




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
本文所有资源均可在该地址处获取。
概述
注意力机制的发展历程体现了人工智能领域对模型表达能力和效率的不断追求。从最初在序列模型中的应用,到Transformer模型的提出,再到当前在各个领域的广泛应用,注意力机制已经成为现代人工智能模型的核心组成部分。随着研究的深入,注意力机制将继续演化,推动人工智能技术的发展。因此提出更好的注意力机制,对于模型性能的提升很有帮助。
注意力机制的特点
注意力机制在人工智能模型中的重要性体现在以下几个方面:
捕获长距离依赖
在传统的序列处理模型中,长距离的元素之间的依赖关系往往难以捕捉。注意力机制通过直接建立远程元素之间的联系,有效地解决了这一问题,这对于翻译、文本摘要等任务尤为重要。
并行化处理
尽管RNN及其变体可以处理序列数据,但它们通常是按顺序处理信息的,这限制了并行处理的能力。而注意力机制可以同时考虑序列中的所有元素,使得模型能够更高效地利用现代计算资源进行并行计算。
重要性的加权
注意力机制允许模型为输入序列的不同部分分配不同的权重,这样可以更加聚焦于对当前任务更为重要的信息,提高了模型处理信息的效率和质量。
灵活性
注意力机制能够以灵活的方式整合到各种模型结构中,不仅限于序列到序列的任务,也可以用于图像识别、语音识别等其他领域。
解释性
注意力权重可以为模型的决策提供一定的解释性,通过观察权重分布,我们可以了解模型在做出预测时关注哪些输入部分,这在某些需要模型可解释性的应用场景中非常重要。
减少参数
在处理长序列时,如果不使用注意力机制,模型可能需要大量的参数来存储长距离的信息。而注意力机制通过动态权重连接不同元素,减少了模型的参数数量。
适应不同类型的注意力:注意力机制可以根据不同的任务需求设计成多种形式,如自注意力(self-attention)、多头注意力(multi-head attention)、全局注意力和局部注意力等,这使得模型能够更好地适应不同的应用场景。
促进模型创新
注意力机制的提出推动了后续一系列研究和新模型的发展,如Transformer、BERT、GPT等,这些模型在自然语言处理、计算机视觉等领域都取得了突破性的成果。
Transformer Attention
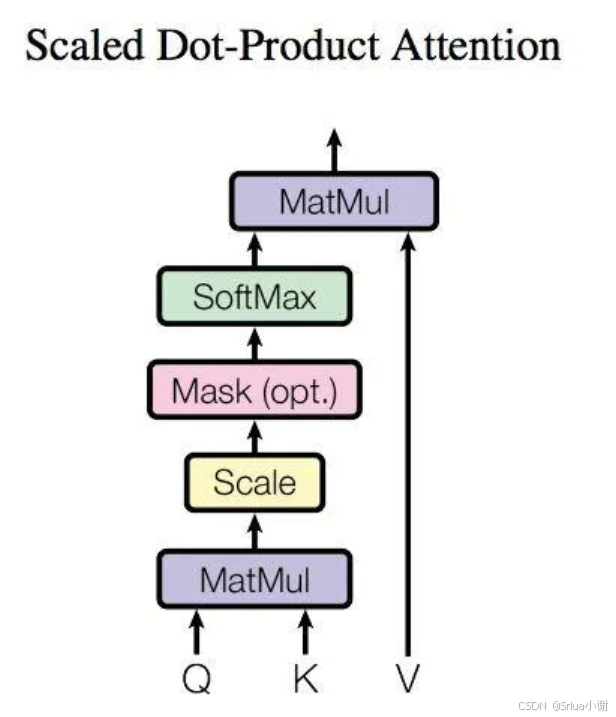
MatMul(矩阵乘法):首先对输入数据进行两次矩阵乘法操作,分别得到Q(Query)、K(Key)和V(Value)。这一步是为了从原始数据中提取出查询、键和值向量。
Scale(缩放):由于点积可能会产生很大的数值,为了保持数值稳定性,通常会对点积进行缩放处理。在Scaled Dot-Product Attention中,缩放的因子是1dkdk1,其中dkdk是键向量的维度。
SoftMax:经过缩放处理的点积结果会通过一个SoftMax函数转换为概率分布。SoftMax函数确保了所有输出的概率之和为1,从而可以解释为一个有效的注意力权重分布。
Mask(可选,掩码):在某些情况下,可能需要对某些位置的信息进行屏蔽,比如在序列任务中未来的信息不应该影响当前的处理。这时就会用到掩码来设置这些位置的权重为0。
第二次MatMul:最后,将得到的注意力权重与V(Value)向量进行第二次矩阵乘法,以加权求和的方式融合来自不同位置的值信息,得到最终的输出。
Transformer Attention代码
import torch
import torch.nn as nn
x=torch.rand(16,100,768)
model=nn.MultiheadAttention(embed_dim=768,num_heads=4)
print(model(x,x,x))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









