




 本文深入解析MapReduce2.x架构设计,包括Yarn的ResourceManager与NodeManager角色,以及MapTask与ReduceTask的工作流程。通过WordCount示例,讲解输入分片与MapTask的关系,探讨生产环境中文件格式与压缩格式的选择。
本文深入解析MapReduce2.x架构设计,包括Yarn的ResourceManager与NodeManager角色,以及MapTask与ReduceTask的工作流程。通过WordCount示例,讲解输入分片与MapTask的关系,探讨生产环境中文件格式与压缩格式的选择。
- 2.1、初识MapReduce
- 2.2、MapReduce2.x的架构设计
- 2.3、解析wordcount.java
- 2.4、Map Task的启动个数由谁来决定?
- 2.4、生产上文件格式、压缩格式的考量?
- 2.5、WordCount流程图解析(Shuffle)
一、上次课程回顾
- https://blog.youkuaiyun.com/SparkOnYarn/article/details/105107870
二、Hadoop五
2.1、初识MapReduce
MapReduce主要分为Map+Reduce;会涉及代码编程:
Map --> 映射
Reduce --> 聚合
映射的举例如下:
select a+1 as a from t
| a | a+1 |
|---|---|
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
聚合的举例如下:
select id,count(0) from t group by id
1 1 2 3 4
- 有2个1,1个2,1个3,1个4
本次课程主要涉及MapReduce2.X
2.2、MapReduce2.X的架构设计
Yarn:ResourceManager、NodeManager
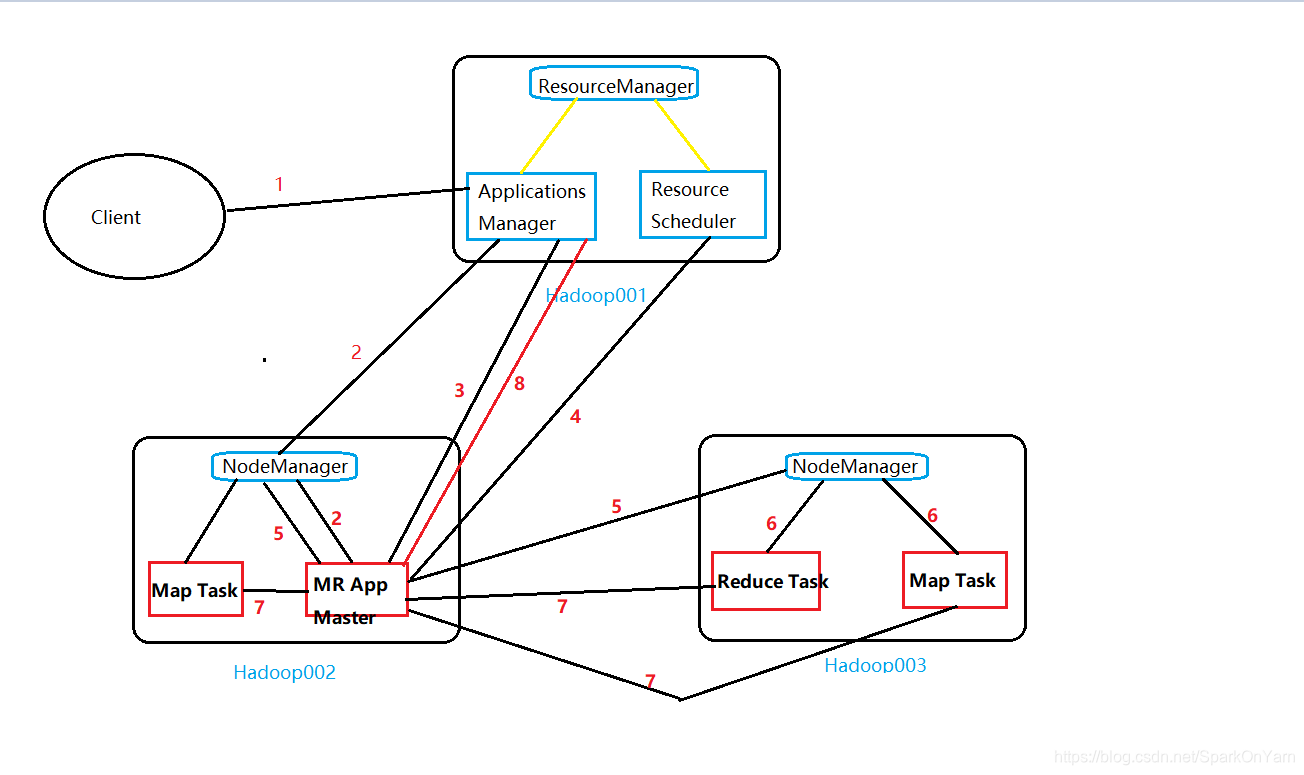
1、MapReduce是run在Yarn上的,MR on Yarn的流程 <> 也叫mr 提交job <> MapReduce的架构设计.
-
我们使用ps -ef查看到的是进程,applications Manager -->应用程序管理器;resource scheduler --> 资源memory+cpu调度器;
-
在NodeManager中红框圈出的表示的是容器,container是虚拟的概念,属于NodeManager节点上专门用来计算MR、Spark计算的最小单元
MapReduce在run的时候分为map task和reduce task;
流程详解:
1、用户向Yarn提交应用程序(jar文件、sql),其中包括ApplicationMaster的主程序、启动ApplicationMaster的命令;应用程序也叫作业job、app、application
2、ResourceManager为该job分配第一个container容器,运行job的applicationMaster;
3、此时已经启动了一个MR App Master,主程序启动后就是它来干活了,App Master向Application Manager注册,这样就可以在我们的web界面查询到这个job的运行状态(直到整个作业结束都会有一个状态显示);
4、注册完了之后MR App Master主程序采用轮询的方式通过RPC协议向ResourceManager申请和领取资源;
5、一旦App Master拿到资源,就与对应的NodeManager进行通信,要求启动任务;
6、NodeManager为任务设置好运行环境(就是划分一块内存和CPU来运行app master),将任务启动命令写在一个脚本里,并通过该脚本启动任务task;
//比如在hadoop002的机器上启动一个Map Task,在hadoop003的机器上启动一个Map Task和一个Reduce Task。
//生产上并不一定是map task全部运行完了才会启动reduce task
7、各个task通过rpc协议向我们的App Master汇报自己的状态和进度,以此让App Master随时掌握各个task的运行状态,从而在task运行失败时重启任务;
8、当我们所有的map task、reduce task运行完了之后,向Applications Manager注销并且关闭自己。–> windwos上的状态就是finish和success的状态。
简述这个大的流程:
- 启动App Master:App Master申请资源,运行任务,直到任务运行完成
2.3、解析wordcount.java
1、拿到每一组的单词,为它赋上一个1
比如传入值a b c,==> (a,1) (b,1) (c,1)
传入值a c d, ==> (a,1) (c,1) (d,1)
2、Reduce进行举例:
(a,1)(b,1)
2.4、Map启动的Task个数由谁来决定?
- 参考J总博客:http://blog.itpub.net/30089851/viewspace-2095837/
在mapred-default.xml中,有两个参数决定了map数和task数:
| name | value | description |
|---|---|---|
| mapreduce.job.maps | 2 | The default number of map tasks per job. Ignored when mapreduce.framework.name is “local”. |
| mapreduce.job.reduces | 1 | The default number of reduce tasks per job. Typically set to 99% of the cluster’s reduce capacity, so that if a node fails the reduces can still be executed in a single wave. Ignored when mapreduce.framework.name is “local”. |
2、我们运行一遍wordcount词频统计:
1、命令如下:
oop@hadoop001 hadoop]$ hadoop jar /home/hadoop/app/hadoop-2.6.0-cdh5.16.2/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar wordcount /wordcount/input/wordcount.log /wordcount/output10
2、打印在控制台的内容如下:
Job Counters
Launched map tasks=1
Launched reduce tasks=1
//为什么只有一个task?
20/03/26 21:30:10 INFO input.FileInputFormat: Total input paths to process : 1
20/03/26 21:30:11 INFO mapreduce.JobSubmitter: number of splits:1
因为输入的路径下只有一个文件,所以map task只有一个;
3、我们测试:在这个hdfs目录下:/wordcount/input/wordcount1.log,多上传一个文件;再次进行词频统计,发现此时的map task是2;
Job Counters
Launched map tasks=2
Launched reduce tasks=1
map task:
1、log文件是86字节大小 1个块
map task 就是1份
===>
2、log 20字节 1个块
map task 就是2份
认为map task个数和文件的数量有关?这句话能达到80%准确率
===>
此时来了第三号文件:log 130m 2个块
map task是几份?
尽量在生产上控制一个文件的大小略微小于一个blocksize?
比如生产上规格是128M,文件差不多是120M
输入分片split是与map task挂钩的:
2.5、生产上考虑你的文件格式、压缩格式
- https://ruozedata.github.io/2018/04/18/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%8E%8B%E7%BC%A9%EF%BC%8C%E4%BD%A0%E4%BB%AC%E7%9C%9F%E7%9A%84%E4%BA%86%E8%A7%A3%E5%90%97%EF%BC%9F/
假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,
大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片
(input split),65mb则是两个输入分片(input split)
而127mb也是两个输入分片(input split),
换句话说我们如果在map计算前做输入分片调整,
例如合并小文件,那么就会有5个map任务将执行,
而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
???
应该在生产要考虑你的文件
是什么文件格式: txtfile orc parquet
压缩格式: gzip snappy lzo
生产上尽量选择支持分割压缩的格式:
- 对于Hive来说:orc/parquet存储文件格式,压缩格式:采用bzip2
- Hbase:hfile + snappy压缩
2.6、WordCount流程图解析(Shuffle)
Shuffle名词解析:洗牌
==> 把相同的牌洗给自己
面试题:Shuffle阶段是属于map阶段还是reduce阶段?
-
可以认为shuffle阶段是属于reduce阶段的,如下图map阶段的映射已经okay了;在做reduce聚合阶段之前,就相当于是把相同的key给搂到一起;
-
Shuffle阶段会伴随着学习和做大数据的在职生涯

笛卡尔积:
表一:null值 1kw
表二:null值 1w
那么最终的结果就是1kw x 1w,换言之,会存在一个节点撑爆了,全是(null,1);在这个节点就会慢的要死,存在夯住的状态,需要进行调优
三、作业
1、整理mapreduce on yarn的工作流程:
2、整理文件格式有哪些,它们的优缺点?
3、整理压缩格式有哪些,优缺点
- 时间换空间的事情,bzip2按照空间最优,但是时间花的是最多的;snappy虽然空间一般,但是时间是最快的。
4、输入分片和map task的关系?
5、wordcount的解剖图
6、Shuffle的理解 (洗牌)

















 5221
5221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









