






论文:https://arxiv.org/pdf/2308.07777.pdf
代码:https://github.com/Line-Kite/GraphLayoutLM
摘要
多模态预训练transformer大幅增强了模型对富文本文件的理解能力。然而,现有的模型主要聚焦于特征(比如文本和图像),却忽略了文本结点之间的布局关系。这篇论文提出了一种全新的文档理解模型GraphLayoutLM,利用布局结构图的建模来将文档结构的布局信息注入到模型当中。这一模型基于图结构,使用一种图的重排序算法来调整文本的顺序。另外,这一模型使用一种布局意识(layout-aware)+多头(multi-head)+自注意力(self-attention)层来学习文档的布局信息。研究团队提出的模型能够通过对文本元素的空间安排进行学习,提高对文档的理解能力。团队在FUNSD, XFUND和CORD等基准数据集上进行了评估,并获得了最好的评估结果。实验结果表明研究团队提出的方法对现有的模型有很大提升,并说明了在文本理解模型中增加对文档布局信息的重要性。研究团队还对模型的各个部分进行了消融实验,来评估模型各个组件对识别的贡献。实验结果表明,图的重排序算法以及布局意识+多头+自注意力层都在取得最好的识别率上有关键作用。
I. Introduction
富文本文档理解(VRDU, Visually-Rich Document Understanding)的目标是分析多种具有丰富结构和复杂格式的扫描/电子文档。这可以在广泛的文本相关场景中提供帮助,例如报告/收据理解、文档分类、文档视觉问答等。由于应用场景多样,VRDU在研究领域和工业应用方面都受到了很多关注。
不同于传统的自然语言理解(NLU, Natural Language Understanding),VRDU不仅需要文本的信息,也需要将文档的结构、视觉信息进行结合来对分散于文档各处的非连续文本进行综合理解。由于文档类型的多样性以及结构的复杂性,仅仅使用文本数据来完全理解一个具有复杂的内容、位置信息的文档是很难的。文档的理解需要将多模态的信息进行有意义且高效的整合,才能让模型更深入地探索到文档的含义以及潜在的逻辑关系。
早期的VRDU研究中,研究者尝试通过单模态以及浅多模态的融合方法来分析文档。这些方法依赖于预训练NLP和CV模型,并将多模态的信息进行整合。但是,这些任务特异性的方法需要大量的标注数据来进行监督学习。随着近年来预训练技术的推进,很多复杂的文档模型和预训练方法相继出现,例如LayoutLM,LayoutMv2和BROS。最新提出的LayoutLMv3, ERNIE-Layout也是对多模态预训练模型的尝试,并在很多VRDU任务上都有很好的表现。尽管如此,现有的模型还是有一些限制。
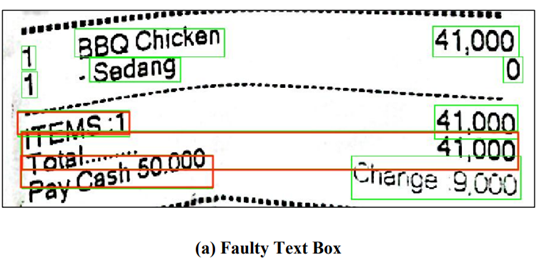
(1)原始顺序和正确理解顺序不一致:分散于文档不同位置的文本是不连续的,这意味着不同位置的检测框在输入模型之前需要进行拼接。一些前人的工作忽视了文档中的阅读顺序,而直接用未调整的原始顺序作为模型的输入。如图所示,在随机或固定阅读顺序的前提下,获得文档中文本节点的潜在关系是较难的,从而对机器理解造成影响。合理且有序的理解顺序可以反映不同文本结点之间的逻辑和位置关系,这对消除歧义有很好的作用。

(2)仅有视觉信息不足以表现文档结构。一些之前的工作考虑了多模态视觉和2D位置特征来理解文档的布局。但是,这需要模型自己学习到文档结点之间的关系,从而影响了模型对文档布局的理解。一方面,低质量的文档图片会导致错误的文本框或其他图像信息的干扰。因此,仅靠视觉特征来反映文档的结构是不够的。另一方面,图像编码器的输入尺寸是受限的,实际过程中一般将图像缩放成固定大小来达到要求。如图所示,在图像的处理过程中,LayoutLMv3将图片缩放为224×224,这可能使图片变得模糊或产生很大的信息损失,从而影响模型的理解。并且,缩放会加剧错误文本框和信息干扰的影响,因为在缩放后的图像中将更难将其与普通信息区分开来。另外,现有通过预先从原始图像中提取的2D位置信息来表示文档结构是不直观的。因为文档的结构的相关性并不仅仅有空间上的相关,Encoder很难去仅凭这些2D位置信息来理解文档结构。

在这篇文章中,团队提出一个VRDU预训练语言模型GraphLayoutLM,这是一个LayoutLMv3的改进版本,用布局关系图来提高对文档的理解效果。和先前关注特征的模型不同,GraphLayoutLM专注于文本结点之间的位置关系,并使用图数据结构来表现这种布局关系。研究团队引入了两个优化策略:图顺序优化和图mask优化。
第一,我们将文档的步距信息建模为一个文本结点构成的层级化的关系结构图。比如说,一段话可能由几行文本组成,段落又组成章节,再组成一整个文档。用这种层级化的文档结构作为建立文档布局图的基础。要描述层级化的文档结构,我们预先将文档的结构建模为一棵树。由于兄弟结点之间的关系往往比非兄弟结点密切,我们对兄弟结点之间建立起位置关系,从而将树变为一个布局图。
文档的阅读顺序多种多样,合适的阅读顺序可以帮助更好地理解内容。研究团队使用以原始层级信息建立的树为基础的布局图来得到合适的阅读顺序。获得的方法包括对布局树(layout tree)的深度遍历,这会将结点安排在序列中与其强相关结点的邻近位置。同时,还以结点在图中的位置信息为基础对兄弟结点进行排序。通过对图的顺序进行调整,我们可以获得较优的阅读顺序,这样的增强策略可以提高对文档理解上的表现。
受到图注意力网络(Graph Attention Networks, GAT)的启发,研究团队尝试通过自注意力策略将布局图的信息整合到VRDU模型中。GraphLayoutLM引入图意识(graph-aware)自注意力层,通过优化图掩码(graph mask)来提高标准自注意力层的表现。具体实现上,通过邻接矩阵来融入布局图的信息。图掩码有选择性地屏蔽关系不紧密的元素的注意力分值,并注入文本结点之间的关系。这一方法使得模型能够更好地集中于相关结点之间的关系,提升了准度。
研究团队在一些典型VRDU任务上做了评估实验,数据集包括FUNSD(噪声很多的表单)、XFUND(表单票据理解数据集)、CORD(收据数据集)。实验表明GraphLayoutLM在这三个数据集上都获得了目前最好的表现,并在FUNSD和XFUND数据集上领先第二名2.29%和1.54%。另外,笑容饰演表明团队提出的图顺序优化和图掩码优化策略均对文档理解任务有效。
II. Related Works
自监督和预训练技术发展很快,并已经成功应用于VRDU领域。LayoutLM是第一个在文档理解上将2D布局信息和文本结合并应用掩码语言模型(Masked Language Modeling)预训练任务的模型。在这之后,很多新颖的多模态预训练模型相继出现,例如LayoutLMv2,BROS,StructuralLM和LayoutLMv3。LayoutLMv3作为新一代文档预训练模型,在多个数据集上都获得了很好的表现。
然而,之前提到的方法都只集中于布局或者视觉特征,没有考虑文档的阅读顺序。在现实中,文档在读写过程中都有特殊的顺序,这对模型的学习有非常重要的参考价值。LayoutReader是一个在ReadingBank(一个大型阅读顺序数据集)上训练的多模态阅读顺序分析模型,能有效地提取文档的正确阅读顺序,但是这一模型较为复杂,推理时间较长,会严重影响文档理解的速度。XYLayoutLM提出一个增强的XY Cut策略来对输入序列进行排列来得到一个合适的阅读顺序。除了XYLayoutLM,ERNIE-Layout也强调了文档阅读顺序对理解文档的作用,并使用一个高级的文档布局分析工具来对文本输入进行排序。与这二者不同的是,GraphLayoutLM依赖于图结构来对输入序列进行排序。研究团队相信,这一方法会比传统的无训练方法更好的反应文本结点之间的逻辑关系。
因为文档结点的离散性,很适合用图结构来表示布局。在VRDU领域曾有过应用图结构的尝试,例如将GCN(图卷积神经网络)用于文档理解,并在信息的提取上取得了进展。ERNIE-mmLayout是一个基于图的多粒度(multi-grained)多模态的Transformer,将粗粒度的信息融合入现有的细粒度多模态预训练模型。ROPE是一种新的基于GCN的位置编码技术,被用于理解文档中文字的顺序表现。FormNet使用GCN,将每一个单词与其相邻单词的嵌入表示(representation)结合起来,构建Super-Token。这些模型的具体表现与GraphLayoutLM的对比可参考论文附录的实验数据。
III. GraphLayoutLM
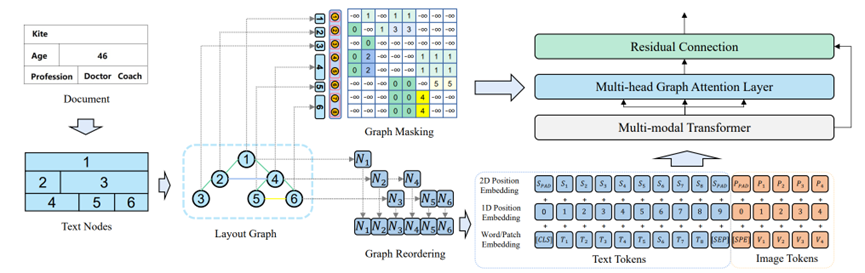
这一模型基于现有最好的模型LayoutLMv3,如图所示,文件中的文本往往分散在不同的位置,当使用OCR工具对文档进行分析时,我们不仅能得到文本的内容和对应位置,也可以得到整个文档的布局信息,例如章节、段落、行等。通过使用这些布局和位置信息,建立一个图来表示整个文档的布局。GraphLayoutLM通过关系图,建立图优化序列(Graph optimization sequence)和图掩码(Graph mask),用于输入和Transformer编码的过程。和LayoutLMv3相比,GraphLayoutLM通过更加符合逻辑的输入顺序来理解文档,并能够更直接地学习到文本结点之间的关系。
3.1 基础架构
3.1.1 多模态embedding
和LayoutLMv3一样,将文本、位置和图像在输入至多模态Transformer前转换成文本和图像的embedding。文本的embedding由文本本身、1D和2D位置信息组成。1D位置指这一文本在输入序列中的索引,2D布局位置表示文本框的坐标。同时,图像embedding使用与ViT相同的处理方法。在LayoutLMv3中,文档图像的大小首先调整为H×W。将图像表示为I ∈ R^(C×H×W),其中CHW分别表示通道数,宽度和高度,图像首先被切分为P×P的块组成的序列。这些图像块被线性地投影到维度D的向量中,并且扁平化为长度M = HW/P^2的向量序列。最后,text embedding和image embedding进行拼接,作为多模态Transformer encoder的输入。
3.1.2 多模态Transformer
和LayoutLMv3的方法类似,研究团队对GraphLayoutLM中的多模态Transformer做了一定的调整。首先,使用![]() ,
,![]() ,
, ![]() 来表示可学习的1D和2D位置偏置,这些偏置的值在不同的attention head中是不同的,但是在所有encoder层是公共的。使用(xi, yi)作为第i个检测框的左上角坐标,计算空间注意力(spatial-aware attention)得分:
来表示可学习的1D和2D位置偏置,这些偏置的值在不同的attention head中是不同的,但是在所有encoder层是公共的。使用(xi, yi)作为第i个检测框的左上角坐标,计算空间注意力(spatial-aware attention)得分:
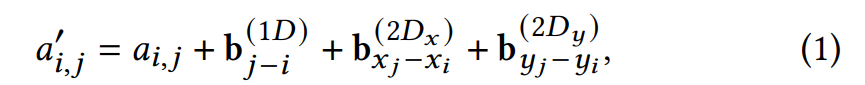
aij是指原始注意力得分。另外,研究团队对CogView中的自注意力计算公式进行了修改:
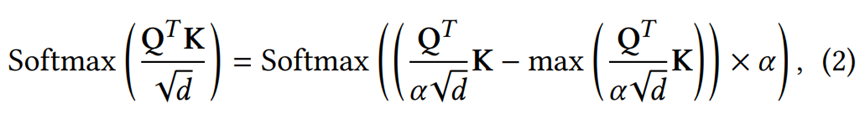
其中α是缩放系数。
3.1.3 Pretraining Objective
研究团队最初的目标是通过布局图的方式来增加VRDU的预测表现,同时也采取了三种非监督预训练方法:MLM, MIM, WPA,这与LayoutLMv3中采用的方法一致。通过整合这些技术,最终的pre-training objective定义为![]() , 详细介绍可在论文附录中查看。
, 详细介绍可在论文附录中查看。
3.2 Layout Graph Modeling
在GraphLayoutLM中,将每一个基本的文本结点当做分割层级的实体来处理,代表一行文本。整个文档是由这些文本行来组成,用一个结点的集合![]() 来表示。但是,并不是这些行中的所有文本结点都是相关的。为了找到文本之间的联系,同时避免冗余的链接,我们提取文档的层级化信息(例如章节)和布局信息。例如一个段落含有的文本行可以被定义为
来表示。但是,并不是这些行中的所有文本结点都是相关的。为了找到文本之间的联系,同时避免冗余的链接,我们提取文档的层级化信息(例如章节)和布局信息。例如一个段落含有的文本行可以被定义为![]() ,P代表段落区域。通过文本结点的2D位置来选定表示(represent)整个段落的文本结点np:
,P代表段落区域。通过文本结点的2D位置来选定表示(represent)整个段落的文本结点np:
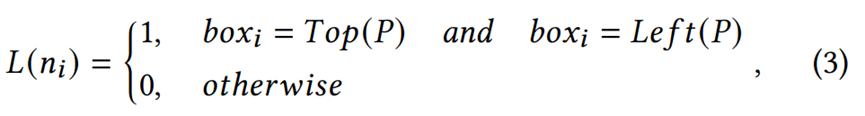
L(ni)决定了结点ni是否可以表示整个段落,这一决策以ni的2D位置信息(表示为boxi)和段落P中最上方和最左侧的结点(表示为Top(p)和Left(p))的2D位置信息为基础,是对人们书写文档习惯的一种模拟。
在决定了段落P中的代表结点np后,将np与这个段落中其他的文本结点建立Parent-Child关系,从而建立一棵子树Tp,可以用以下公式表示:
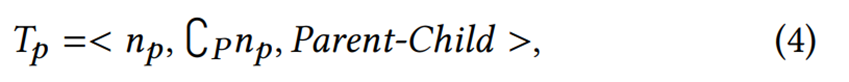
其中![]() 表示除了np以外的其他结点。
表示除了np以外的其他结点。
使用上述的方法,我们可以得到一个子树的集合,表示为![]() ,为了从这个森林得到一棵整体的树,我们需要引入一个伪根节点ng,来将所有子树的根节点进行连接,通过这一操作,我们将文档建模为了一个布局树Tg
,为了从这个森林得到一棵整体的树,我们需要引入一个伪根节点ng,来将所有子树的根节点进行连接,通过这一操作,我们将文档建模为了一个布局树Tg
布局树通过父子结点的关系反映了整个文档的层级化结构。同一层级中的各个结点的空间关系也是文档结构信息的一个重要方面,对理解文档也很有帮助。为了充分使用文档结点的空间信息,我们将文档树Tg中的兄弟结点的位置信息进行比较,来决定其空间关系。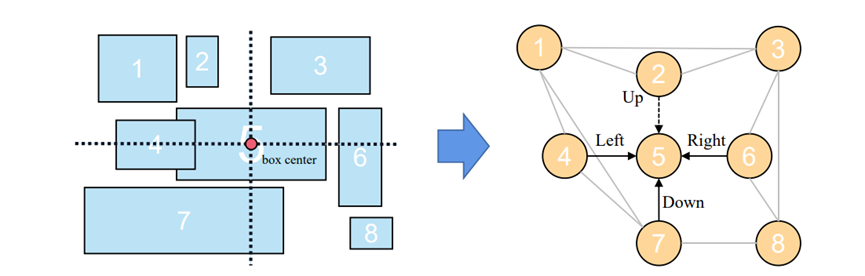
假设结点ni的2D位置信息![]() ,其中
,其中![]() 和
和![]() 表示长方形框的左下角和右上角的点坐标。并可以算出框的中点
表示长方形框的左下角和右上角的点坐标。并可以算出框的中点![]() ,
,![]() 。比较过程中,如果结点nj的2D位置nj与
。比较过程中,如果结点nj的2D位置nj与![]() ,
,![]() 有相交,则可以根据其2D位置建立如下关系:
有相交,则可以根据其2D位置建立如下关系:
 这个关系是单向的,也可以通过构建一个反向关系来将其变为双向关系。结合位置关系后,可以将文档关系树进化为文档的图结构G:
这个关系是单向的,也可以通过构建一个反向关系来将其变为双向关系。结合位置关系后,可以将文档关系树进化为文档的图结构G:
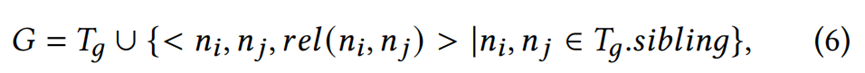
Tg.sibling代表Tg中的兄弟结点集。
3.3 Graph Reordering Strategy
通过将文档的布局建立为图,我们可以对输入文本的顺序进行优化来促进对文档的理解。现有的一些方法,例如XYLayoutLM,但其仅仅依赖于2D布局中位置的相关性,忽视了从视觉信息中提取出来的层级结构。
我们的布局图设计目的是获取可以理解的空间关系,可以给阅读顺序的优化提供一定的灵活性。由于不同的人阅读文档的习惯顺序不同,因此合理的阅读顺序也不是唯一的。另外,我们认为从布局图中提取的阅读顺序有助于模型识别出文本结点中的潜在联系,从而提高对整体的理解。
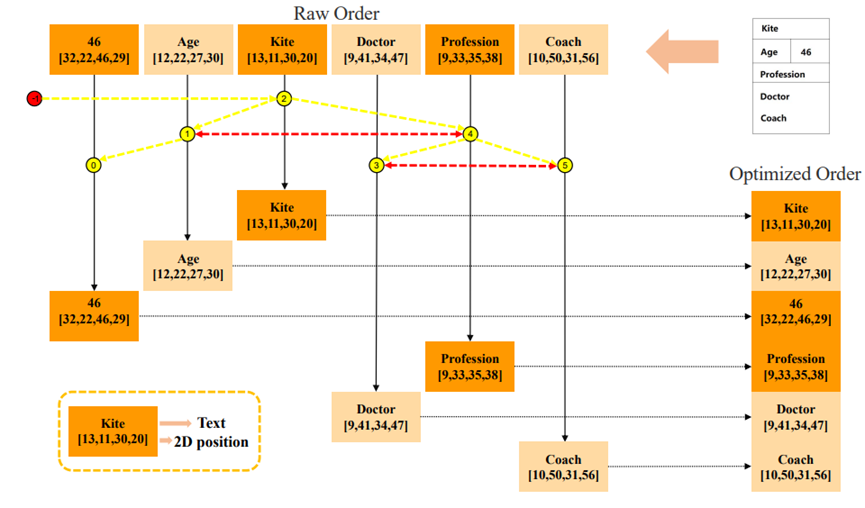
Hierarchical Reordering:层级化重排序的过程包括对布局图的深度优先遍历操作。注意,之前建立的根结点是一个伪结点,本身并不包含有意义的信息,并且在输入序列构建的过程中需要将其移除。在遍历的过程中,结点以“父亲->子结点->兄弟结点”的顺序进行遍历。这种DFS搜索顺序加强了结点和其相邻区域的连接。
Sibling Reordering:层级化重排序基于文本结点的层级化关系来对输入序列进行优化。为了对相同父结点的各个子结点之间进行一个较优的排序,我们还需要一个额外的规则来对同级结点之间的顺序进行调整。因此,我们利用文本结点的检测框位置信息,根据它们的位置关系来对同一层级的文本序列进行排序。排序的逻辑就是在同一级的兄弟结点中,按照“从上到下,从左到右”的顺序排序。具体来说,将文档最上方的文本结点置于优先位置,如果垂直方向上的位置大致相同,再比较水平方向的位置,靠左的结点优先。通过使文本输入以人类的阅读习惯进行排序,能使模型对结点之间的逻辑关系产生更好的理解。

3.4 图掩码(Graph Masking)策略
文档布局图含有对文档结构丰富而清晰的信息,用边的方式表达了文本结点之间的位置和层级关系,体现了文本之间的逻辑联系。例如,在一个典型的Q&A格式中,answer结点一般会出现在对应question结点的右侧或者下侧。为了在文档表示学习中融入此种图信息,研究团队提出了一个全新的图掩码策略。
前面的图3中展示了文本token和文本结点之间的双射关系,并且这种关系是满射的。为了在Transformer编码中实现图掩码,我们将图中的结点之间的关系转换为文本token之间的关系。具体来说,任意文本结点na![]() 中的token
中的token ![]() 和文本结点
和文本结点![]() 中的token
中的token ![]() ,有着相同的关系,
,有着相同的关系,![]() ,这一关系完成了文本结点之间到token之间的映射。
,这一关系完成了文本结点之间到token之间的映射。
尽管被OCR的识别的文档被线性化为一个语言序列,这一序列与自然语言的顺序并不相同。在线性化过程中被安排到相邻的token之间可能并没有较强的关系。相反,在序列中相隔较远的token反而可能有更强的关系,由于有许多同级的token,它们被安排到离对方很远。因此,为了从encoding的角度来反映文档的结构,研究团队提出一个优化的图意识(Graph-aware)Transfromer层,在计算文本表示的自注意力得分的过程中加上一个包含关系信息的图掩码Mg。这引导模型将注意力集中于布局中相关联的部分,并忽略不相关的部分,从而减少了不相关信息对理解的影响,使模型能够意识到文档的结构。对于图掩码![]() ,元素
,元素![]() 的计算方式如下:
的计算方式如下:
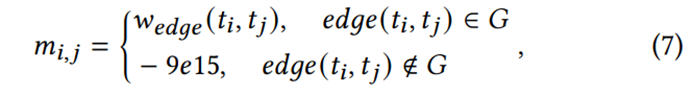
![]() 表示token ti,tj之间的relation标签权重。
表示token ti,tj之间的relation标签权重。
图意识transformer的text encoding中,同样部署了多头(multi-head)自注意力机制,token ti,tj的自注意力通过以下公式计算:
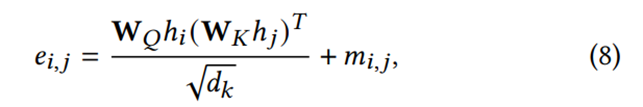
![]() 和
和![]() 是自注意力中可学习的投影权重(projection weight),hi和hj则是token ti和tj的token表示输入。
是自注意力中可学习的投影权重(projection weight),hi和hj则是token ti和tj的token表示输入。
由于图掩码的存在,模型在自注意力学习过程中会选择性地忽略没有边关系的元素,并将布局的结构注入文本表示中。最终的文本表示Hg由以下公式计算:
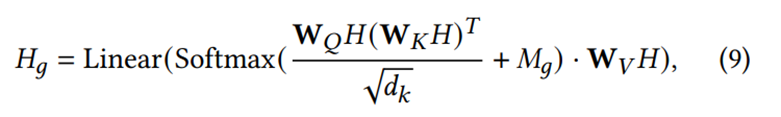
H是输入的文本表示,![]() 是可学习的投影权重。
是可学习的投影权重。
为了防止布局图建立错误导致的潜在信息丢失,我们使用残差连接来将输入文本表示和输出进行融合,这允许我们在一定程度上保持输入的信息。最终,输出融合后的结果用于下游的任务:
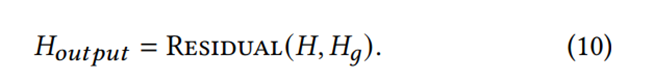
实验数据+代码实现细节待更新。

















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









