




一、HashSet
1.HashSet的定义
仓颉编程语言中定义HashSet的关键字为HashSet<T>,语法为:var/let 名称 : HashSet<T> = HashSet<T>()。使用HashSet需要导入包:import std.collection.HashSet。
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
return 0
}
注意:HashSet里面的元素是无序的,并且会自动过滤重复元素,底层是由哈希表实现的。
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5,1,1])
println(hashset.size)
return 0
}
上述代码中HashSet中有7个元素,有三个重复的元素,打印里面的数量:
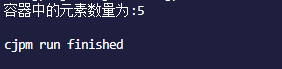
由此可见过滤了两个重复的1,打印出来的元素数量为5。
2.HashSet的遍历
(1)通过名称直接遍历
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
println(hashset)
return 0
}
结果为:
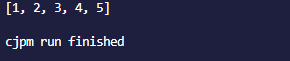
(2)通过for..in语句遍历
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
for(item in hashset)
{
println(item)
}
return 0
}
结果为:

3.HashSet的一些常用方法
(1)通过size获取元素数量
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
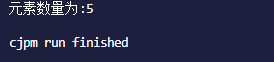
var num = hashset.size
println("元素数量为:${num}")
return 0
}
结果为:
(2)通过put()方法添加元素
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
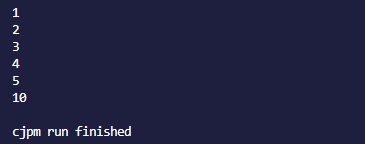
hashset.put(10)
for(item in hashset)
{
println(item)
}
return 0
}
结果为:
(3)通过remove()方法删除元素
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
hashset.remove(1)
for(item in hashset)
{
println(item)
}
return 0
}
结果为:

(4)通过clear()方法清空元素
import std.collection.HashSet
main(): Int64 {
var hashset : HashSet<Int64> = HashSet<Int64>([1,2,3,4,5])
hashset.clear()
for(item in hashset)
{
println(item)
}
println("元素数量为:${hashset.size}")
return 0
}
结果为:

二、HashMap
1.HashMap的定义
定义HashMap的关键字为:HashMap<k,v>,语法为:var/let 名称 :HashMap<k,v> = HashMap<k,v>()。使用HashMap需要导入包:import std.collection.HashMap。
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
return 0
}
注意:HashMap是键值对,元素是无序的,底层是哈希表实现的。
2.HashMap的遍历
(1)通过名称遍历
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
println(hashmap)
return 0
}
结果为:

(2)通过for..in语句进行遍历
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
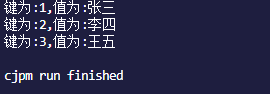
for((k,v) in hashmap)
{
println("键为:${k},值为:${v}")
}
return 0
}
结果为:
3.HashMap的一些常用方法
(1)通过size获取元素数量
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
println(hashmap.size)
return 0
}
结果为:

(2)通过put(k,v)方法来添加元素
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
hashmap.put(4, "陈六")
println(hashmap)
return 0
}
结果为:

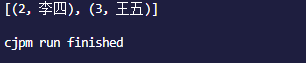
(3)通过remove(key)方法来删除元素
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
hashmap.remove(1)
println(hashmap)
return 0
}
结果为:
(4)通过clear()方法清空元素
import std.collection.HashMap
main(): Int64 {
var hashmap : HashMap<Int64, String> = HashMap<Int64, String>([(1,"张三"),(2,"李四"),(3,"王五")])
hashmap.clear()
println(hashmap)
println("元素个数为:${hashmap.size}")
return 0
}
结果为:


















 1792
1792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









