




 本文详细介绍了Hadoop的HDFS架构,重点讨论了block块的大小、副本数、小文件问题,以及NameNode和DataNode的角色。NameNode管理文件系统的命名空间,DataNode存储数据块并定期发送心跳。此外,文章还探讨了小文件存储的挑战和解决方案,并讲解了SecondaryNameNode的检查点机制。最后,提到了文件损坏的校验方法。
本文详细介绍了Hadoop的HDFS架构,重点讨论了block块的大小、副本数、小文件问题,以及NameNode和DataNode的角色。NameNode管理文件系统的命名空间,DataNode存储数据块并定期发送心跳。此外,文章还探讨了小文件存储的挑战和解决方案,并讲解了SecondaryNameNode的检查点机制。最后,提到了文件损坏的校验方法。
- 2.1、block块
- 2.2、hdfs上的小文件
- 2.3、hdfs的架构设计
- 2.4、hdfs上的datanode
- 2.5、hdfs上关于数据修复
- 2.6、hdfs上的SecondaryNameNode
- 2.7、fsimage+editlog详解
- 2.8、校验文件是否损坏
一、上次课程回顾
- https://blog.youkuaiyun.com/SparkOnYarn/article/details/105085009
回顾上次课程:
1、伪分布式部署可以理解为集群的微缩版本
2、云主机为了防止挖矿,修改端口为38088
3、通过mapreduce的案例了解到,存储输出都是再hdfs,通过yarn来进行资源调度;
4、CentOS6、CentOS7下修改主机名;/etc/hosts下配置的是内网ip,在C盘的目录下配置的是外网IP
5、jps下的真真假假,使用ps -ef|grep监听到的才是真项
6、linux下的oom机制、定期clear机制;大数据项目运行周期会受到影响
二、Hadoop第三次课
2.1、block块
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
存在两个关于block的参数:
dfs.blocksize 128m
dfs.replication 3
通俗的举例:
存在260ml的水,瓶子的规格是128ml,问就是存几个瓶子?
260/128 = 2瓶 … 4ml
p1 128ml 装满
p2 128ml 装满
p3 4m 未装满,但是也占用一个瓶子
最终这些水要装3个瓶子。
–> 大数据中,blocksize -->瓶子的规格,在伪分布式部署中:dfs.replication = 1,因为我们只有一个datanode的节点,(千万不要在一台机器上不指三个datanode,以不同的端口号去启动),这种其实是不建议这么操作的;
- 解析下图:DN节点上存在P1,dfs.replication=3意味着的是包括本身一共3份,注意:副本数设置3 <= dn节点的数量,p1/p2/p3都是分布在不同的机器节点上的。260m的文件上传至hdfs上会进行切割为3份。
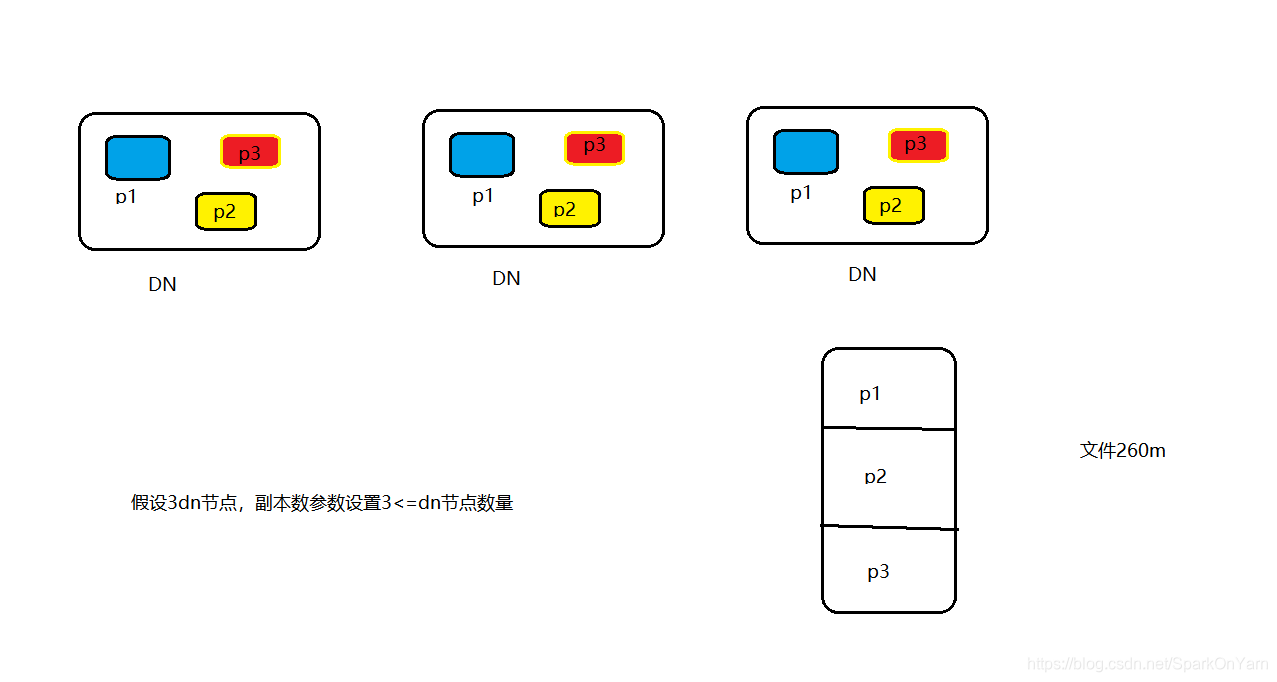
假设一个文件是260m,上传至hdfs上,切为3个块,dfs.replication=3
128m 128m 128m
128m 128m 128m
4m 4m 4m
存在如下面试题:
一个文件是160m,块大小是128m,副本数是2份
请问实际存储多少块,占据多少空间?
160/128=1…32m
答:实际存储4个块,占据320m空间
谨记两句话:1、数据上传hdfs不可能会凭空增加新的数据内容;2、dfs.blocksize是规格,未满一个规格,也会占用一个block文件
2.2、hdfs上的小文件
hdfs适合小文件存储吗?
假如不适合,为什么呢?
加入上传的文件都是小文件,比如上传的文件3 5 6 10m的四个文件
dfs.blocksize 128m 规格
dfs.replication 3
块的数量就是4个文件 x 3 = 12块
假设在【上传前合并】这四个文件为24m的文件,然后有3个副本,那存储的话就是占据3个块。
块的元数据信息是记录在我们的老大namenode上的,比如namenode的内存就只有4G,相比块越少,它的压力就越小;namenode管控文件分布在哪些机器,块的存储位置记录这些信息。
假如已经在hdfs上真的有小文件,该怎么办?
启动一个服务,单独进行合并。
目标是为了小文件合并为大文件,约定俗称的一点:合并后的大文件不要超过blocksize的大小,比如控制在110M的范围内,不要踩高压线,一个文件就是一个block块。比如129m的文件,进行切割还是会有一个1m的小文件。
所以hdfs的设计初衷是为了大文件的存储;J总公司怎样判断哪些小文件合并在一起?
- 编写shell脚本,筛选出所有小于10m的文件,设定阈值为10m
flume --> hdfs上如何控制小文件
查看hdfs上文件的字节:hdfs dfs -ls -h /wordcount/input
2.3、hdfs的架构设计
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
NN-DN的主从架构:
rack机架初识:就是一个柜子用来横着存放刀片机,企业存放的服务器是扁的;J总公司一个机架存放的是5个刀片机,每个刀片机的配置:256G内存(由32G x 8 = 256G内存)、56个物理core、4块各500g的ssd、10块各1T的机械硬盘1万转、2颗GPU(用作数据挖掘);价格:8.5W~10W;一个机架放5台刀片机;为啥只放5台,是因为一台机架的电的安培数是固定的,2颗CPU就等于是一台刀片机了;这当中的内存是可以进行升级的,后期J总公司升级到了512G.
- 下图解析:有两个机架,Rack1上存放了三台机器,Rack2上存放了两台机器;NameNode的角色是主:
存储: 文件系统的命名空间
a.文件的名称
b.文件的目录结构
c.文件的属性、权限、创建时间、副本数
d.文件对应被切割为哪些数据块(需要考虑到副本数,就是一个map的映射结构) --> 数据块分布在哪些DN节点上
p1 p1 p1
p2 p2 p2
p3 p3 p3
注意:一个DN节点上不可能存储一个块的多个副本,只能1个;
eg:DN1上已经存储了p1,不可能p1的副本还存储在DN1上;当然这是因为分布式存储的原因。
直观的去查看块的存储路径,如下:
[root@hadoop001 subdir0]# pwd
/tmp/hadoop-hadoop/dfs/data/current/BP-269313764-172.17.0.5-1585035736843/current/finalized/subdir0/subdir0
//落地到linux磁盘上面如下,一对一对的出现
[root@hadoop001 subdir0]# ll
total 212
-rw-rw-r-- 1 hadoop hadoop 35  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5215
5215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









