




 本文介绍了如何使用Spark和Scala对心脏病数据集进行分析,涵盖了Spark介绍、Scala安装、IDEA创建Scala项目、数据集准备以及统计分析代码的编写,通过分析揭示了年龄、血压、胆固醇水平与心脏病的相关性。
本文介绍了如何使用Spark和Scala对心脏病数据集进行分析,涵盖了Spark介绍、Scala安装、IDEA创建Scala项目、数据集准备以及统计分析代码的编写,通过分析揭示了年龄、血压、胆固醇水平与心脏病的相关性。
目录
前言
随着心脏病患者的逐年增加,我们运用有效的知识来分析统计心脏病与各数据指标的关系,来减少患有心脏病的风险
提示:以下是本篇文章正文内容,下面案例可供参考
一、Sprak是什么?
spark官网Apache Spark™ - Unified Engine for large-scale data analytics
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、SparkStreaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
————————————
二、Scala介绍与安装
1.Scala介绍
Scala是一门多范式的、纯粹的面向对象、函数式编程语言。由于Scala文件(.scala)可被编译成Java字节码,所以scala程序可以由JVM加载并运行。
由于Scala编译后得到Java字节码,所以Scala和Java本质上是一个东西,Scala和Java类可以相互调用。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.Windows安装Scala
1.将scala-2.11.12.zip解压到某个路径
2.配置SCALA_HOME和path环境变量
验证是否部署成功:
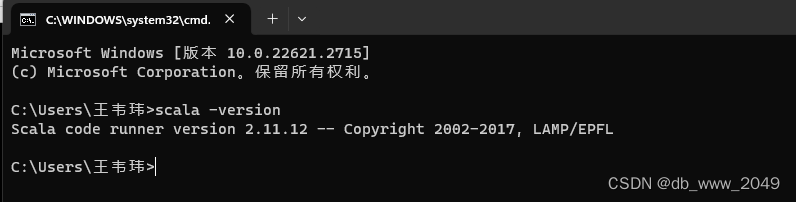
出现下面一串说明安装成功
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









