




一、引 言
LSM-Tree(Log-Structured Merge Tree)是一种高效的键值存储数据结构,广泛应用于NoSQL数据库和大数据处理系统中。其核心思想是通过分层、有序地利用磁盘顺序写入的性能优势,优化写入操作,同时牺牲部分读取性能以换取更高的写入吞吐量。

在互联网的各个基础设施中,不论是数据库还是缓存亦或是大数据框架,LSM-Tree这个数据结构都是很常见的身影。
我每天都在使用这个存储引擎,但是对它的了解还流于表面,所以我想要自己实现一次LSM-Tree加深理解。
本次实现我们采用了Zig语言,简要的实现LSM-Tree的核心功能(读写、数据压缩、持久化,不包含MVCC的内容)。
Zig是一种新兴的系统编程语言,其设计目标是提供现代特性的同时保持低复杂性。
本项目极大的受到了Mini-Lsm这个项目的启发,强烈推荐大家学习这个项目!
二、LSM-Treee 核心功能概述
在开始自己编写之前,我先简单介绍一下LSM-Tree(Log-Structured Merge Tree)的架构以及读写流程。
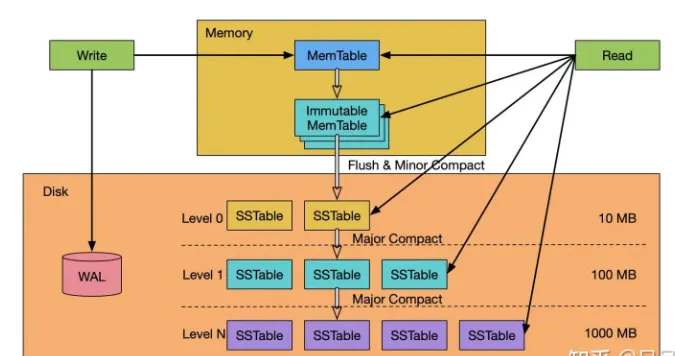
LSM-Tree它结合了日志和索引的特点,优化了写入和读取性能。每次写入都是采用append-only的方式,所以写入性能很高。
而作为代价,追加写入会造成存储放大,LSM-Tree时采用了多层SSTable的方式将数据堆叠在硬盘上。所以需要一个合并压缩的过程来回收过多的空间。
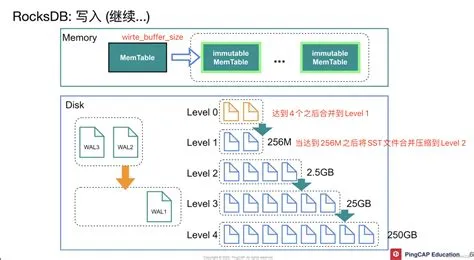
写流程
- 预写日志(WAL) :写操作首先写入预写日志(WAL),用于记录未提交的数据,确保数据的持久性和一致性。
- MemTable:随后将数据写入内存中的MemTable,MemTable是一个平衡树(如skiplist),支持快速插入和删除操作。
- 触发Compaction:当MemTable达到一定阈值时,会触发后台线程将MemTable中的数据刷入磁盘,生成SSTable文件。
- SSTable:生成的SSTable文件是不可变的,存储在磁盘上,用于后续读取操作。
- 合并操作(Merge) :当多个SSTable文件达到一定数量时,会触发合并操作,将它们合并为一个更大的SSTable文件,以减少文件数量。
读流程
- MemTable优先:读取操作首先从MemTable中查找数据,因为MemTable是按升序排列的,查找效率较高。
- Block Cache:如果MemTable中未找到数据,则从Block Cache中查找。Block Cache存储了预先加载到内存中的SSTable块,以提高读取性能。
- SSTable查找:如果Block Cache中也未找到数据,则从磁盘上的SSTable文件中查找。Lsm-tree会从最低层(L0)开始查找,逐层向上查找,直到找到目标数据。
- 多版本并发控制(MVCC) :Lsm-tree支持多版本并发控制,允许同时访问不同版本的数据,从而提高并发性能。
三、核心功能实现
MemTable 实现
首先,我们先实现 LSM 存储引擎的内存结构—Memtable。我们选择跳表实现作为 Memtable 的数据结构,因为它支持无锁的并发读写。我们不会深入介绍跳表的工作原理(Redis的同学应该不陌生这个东西),简单来说,它是一个易于实现的有序键值映射。

Skiplist的实现非常简单,这里我利用Zig编译时的能力实现了一个泛型版本的跳表src/skiplist.zig,有兴趣的小伙伴可以直接去仓库中参观代码。
基于SkipList的能力,我们即可包装出Memtable的基本功能。
我们这个LSM支持WAL功能的,即写入内存表之前要先写入磁盘日志,方便在意外宕机重启后可以恢复数据。
WAL的能力我就不想自己再实现了,于是从网上扒了一个C的实现(Zig集成C语言非常便捷,可以参考与 C 交互)。
map: Map,
lock: RwLock,
wal: ?Wal,
id: usize,
allocator: std.mem.Allocator,
arena: std.heap.ArenaAllocator,
approximate_size: atomic.Value(usize) = atomic.Value(usize).init(0),
fn putToList(self: *Self, key: []const u8, value: []const u8) !void {
{
self.lock.lock();
defer self.lock.unlock();
try self.map.insert(kk, vv);
}
_ = self.approximate_size.fetchAdd(@intCast(key.len + value.len), .monotonic);
}
fn putToWal(self: *Self, key: []const u8, value: []const u8) !void {
// [key-size: 4bytes][key][value-size: 4bytes][value]
if (self.wal) |w| {
var buf = std.ArrayList(u8).init(self.arena.allocator());
var bw = buf.writer();
try bw.writeInt(u32, @intCast(key.len), .big);
_ = try bw.write(key);
try bw.writeInt(u32, @intCast(value.len), .big);
_ = try bw.write(value);
try w.append(buf.items);
}
}
// 写入Memtable,先写WAL,再写skiplist table
pub fn put(self: *Self, key: []const u8, value: []const u8) !void {
try self.putToWal(key, value);
try self.putToList(key, value);
}
pub fn get(self: *Self, key: []const u8, val: *[]const u8) !bool {
self.lock.lockShared();
defer self.lock.unlockShared();
var vv: []const u8 = undefined;
if (try self.map.get(key, &vv)) {
val.* = vv;
return true;
}
return false;
}
注意到这里我们没有实现删除的功能,这里我仿照了RocksDB中的墓碑机制,用空值代表删除,所以删除被put(key, “”)取代。
SSTable
接下来,我们就着手开始实现LSM中另外一个重要元素 — SSTable。
SSTable(Sorted String Table)是一种不可变的(Immutable)磁盘文件,内部按Key有序排列,存储键值对数据。每个SSTable文件生成后不再修改,更新和删除操作通过追加新记录或标记删除,最终通过合并(Compaction)清理冗余数据。
每当LSM-Tree中的MemTable体积超出阈值,就会将内存中的数据写入SsTable。
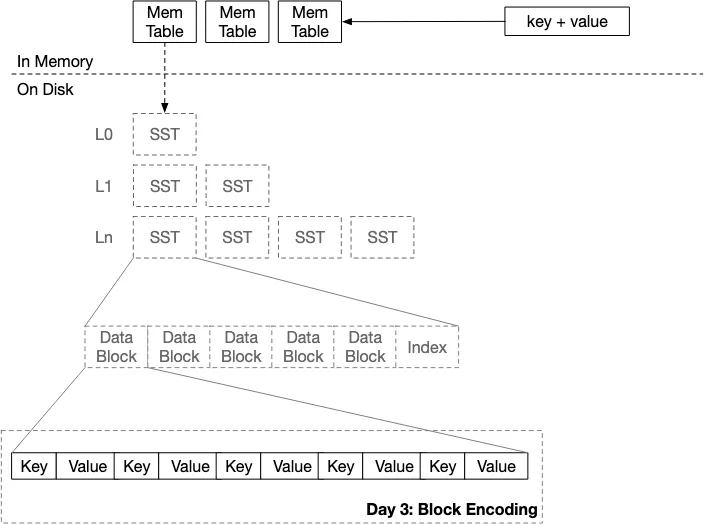
每个SSTable由多个Block组成,每个Block是一组KV的package。
Block的编码格式如下:
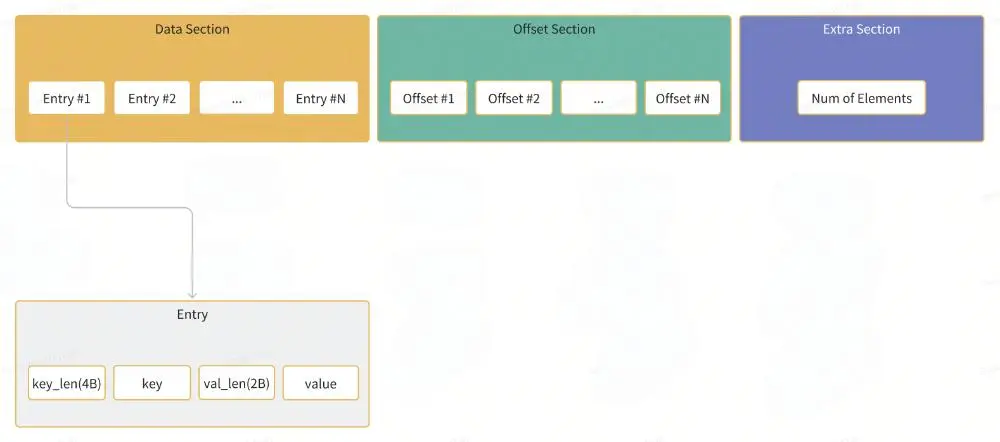
为了构建一个Block,我们实现了一个BlockBuilder的模块,这部分代码见src/block.zig:
pub const Block = struct {
data_v: std.ArrayList(u8),
offset_v: std.ArrayList(u16),
}
pub const BlockBuilder = struct {
allocator: std.mem.Allocator,
offset_v: std.ArrayList(u16),
data_v: std.ArrayList(u8),
block_size: usize,
first_key: []u8,
pub fn add(self: *Self, key: []const u8, value: ?[]const u8) !bool {
std.debug.assert(key.len > 0); // key must not be empty
const vSize = if (value) |v| v.len else 0;
if ((self.estimated_size() + key.len + vSize + 3 * @sizeOf(u16) > self.block_size) and !self.is_empty()) {
return false;
}
try self.doAdd(key, value);
if (self.first_key.len == 0) {
self.first_key = try self.allocator.dupe(u8, key);
}
return true;
}
fn doAdd(self: *Self, key: []const u8, value: ?[]const u8) !void {
// add the offset of the data into the offset array
try self.offset_v.append(@intCast(self.data_v.items.len));
const overlap = calculate_overlap(self.first_key, key);
var dw = self.data_v.writer();
// encode key overlap
try dw.writeInt(u16, @intCast(overlap), .big);
// encode key length
try dw.writeInt(u16, @intCast(key.len - overlap), .big);
// encode key content
_ = try dw.write(key[overlap..]);
// encode value length
if (value) |v| {
try dw.writeInt(u16, @intCast(v.len), .big);
// encode value content
_ = try dw.write(v);
} else {
try dw.writeInt(u16, 0, .big);
}
}
pub fn build(self: *Self) !Block {
if (self.isEmpty()) {
@panic("block is empty");
}
return Block.init(
try self.data_v.clone(),
try self.offset_v.clone(),
);
}
}
可能有同学注意到,我们写key的时候没有直接将key值写入,而且只写了key与当前block的第一个key不重叠的suffix部分。由于block中的key都是有序的,所以一个block中的key有很大概率是前缀类似的,所以这里是一个空间优化的小技巧,例如:
Key: foo, foo1, foo2, foo3 …
我们写入block时,只需要写:
foo|1|2|3|…
很多有序表的实现中都会用到这个小技巧。
有了block的实现,我们可以进一步来定义SSTable的格式。一个SSTable由多个Block、block元数据以及布隆过滤器构成。
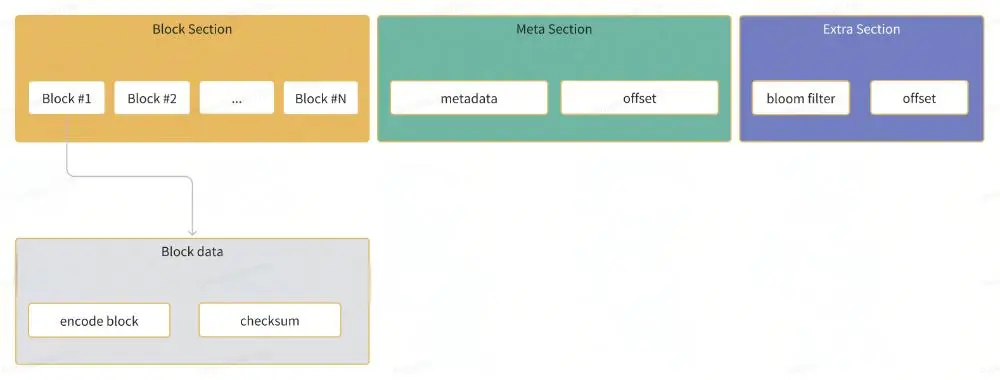
布隆过滤器是一种概率性数据结构,用于维护一组键。您可以向布隆过滤器中添加键,并且可以知道在添加到布隆过滤器中的键集中可能存在或必须不存在的键。
在SSTable中添加布隆过滤器可以有效提升查询key的效率。
元数据包含了block的第一个与最后一个key以及block在sst中的offset信息,记录元数据主要为了在后续的检索中可以快速定位某个key落在哪个block中。
同样的套路,为了构建SSTable,我们先实现一个SSTableBuilder,部分代码见src/ss_table.zig
pub const SsTableBuilder = struct {
allocator: std.mem.Allocator,
builder: BlockBuilder, // 刚才实现的block构建装置
first_key: ?[]const u8,
last_key: ?[]const u8,
meta: std.ArrayList(BlockMeta),
block_size: usize,
data: std.ArrayList(u8),
bloom: BloomFilterPtr, // 布隆过滤器
pub fn add(self: *Self, key: []const u8, value: []const u8) !void {
try self.setFirstKey(key);
try self.bloom.get().insert(key); // 写入布隆过滤器
if (try self.builder.add(key, value)) {
try self.setLastKey(key);
return;
}
// block is full
try self.finishBlock();
std.debug.assert(try self.builder.add(key, value));
try self.resetFirstKey(key);
try self.setLastKey(key);
}
// 写入一个block的数据
fn finishBlock(self: *Self) !void {
if (self.builder.isEmpty()) {
return;
}
var bo = self.builder;
// reset block
defer bo.reset();
self.builder = BlockBuilder.init(self.allocator, self.block_size);
var blk = try bo.build();
defer blk.deinit();
const encoded_block = try blk.encode(self.allocator); // block序列化
defer self.allocator.free(encoded_block);
// 记录block的元数据
try self.meta.append(.{
.allocator = self.allocator,
.offset = self.data.items.len,
.first_key = try self.allocator.dupe(u8, self.first_key.?),
.last_key = try self.allocator.dupe(u8, self.last_key.?),
});
const cksm = hash.Crc32.hash(encoded_block); // 写入4b的校验值
try self.data.appendSlice(encoded_block);
try self.data.writer().writeInt(u32, cksm, .big);
}
// 构建为一个SSTable
pub fn build(
self: *Self,
id: usize,
block_cache: ?BlockCachePtr, // 读取block数据的缓存,减少block的反序列化成本
path: []const u8,
) !SsTable {
var arena = std.heap.ArenaAllocator. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









