




HDFS存储架构
- 块block的大小默认是128M,hdfs-site.xml
<property> <name>dfs.blocksize</name> <value>134217728</value> </property> - 副本数默认是3,hdfs-site.xml
<property> <name>dfs.replication</name> <value>3</value> </property>
说明:当存储一个超过128M的文件,比如260M,会切分为3块:128M+128M+4M,每份存储3个副本即存储了780M的数据,如果当前节点含有DataNode进程,第一个副本会优先存在当前节点,否则就随机挑选一台磁盘不太慢的CPU不太繁忙的节点;第二个副本会存储在第一个副本不同的机架的节点上;第三个副本放置于第二个副本相同机架的不同节点上。
其中两份存在Rack2下的dn4和dn5两个节点,另一个存在Rack1下的dn1节点
3. HDFS是不适合做小文件存储的,因为小文件过多,会导致块block也就过多,而块的元数据信息存在namenode中,这样很容易导致namenode存储占满
4. 假如hdfs上已经存在小文件,需要尽量合并成大文件并且<=128M,比如控制在110M
HDFS进程介绍
- NameNode:主节点存储;1、文件系统的命名空间;2、文件的目录结构;3、文件的属性,权限,创建时间,副本数;4、文件对应被切割为哪些数据块,副本数,数据分布在哪些datanode节点上通过blockmap进行维护的,namenode不会持久化存储这些映射关系
- namenode是通过启动和运行时,datanode会定期发送blockreport给namenode,依次namenode在内存中动态维护这种映射关系
- namenode的作用:管理文件系统的命名空间,维护文件系统树的所有文件和文件夹,这些信息以两个文件形式永久保存在本地磁盘:镜像文件fsimage和编辑日志文件editlog
- datanode:存储数据库和数据库校验和,与namenode进行通信:1、每隔3s发送心跳包给namenode,去证明我还活着配置参数hdfs-site.xml:dfs.heartbeat.interval,默认大小3秒,2、每隔一定的时间发送一次blockreport,配置参数hdfs-site.xml:dfs.blockreport.intervalMsec,默认间隔时间21600000ms=6h,dfs.datanode.directoryscan.interval,默认间隔时间21600s=6h
- SecondaryNamenode,是为了解决单点故障的,存储fsimage和editlog;作用:定期合并fsimage 和editlog文件作为新的fsimage,推送给namenode,简称为检查点:checkpoint;
考虑到合并过程很耗费磁盘IO,网络IO,CPU,合并过程都放在secondarynamenode【SN】上进行
checkpoint的触发条件:
–满足dfs.namenode.checkpoint.preiod【默认1小时】时间点
–或者满足dfs.namenode.checkpoint.txns【默认100万次txns id】可以配置两个参数做checkpoint:hdfs-site.xml: dfs.namenode.checkpoint.period 3600s,设置为一小时,如果没有HA,也可以设置为1800s dfs.namenode.checkpoint.txns 1000000,如果操作达到100万次,没有达到一小时也会做checkpoint
但是没有满一小时比如40分钟,如果出现故障,这40分钟数据就会丢失
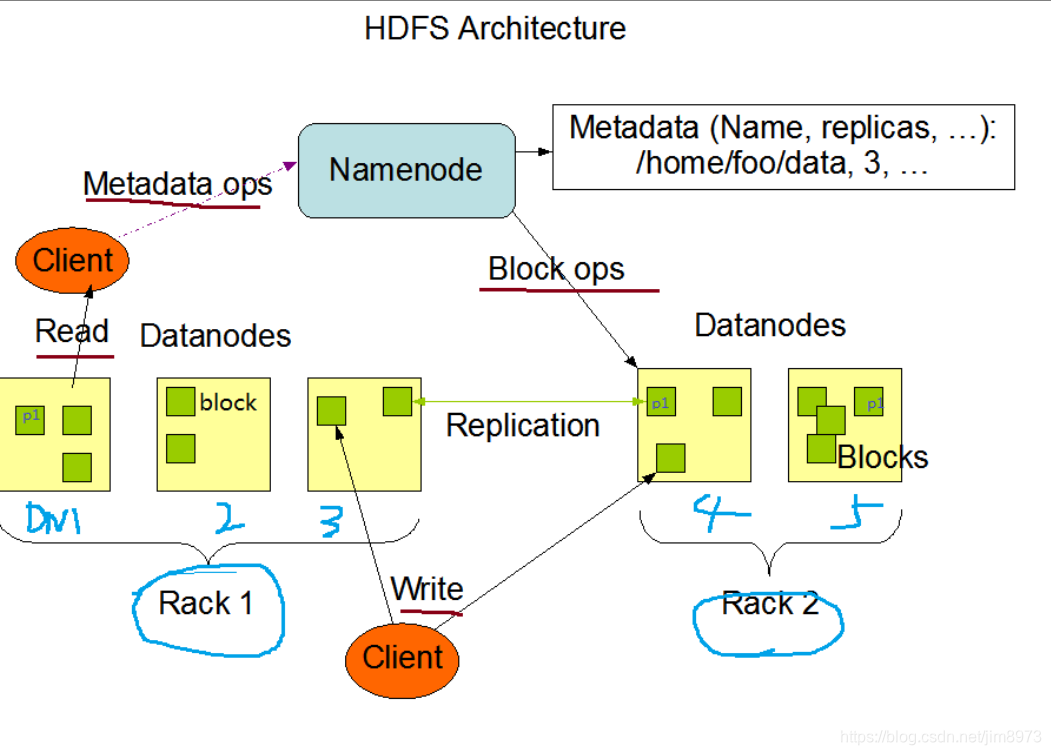
HDFS文件的写流程
- hdfs dfs -put xxx.log /,无感知的
- Client调用FileSystem.create(filePath)方法,与NN进行【RPC】通信,check是否存在及是否有权限创建;false,返回错误信息;true,就创建一个新文件,不关联任何的block块,返回一个FSDataOutputStream对象
- Client调用FSDataOutputStream对象的write()方法,现将第一块的第一个副本写到第一个DN,第一个副本写完;就传输给第二个DN,第二个副本写完;就传输给第三个DN,第三个副本写完。步骤如下
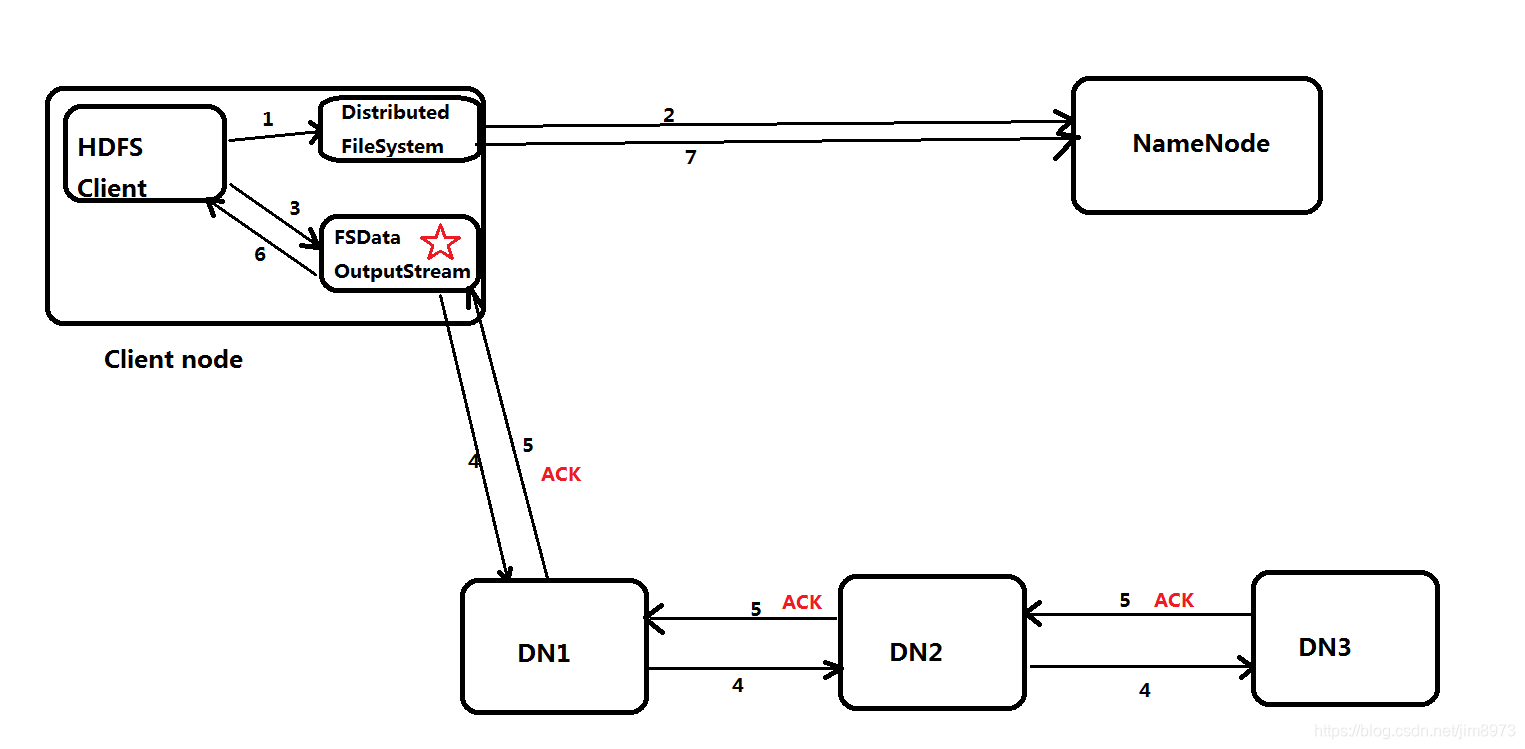
当第三个副本写完,就会返回ack packet确认包给第二个DN,第二个DN收到第三个DN的ack packet确认包加上自身的成功写入的信息,返回一个ack packet确认包给第一个DN,第一个DN收到第二个DN的ack packet确认包加上自身的成功写入的信息,就返回一个ack packet确认包给FSDataOutputStream对象,标志第一个块的三个副本写完。其他的块也是如此写入 - 当文件写入数据完成后,Client调用FSDataOutputStream.close()方法,关闭输出流。
- 再调用FileSystem.complete()方法,告诉NN该文件写入成功
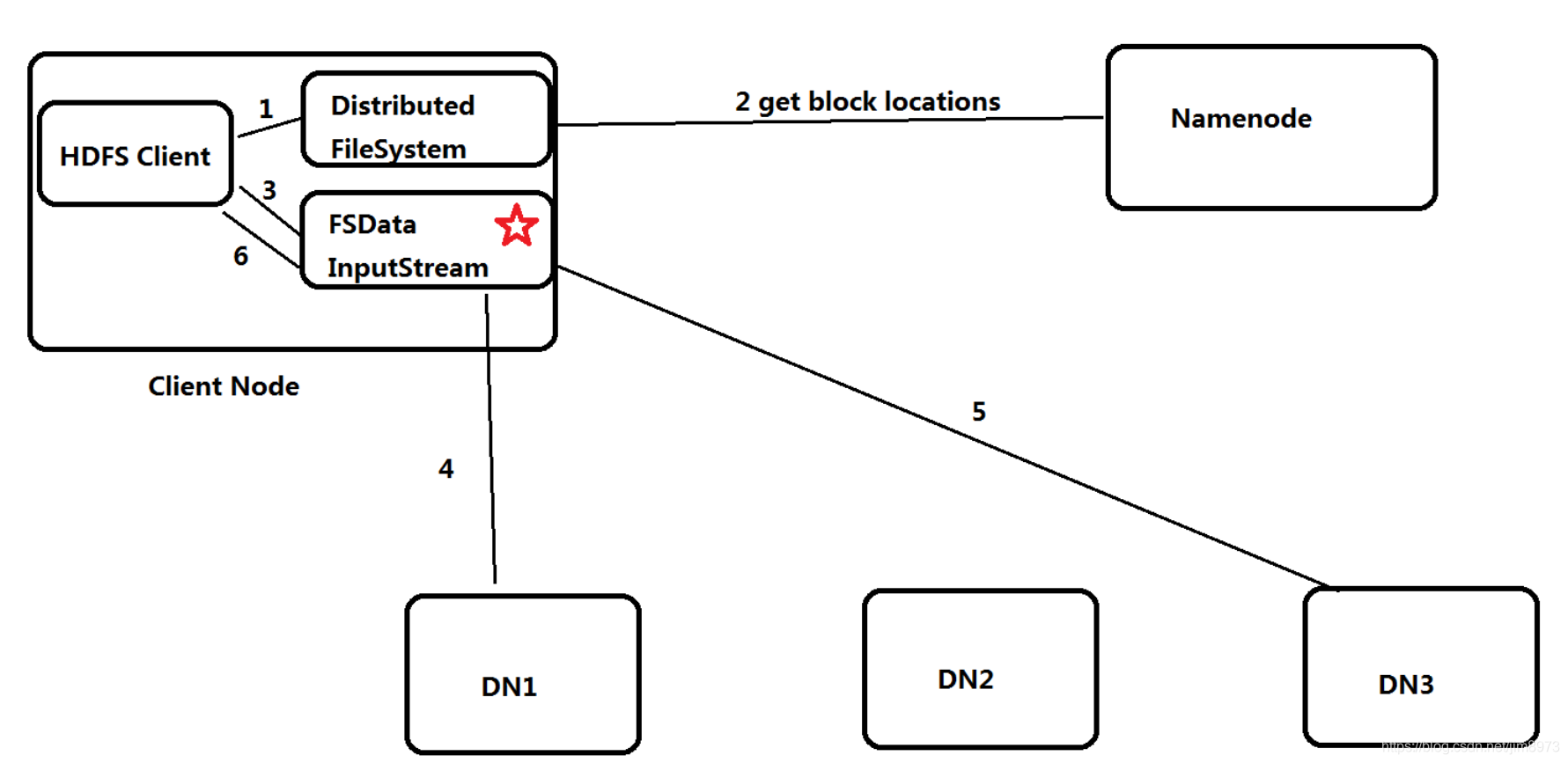
HDFS文件读取流程
- Client调用FileSystem.open(filePath)方法,与NN进行【RPC】通信,返回该文件的部分或者全部的block列表,也就是FSDataInputStream对象
- Client调用FSDataInputStream对象read()方法;
a:与第一个块最近的DN进行read,读取完成后,会check;true,就关闭与当前DN的通信;false,会记录失败的块和DN的信息,下次不会在读取,那么下次就会去该块的第二个DN地址读取
b:然后去第二个块的最近的DN上通信读取,check后,关闭通信
c:假如block列表读取完成后,文件还未结束,FileSystem会再次从NN获取该文件的下一批次的block列表。(感觉就是连续的数据流,对于客户端操作是透明无感知的) - Client调用FSDataInputStream.close()方法,关闭输入流
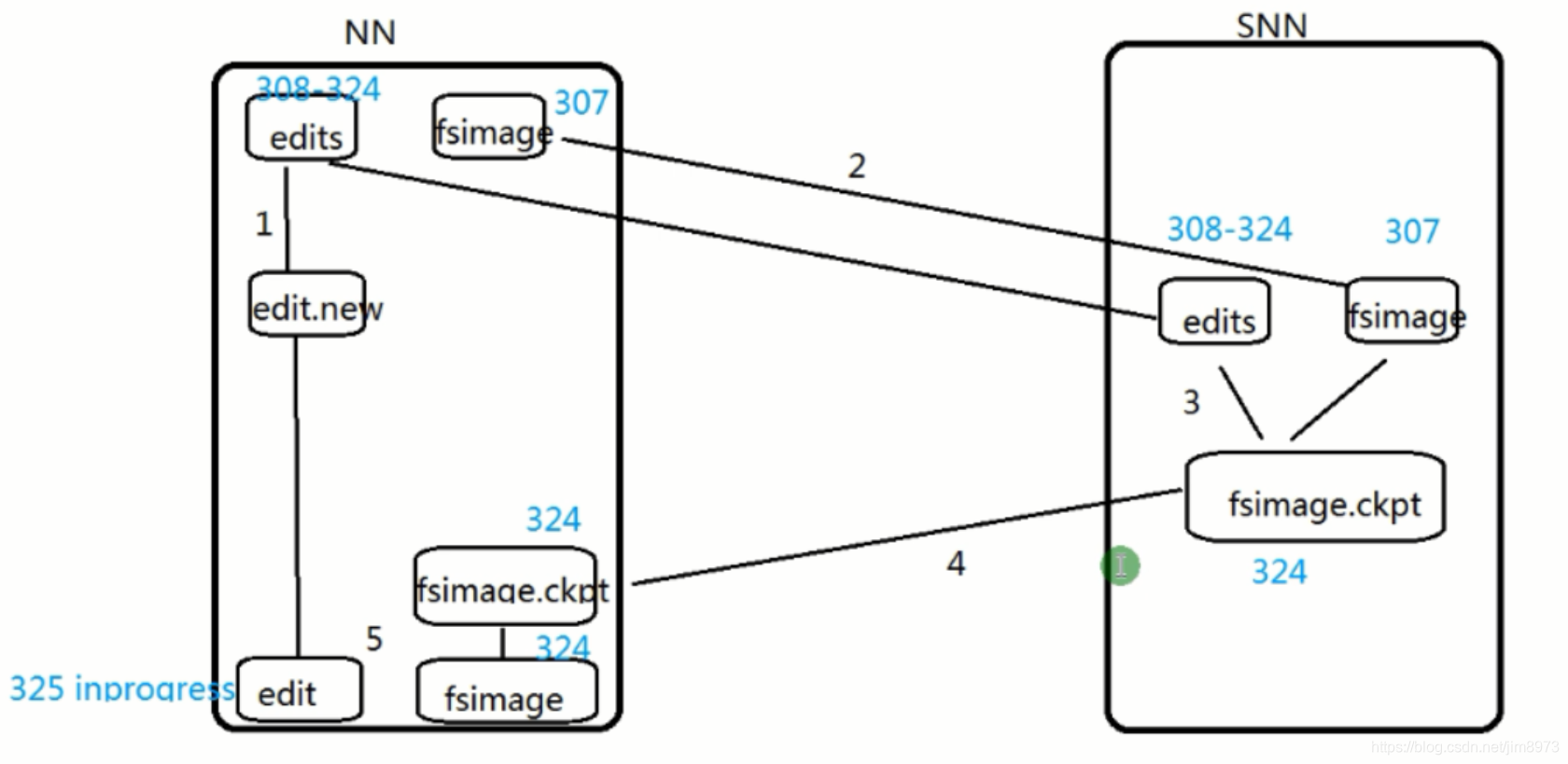
SN的checkpoint步骤
- NameNode滚动editLog:roll edits
- NameNode传输fsimage+edits到SN
- SN合并fsimage+edits=>fsimage.ckpt
- SN传输fsimage.ckpt到NameNode
- NameNode将fsimage.ckpt文件重命名fsimage,此完成了fsimage和editlog的同步,如图
hdfs debug
[hadoop@hadoop01 ~]$ hdfs debug
Usage: hdfs debug [arguments]
These commands are for advanced users only.
Incorrect usages may result in data loss. Use at your own risk.
verifyMeta -meta [-block ]
computeMeta -block -out
recoverLease -path
[hadoop@hadoop01 ~]$
手动修复: 多副本
[hadoop@hadoop01 current]$ hdfs debug recoverLease -path xxx -retries 10
自动修复:
参考:
https://ruozedata.github.io/2019/06/06/%E7%94%9F%E4%BA%A7HDFS%20Block%E6%8D%9F%E5%9D%8F%E6%81%A2%E5%A4%8D%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5(%E5%90%AB%E6%80%9D%E8%80%83%E9%A2%98)/
文件fei.md
上传
-bash-4.2$ hdfs dfs -mkdir /blockrecover
-bash-4.2$ echo “www.baidu.com” > fei.md
-bash-4.2$ hdfs dfs -put fei.md /blockrecover
-bash-4.2$ hdfs dfs -ls /blockrecover
Found 1 items
-rw-r–r-- 3 hdfs supergroup 18 2019-03-03 14:42 /blockrecover/fei.md
-bash-4.2$
校验: 健康状态
-bash-4.2$ hdfs fsck /
Connecting to namenode via http://yws76:50070/fsck?ugi=hdfs&path=%2F
FSCK started by hdfs (auth:SIMPLE) from /192.168.0.76 for path / at Sun Mar 03 14:44:44 CST 2019
…Status: HEALTHY
Total size: 50194618424 B
Total dirs: 354
Total files: 1079
Total symlinks: 0
Total blocks (validated): 992 (avg. block size 50599413 B)
Minimally replicated blocks: 992 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Sun Mar 03 14:44:45 CST 2019 in 76 milliseconds
The filesystem under path ‘/’ is HEALTHY
-bash-4.2$
直接DN节点上删除文件一个block的一个副本(3副本)
删除块和meta文件:
[root@yws87 subdir135]# rm -rf blk_1075808214 blk_1075808214_2068515.meta
直接重启HDFS,直接模拟损坏效果,然后fsck检查:
-bash-4.2$ hdfs fsck /
Connecting to namenode via http://yws77:50070/fsck?ugi=hdfs&path=%2F
FSCK started by hdfs (auth:SIMPLE) from /192.168.0.76 for path / at Sun Mar 03 16:02:04 CST 2019
.
/blockrecover/fei.md: Under replicated BP-1513979236-192.168.0.76-1514982530341:blk_1075808214_2068515. Target Replicas is 3 but found 2 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
…Status: HEALTHY
Total size: 50194618424 B
Total dirs: 354
Total files: 1079
Total symlinks: 0
Total blocks (validated): 992 (avg. block size 50599413 B)
Minimally replicated blocks: 992 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (0.10080645 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.998992
Corrupt blocks: 0
Missing replicas: 1 (0.033602152 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Sun Mar 03 16:02:04 CST 2019 in 148 milliseconds
The filesystem under path ‘/’ is HEALTHY
-bash-4.2$
手动修复hdfs debug
-bash-4.2$ hdfs |grep debug
没有输出debug参数的任何信息结果!
故hdfs命令帮助是没有debug的,但是确实有hdfs debug这个组合命令,切记。
修复命令:
-bash-4.2$ hdfs debug recoverLease -path /blockrecover/fei.md -retries 10
recoverLease SUCCEEDED on /blockrecover/fei.md
-bash-4.2$
直接DN节点查看,block文件和meta文件恢复:
[root@yws87 subdir135]# ll
total 8
-rw-r–r-- 1 hdfs hdfs 56 Mar 3 14:28 blk_1075808202
-rw-r–r-- 1 hdfs hdfs 11 Mar 3 14:28 blk_1075808202_2068503.meta
[root@yws87 subdir135]# ll
total 24
-rw-r–r-- 1 hdfs hdfs 56 Mar 3 14:28 blk_1075808202
-rw-r–r-- 1 hdfs hdfs 11 Mar 3 14:28 blk_1075808202_2068503.meta
-rw-r–r-- 1 hdfs hdfs 18 Mar 3 15:23 blk_1075808214
-rw-r–r-- 1 hdfs hdfs 11 Mar 3 15:23 blk_1075808214_2068515.meta
自动修复
当数据块损坏后,DN节点执行directoryscan操作之前,都不会发现损坏;
也就是directoryscan操作是间隔6h
dfs.datanode.directoryscan.interval : 21600
在DN向NN进行blockreport前,都不会恢复数据块;
也就是blockreport操作是间隔6h
dfs.blockreport.intervalMsec : 21600000
当NN收到blockreport才会进行恢复操作。
但是有可能: 手动修复 加上自动修复都是失败的
所以数据仓库要注意数据质量和数据重刷机制
DataNode Memory
datanode一般要落地磁盘,所以内存不用太大,2G足够,默认是4G
https://issues.apache.org/jira/secure/Dashboard.jspa
设置为8G只用了600M,下面的error的原因
java.lang.OutOfMemoryError: unable to create new native thread
实际是下面的配置导致的
1.echo “kernel.threads-max=196605” >> /etc/sysctl.conf
echo “kernel.pid_max=196605” >> /etc/sysctl.conf
echo “vm.max_map_count=393210” >> /etc/sysctl.conf
sysctl -p
2./etc/security/limits.conf
- soft nofile 196605
- hard nofile 196605
- soft nproc 196605
- hard nproc 196605
hdfs生产环境注意事项
- 检查生产环境是否开启回收站,CDH默认是开启的,在配置文件core-site.xml中配置fs.trash.interval 10080 (7天)
- 开启了回收站,慎用-skipTrash,比如 hdfs dfs -rm -skipTrash /fei.log,而是使用hdfs dfs -rm /fei.log,这样删除的文件就会放在回收站,7天后自动删除
- hdfs安全模式:只对写有影响,进入安全模式,hdfs dfsadmin -safemode enter;离开安全模式hdfs dfsadmin -safemode leave;安全模式尽量少做,如果hdfs集群故障,一般控制上游的数据同步
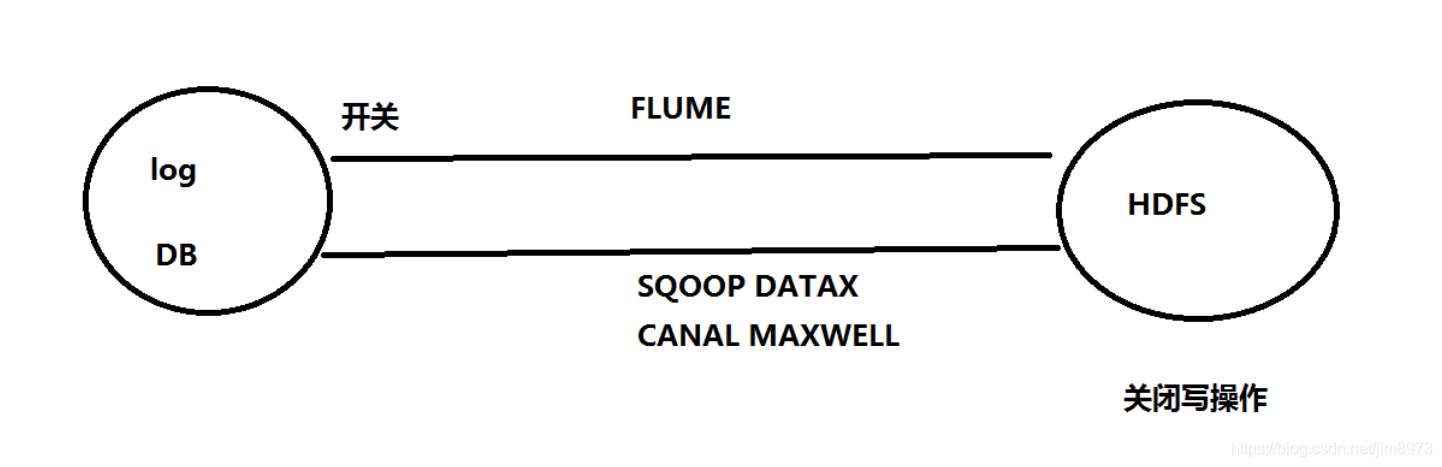
如果HDFS出现故障,一般控制FLUME采集数据这块,等集群恢复,才继续同步数据 - hdfs fsck :用于检查HDFS上文件和目录的健康状态、获取文件的block块信息和位置信息等
具体命令介绍:[hadoop@hadoop01 hadoop]$ hdfs fsck / 21/11/07 10:03:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Connecting to namenode via http://hadoop01:50070/fsck?ugi=hadoop&path=%2F FSCK started by hadoop (auth:SIMPLE) from /172.17.0.5 for path / at Sun Nov 07 10:03:34 CST 2021 ......Status: HEALTHY Total size: 175049 B Total dirs: 12 Total files: 6 Total symlinks: 0 Total blocks (validated): 5 (avg. block size 35009 B) Minimally replicated blocks: 5 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 1 Average block replication: 1.0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Number of data-nodes: 1 Number of racks: 1 FSCK ended at Sun Nov 07 10:03:34 CST 2021 in 5 milliseconds The filesystem under path '/' is HEALTHY
-move: 移动损坏的文件到/lost+found目录下
-delete: 删除损坏的文件
-openforwrite: 输出检测中的正在被写的文件
-list-corruptfileblocks: 输出损坏的块及其所属的文件
-files: 输出正在被检测的文件
-blocks: 输出block的详细报告 (需要和-files参数一起使用)
-locations: 输出block的位置信息 (需要和-files参数一起使用)
-racks: 输出文件块位置所在的机架信息(需要和-files参数一起使用)
例如要查看HDFS中某个文件的block块的具体分布,可以这样写:
hadoop fsck /your_file_path -files -blocks -locations -racks
各个DN节点的数据平衡
- start-balancer.sh -threshold 10,threadhold表示所有节点的磁盘使用的与集群平均使用之差要小于这个阈值
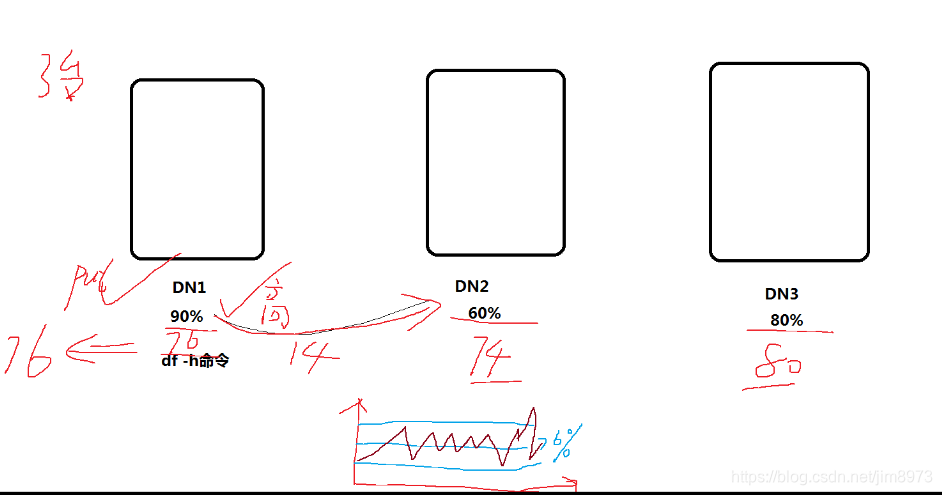
平均值(90%+60%+80%)/3=76%,所以需要把DN1数据均衡到DN2,保证每个节点已经使用的磁盘空间和平均值都相差在10%范围内
其中hdfs-site.xml中dfs.datanode.balance.bandwidthPerSec 控制均衡数据的每秒的大小,正常设置为30m,即30m每秒 - stop-balancer.sh,如果各个节点数据平衡夯住,就可以使用该命令
- 数据平衡一般晚上做调度
单个DN节点的多磁盘数据平衡
需要现在hdfs-site.xml
配置dfs.disk.balancer.enabled,启用多磁盘数据平衡;dfs.datanode.data.dir:/data01,/data02,/data03,/data04,多个磁盘用逗号分隔
具体参考:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSDiskbalancer.html
操作命令步骤:
hdfs diskbalancer -plan hadoop01 生成hadoop01.plan.json
hdfs diskbalancer -execute hadoop01.plan.json 执行
hdfs diskbalancer -query hadoop01 查询状态
执行磁盘数据均衡的时机是:新盘加入;监控服务器的磁盘剩余空间,小于阈值比如10%,发送邮件预警,手动执行
为什么DN节点的生产上挂载多个物理的磁盘目录?
/data01 disk1
/data02 disk2
/data03 disk3
为了高效率写,高效率读,并行读写
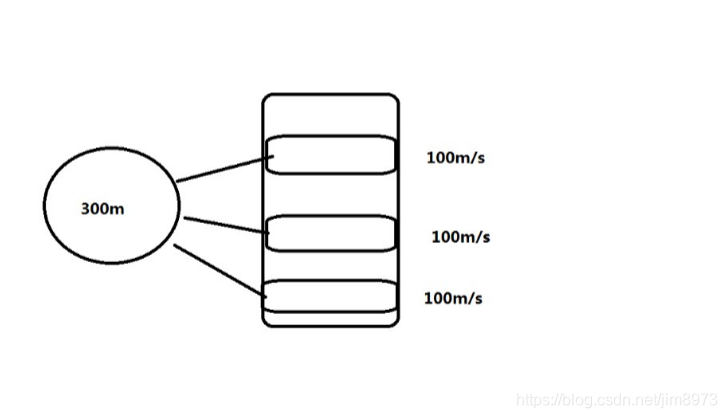
提前规划好2-3年存储量 ,避免后期加磁盘维护的工作量


















 1395
1395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









