






基础版本
爬取网页后直接将前端html代码不加处理的输出
# pip3 install requests
import requests
# request the target URL
def crawler():
response = requests.get("https://www.scrapingcourse.com/ecommerce/")
response.raise_for_status()
print(response.text)
# execute the crawler
crawler()
无限增生的爬虫
从第一个链接开始,记录已经遍历过的链接;
并且从这个链接爬取的html代码中记录 a[href] 的链接,存储到将要遍历的列表;
对于已经爬取的链接,直接continue处理
# pip3 install requests
import requests
def crawler():
while urls_to_visit:
# get the page to visit from the list
current_url = urls_to_visit.pop(0)
print(current_url)
if current_url in visited_urls:
continue
# 记录访问过的url到列表中
visited_urls.add(current_url)
try:
response = requests.get(current_url, timeout=5) # 设置超时时间,避免死循环
response.raise_for_status() # 检查请求是否成功
except requests.RequestException as e:
print(f"请求失败: {current_url}, 错误: {e}")
continue
# parse the HTML
soup = BeautifulSoup(response.text, "html.parser")
# collect all the links
link_elements = soup.select("a[href]")
for link_element in link_elements:
url = link_element["href"]
if url.startswith("#"):
continue # ignore internal links
# convert links to absolute URLs
if not url.startswith("http"):
absolute_url = requests.compat.urljoin(target_url, url)
else:
absolute_url = url
# ensure the crawled link belongs to the target domain and hasn't been visited
if (
absolute_url.startswith(target_url)
and absolute_url not in urls_to_visit
):
urls_to_visit.append(url)
# pip3 install requests beautifulsoup4
from bs4 import BeautifulSoup
target_url = "https://www.scrapingcourse.com/ecommerce/"
# initialize the list of discovered URLs
urls_to_visit = [target_url]
visited_urls = set() # 记录已访问的 URL,防止重复爬取
# execute the crawler
crawler()
无限增生的效果

部分链接爬取失败后会返回错误信息
变式:爬取github android cve链接
import requests
from bs4 import BeautifulSoup
import csv
import json
import time
# GitHub Android CVE 搜索页面
base_url = "https://github.com/search?q=android%20cve&type=repositories"
# 存储要访问的 URL
urls_to_visit = [base_url]
# 记录已访问的 URL,防止重复爬取
visited_urls = set()
# 存储爬取的 GitHub 仓库信息
repo_data = []
# 设置请求头
headers = {"User-Agent": "Mozilla/5.0"}
def crawler():
while urls_to_visit:
current_url = urls_to_visit.pop(0)
# 如果已经访问过,则跳过
if current_url in visited_urls:
continue
print(f"正在访问: {current_url}")
visited_urls.add(current_url)
try:
# 发送请求
response = requests.get(current_url, headers=headers)
response.raise_for_status()
# 解析 HTML
soup = BeautifulSoup(response.content, "html.parser")
# 提取仓库信息
repo_containers = soup.find_all("div", class_="search-title")
for repo in repo_containers:
# 获取仓库名称和链接
link = repo.find("a")
if not link:
continue
repo_name = link.get_text(strip=True)
repo_url = "https://github.com" + link["href"]
# 获取描述
description_tag = repo.find_next("p")
repo_description = description_tag.get_text(strip=True) if description_tag else "无描述"
# 获取 Star 数
star_tag = repo.find_next("a", class_="Link--muted")
repo_stars = star_tag.get_text(strip=True) if star_tag else "0"
# 存储数据
repo_data.append(
{
"Name": repo_name,
"URL": repo_url,
"Description": repo_description,
"Stars": repo_stars,
}
)
# 查找下一页链接
next_page_link = soup.find('a', string='Next') # 查找文本为'Next'的<a>标签
if next_page_link and 'href' in next_page_link.attrs:
next_url = next_page_link['href']
urls_to_visit.append(next_url)
print(f"发现下一页: {next_url}")
# 防止爬取过快,被 GitHub 限制
time.sleep(2)
except Exception as e:
print(f"访问 {current_url} 时出错: {e}")
continue
# 执行爬取
crawler()
# 打印 JSON 数据
print(json.dumps(repo_data, indent=4, ensure_ascii=False))
# 保存到 CSV 文件
csv_filename = "github_android_cve.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["Name", "URL", "Description", "Stars"])
writer.writeheader()
writer.writerows(repo_data)
print(f"数据已成功保存到 {csv_filename}")
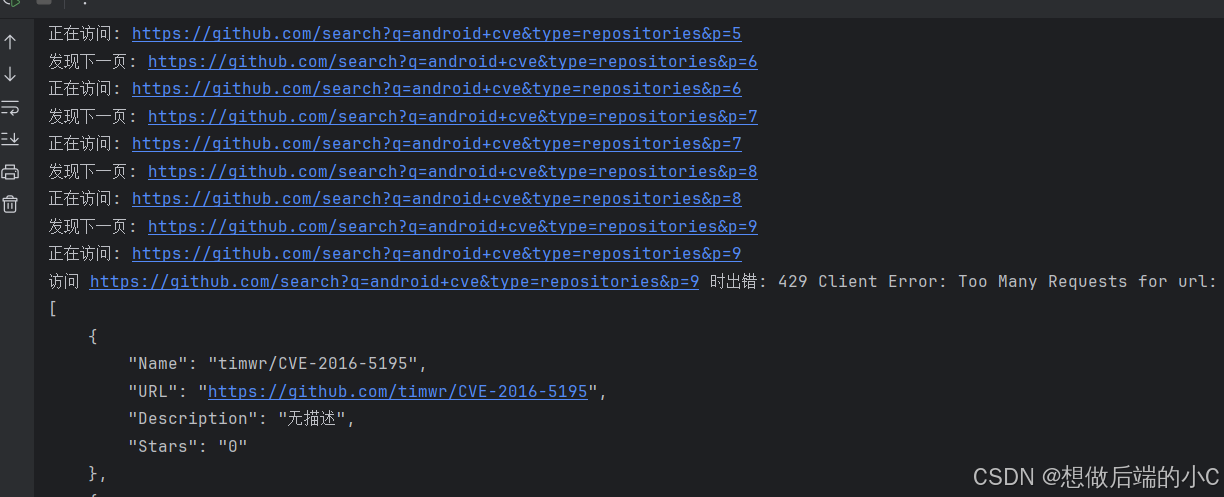
输出效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









