别就在——二项分布包含两个分类类别(姑且分别称为A和B),而两点分布其实是针对一个类别的概率分布,其对应的另一个类别的分布直接由1-P得出。


















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









