



01 神经网络
1,神经元:神经网络的最小单元
神经网络的灵感来源于人类大脑的神经元,每个神经元就像一棵 “小树”,树突接收其它神经元的信号,细胞体处理信号,轴突把处理后的信号传给下一个神经元。
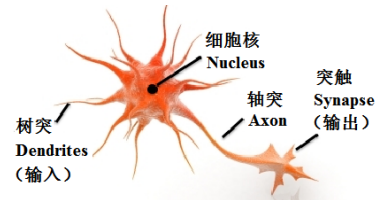
生物神经元示意图
数字世界的人工神经网络的基本单元是人工神经元,工作原理与人脑神经元类似,但更简单,用数学公式代替了生物反应:
-
输入:接收多个 “信号”(比如文字转化后的数字信息),每个信号有一个 “权重”(类似神经元连接的强弱);
-
计算:将输入信号乘以权重后相加,再通过一个 “激活函数”决定是否 “激活”(输出信号);
-
输出:激活后的结果传递给下一层神经元。
举个例子:
假设你去买肉,决定是否买肉的过程就是一个人工神经元的简化版:
-
输入:肉的价格(x1)、新鲜度(x2)、你口袋里的钱(x3);
-
权重:你对每个因素的在意程度(比如价格的权重是 0.5,新鲜度是 0.3,钱包余额是 0.2);
-
计算:价格 ×0.5 + 新鲜度 ×0.3 + 余额 ×0.2,得到一个总分数;
-
激活函数:设定一个 “购买阈值”(比如总分数超过 60 分就买)。如果总分数≥60,激活函数输出 “买”,否则输出 “不买”。
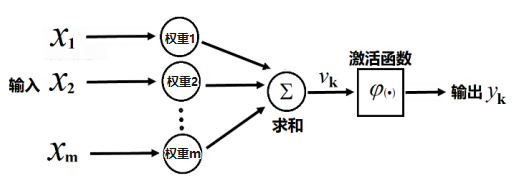
人工神经元示意图
2,神经网络:处理复杂问题
单个神经元只能做简单的判断,要处理复杂问题,需要多层神经元连接起来才行。
生物神经网络就是很多个神经元组合在一起。
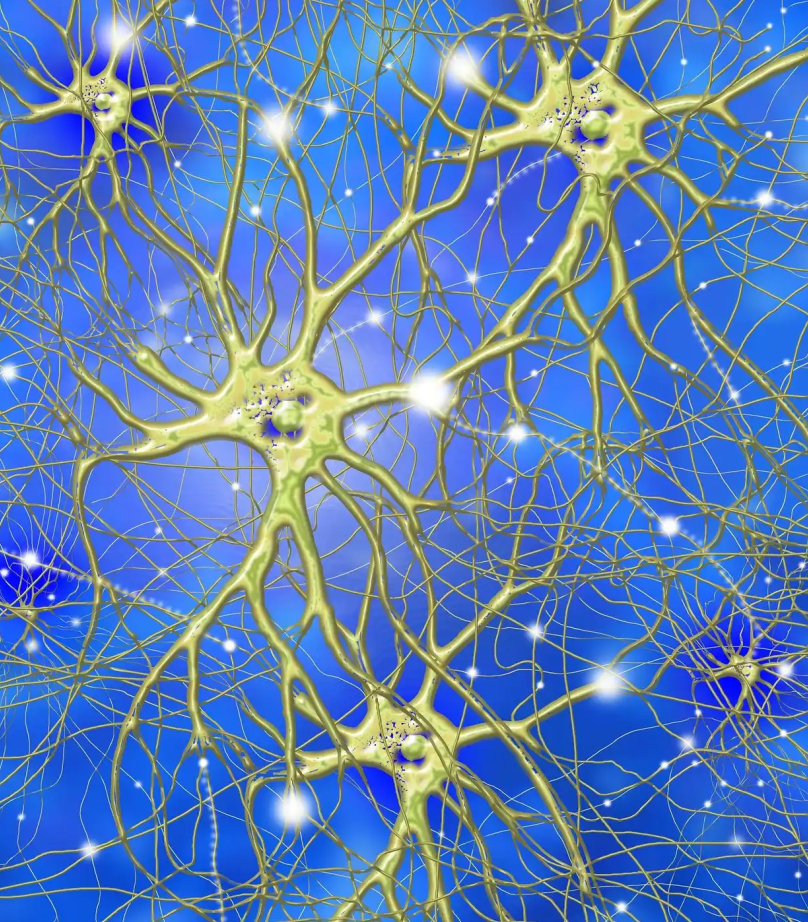
人脑神经网络图片
同样的,人工神经网络,也是由很多人工神经元组成的。
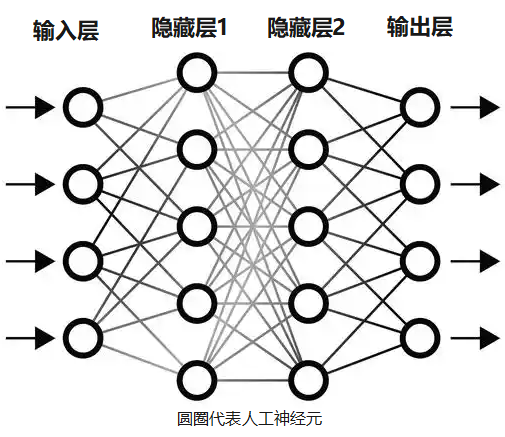
人工神经网络示意图
神经网络通过神经元层层计算,下一层的神经元的计算参数,是基于上一层神经元计算后传递的数值,最终输出结果。
比如,处理猫的图片,输入层接收图片像素信息,每个像素点对应一个输入神经元,神经网络通过运算,最后,输出层输出识别结果,这张图片为猫的几率是百分之多少。
人工神经网络的计算,非常简单,就是计算每个节点上的人工神经元的函数。
假设,将神经元上的函数设置为Y = a * X + b。那么函数的参数就是2个:a、b,最开始可以随机设置函数参数,假如将第一个神经元的函数参数设为a=2、b=3,或者根据经验设置具体数值,第一个神经元的函数就是Y = 2 X + 3。其它神经元的函数参数设置也是类似的。
参数设置成什么数值不重要,后面这些参数会变动。
还是以上面的猫为例,假设计算各个神经元的函数后,最后得出猫的几率为90%。但是我们知道这张图片猫的几率为100%,这个时候,我们按照神经网络中相反的方向,从倒数第一层开始告诉倒数第二层,你的结果错了,应该是100%,需要调整你这个神经元的函数参数,依次类推,一直将信息传递到第一层的神经元。
这时候整个神经网络,从最后一层开始修改函数参数,一直到第一层。那么,第一个神经元的函数参数就可能被从原来的2、3修改成4、5。函数被改为Y = 4 X + 5。
然后,再让神经网络处理同一张猫的图片,假设第二次计算的结果是猫的几率为95%。重复文章前面两段中提到的反向传递信息的步骤,每个神经元继续更改函数参数。
不停地重复这个循环。
假设重复到一万次后,计算得出猫的几率为99.9999%,我们认为再计算下去已经没有意义,浪费时间和电费,就可以停止了。
以上就是人工神经网络的训练过程。
3,循环神经网络(RNN)
在处理语言时,句子中的文字顺序很重要(比如 “猫吃老鼠” 和 “老鼠吃猫” 意思不同),但是早期的神经网络,无法处理这种顺序关系。于是,专门处理序列数据的循环神经网络诞生了。
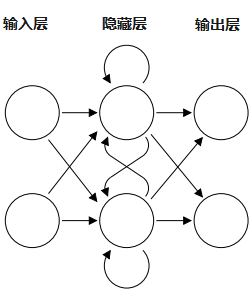
循环神经网络示意图
循环神经网络最大特点是网络中存在着环,使得信息能在神经网络中进行循环,从而实现对序列信息的处理。
RNN 的每个神经元处理完一个词后,会把当前的 “状态”(比如对前文的理解)传递给下一个词。
比如处理 “我明天要去” 时,处理 “我” 后记住 “主语”,处理 “明天” 时结合 “时间”,处理 “去” 时知道 “动作”,最终预测下一个词可能是 “哪里”“广州” 等。
循环神经网络就像玩传话游戏,每个人传话给下一个人的时候多加一个字。
当字数比较多的时候,后面的人,已经忘了前面的人开始说的话,可能只记得最后几句话。
另外,只能在一个链条处理信息,不能同时处理所有信息。
现在,轮到Transformer出场了,因为循环神经网络的两个缺陷,它刚好都能解决。
02 Transformer
Transformer架构是Google团队在2017 年的论文《Attention Is All You Need》中提出的。
Transformer是个很复杂的神经网络架构,架构图如下,其中最核心的创新就是橙色模块的多头注意力机制。
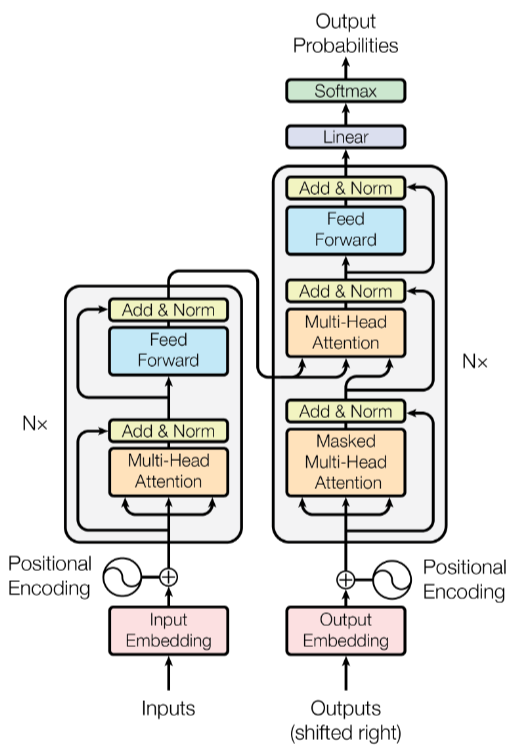
Transformer模型架构图
Transformer的架构图,如果不是专业人士,不用搞懂。
我们来说说它最核心的模块:多头自注意力。
先说什么是自注意力机制。
以句子“这只猫很可爱,因为它毛茸茸的”为例。
打个比喻吧,想象一下,这句话里所有的词,都坐在一张圆桌旁开会。当处理其中一个词(比如“它”)时,允许“它”环顾整个圆桌,看向句子里的所有其它词,并问:“你们谁对我理解自己的意思最重要?”
“它”会给其它词打分,可能会:
给“猫”打很高的分(因为“它”指代“猫”)。
给“毛茸茸的”打较高的分(解释了“可爱”的原因)。
给“可爱”打一定的分。
给“这”、“只”、“很”、“因为”等词打较低的分。
然后,“它”会把这些分数转换成参数,计算一个所有词的“加权平均值”。这个平均值包含了整个句子中对理解“它”最有用的信息。这样,“它”就能准确知道自己是代表“猫”,并且和“毛茸茸的”非常相关。
多头注意力,就像一个会议有多个小组同时讨论不同方面(如:一组讨论指代关系,一组讨论情感,一组讨论动作),Transformer通常有多个注意力头并行工作,各自关注句子不同层面的信息,然后将结果合并,让理解更全面。
基础知识先讲这么多,下面来说说AI大语言模型训练的主要过程:预训练、监督微调、奖励模型、强化学习。
(注意:我这里讲的是主要过程,并不是说训练过程只有这些步骤。)
03 预训练
预训练需先收集训练用的语料。在网络上抓取海量的网页、社交媒体平台的信息、知识百科、代码、书籍等作为训练语料。
训练的方法,跟上文中神经网络识别猫那个例子差不多,只不过这里要换成文本。
比如有一句话:今天是个大晴天。
训练的时候,给出“今天是个大晴”,然后让AI推测下一个词,如果猜的不是“天”,那就调整模型参数。
通过万亿级文本、几个月的训练,可能耗费的电量比一个城镇一年的用量都还要多,Transformer 的参数被调整到能捕捉人类语言的几乎所有规律,最后得到了一个基础模型。
04 监督微调
预训练之后的大模型,是个知识全才的学生,但是它不会解题。
这个时候,通过人类告诉大模型标准答案,比如,告诉大模型日常聊天要使用口头语,写论文要用书面语言和专业术语,告诉大模型怎么写邮件等等。
大模型通过学习这类正确的例子,学会正确的解题方法。
这些正确的例子都是人工编排出来的,相较于预训练时海量的、低质量的文本,数量不会很多,通常几万条,但质量更高。
监督微调这一步的主要作用,是让AI按照人类的方式回复,输出的内容更有针对性、更加相关、格式更加规范。
如果大语言模型学习太多的标准答案,模型可能为了模仿标准答案,显得过于刻板或缺乏创造力。这就引出了后面的强化学习。
05 奖励模型
在强化学习之前,我们先要造一个奖励模型,一个能自动判断AI回答好坏的打分器。
奖励模型是一个比较小的模型,目的是替代昂贵的人工去评价无数回答。
首先要收集偏好数据,向基础模型或微调后的模型输入大量不同的问题。
让模型对每个问题生成多个(通常是2-4个)不同的答案。
再由人类查看这些回答,判断哪个回答的更好(更安全、更有帮助、更真实、更无害、更流畅等)。
这个环节,人类不写标准答案,只做比较。
通过训练,让这个奖励模型学会模仿人类的偏好判断。
具体来说,对于人类认为更好的回答,奖励模型给出更高的分数,对于更差的回答,给出更低的分数。
06 强化学习
在强化学习阶段,大模型变成了一个游戏玩家。
每次生成回答后,奖励模型给它打分,高分像游戏中的金币,低分像扣分。
模型通过算法调整参数,让未来的回答更可能拿到高分。
比如生成友好且信息丰富的回答时得分高,模型会增强与这类回答相关的参数权重。
比如生成生硬或错误的回答时得分低,模型会减弱相关参数的影响。
这一轮的训练完成后,AI大语言模型就基本上可以回答高质量的答案了。
今年发布的很多头部大模型,就是在这个环节加大了训练量,让大模型的质量明显提升。
DeepSeek今年的迭代,主要是加强了强化学习这个环节。
07 文本生成
当你用DeepSeek的时候,你会发现它是一个词一个词的呈现的,是AI在故弄玄虚吗?亦或是故意拖延时间来更好地生成答案?并不是,大语言模型的本质就是玩词语接龙的游戏。
在神经网络和预训练的章节里,大家已经知道AI是怎么做预训练的了。
同样的,生成文本的时候,AI根据你写的提示词,然后预测下一个词。
然后根据提示词+生成的词,继续预测下一个词。是的,AI就是这么循环工作的。
这也就是为什么你看到的是一个词一个词的呈现,因为,实际它就是这么工作的呀。
因此,优质的提示词非常重要,优质的提示词,能激活神经网络中的某些区域,让你获得更优质的答案。
08 涌现
最后再说一下,为什么做了一些数学计算,AI就能写文章、写程序代码。
人工神经网络的计算,每一层人工神经元到底起了什么作用,目前没人知道,这是个黑箱算法。有人认为是在进行特征提取,可能吧。
人工神经网络与人类大脑的神经网络也不太一样,它将记忆储存在神经元的参数里。而人类大脑的记忆,并不是储存在神经元里的。
从生物学的角度去看,有个词叫“涌现”。描述了在复杂系统中,由大量个体通过相互作用产生的新属性、行为或结构,这些特性是其组成部分本身所不具备的。
例如,蚁群中,每只蚂蚁的行为都非常简单,基本上都是通过分泌、识别信息素做出反应,没有任何智慧可言。但是,当成群的蚂蚁在一起时,整个蚁群就展现出了高度的协调,比如建巢、找食、合作捕猎等。
AI大模型也是一样,大量的数学计算,最后涌现出了智能。
09 零基础入门AI大模型必看
陆陆续续也整理了不少资源,希望能帮大家少走一些弯路!
无论是学业还是事业,都希望你顺顺利利 !
1️⃣ 大模型入门学习路线图(附学习资源)
2️⃣ 大模型方向必读书籍PDF版
3️⃣ 大模型面试题库
4️⃣ 大模型项目源码
5️⃣ 超详细海量大模型LLM实战项目
6️⃣ Langchain/RAG标题一/Agent学习资源
7️⃣ LLM大模型系统0到1入门学习教程
8️⃣ 吴恩达最新大模型视频+课件


















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









