




一、前言
众所周知,英伟达(Nvidia)自2006年推出CUDA以来,经过近20年的发展,尤其是经历了以卷积为代表的深度学习和近两年以Transformer为基础的LLM的推动,CUDA编程基本上成为了GPU编程的代名词。CUDA作为GPU的编程语言,不仅使用户能充分发挥Nvidia GPU的高性能的并行计算能力,也逐渐构筑了一个包括硬件、驱动、开发库和编程技巧的完备生态链,从而使CUDA成为了人工智能、高性能计算和云计算中的核心依赖。

(图片来源:Triton-lang documentation )
Triton是OpenAI 推出的以python为编程语言基础,专门为深度学习研发和高性能计算而设计的编程语言和编译器,旨在简化和优化GPU编程的复杂操作,降低高性能优化的门槛。
在大模型推理优化领域,已有很多优秀的工作开始应用Triton编写高效算子,例如近期被众多大模型推理框架集成的Attention算子FlashAttention、推理加速框架lightllm、训练加速框架的Unsloth等。
Triton的初期版本以CUDA为起点而开发,为没有CUDA基础的编程者提供快速编写高效CUDA kernel的方案,而随着迭代已逐渐支持其他芯片和编程工具,如AMD的ROCm,并在继续支持其他的芯片,如Intel的CPU。因而,除了简化高性能计算,同时Triton也在试图构建一个“CUDA-free”的更高层的kernel编写方案,打破“天下苦CUDA久矣”的局面,把复杂的对底层芯片的交互,交给其IR和底层的编译器。
综上,可以说Triton是起于CUDA,又不止于CUDA。几个词可以简单总结Triton的特点和发展方向:
- 门槛低
- 高效
- 多平台
二、GPU基础
在学习Triton的编程设计前,还是需要了解GPU一些简单的基础架构知识和GPU编程的基础概念。
以下左图是引自NVIDIA经典Ampere架构的GA100(A100)的datasheet的整体架构示意图,展现其所有128个SMs(Streaming Multiprocessors)和各级缓存、HBM(高性能内存)和NvLink(Nvidia卡间互联)等;而右图是A100的单个SM(Streaming MultiProcessor, 多核流处理器) 的结构。

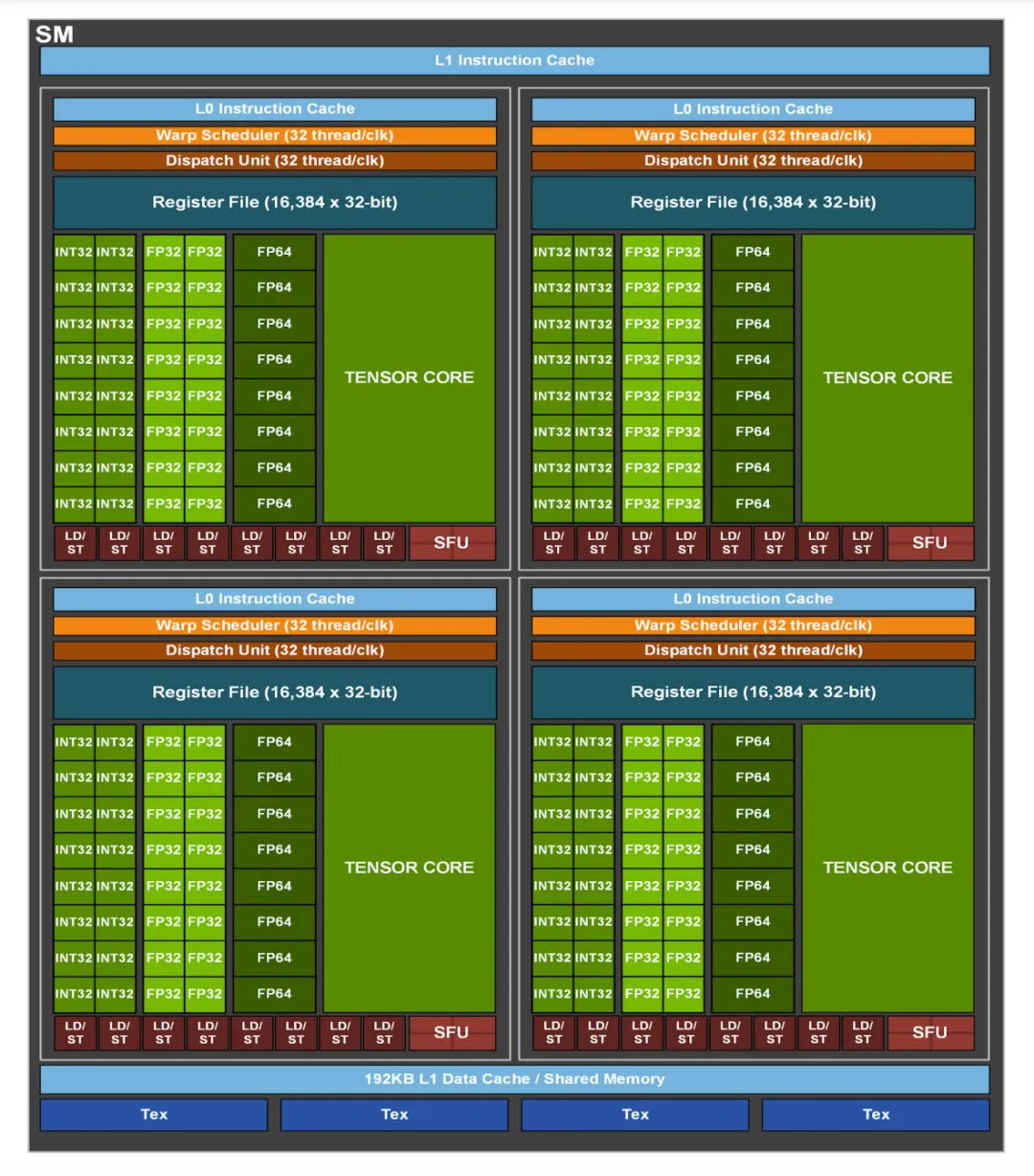
(图片来源:Nvidia-ampere-architecture-whitepaper )
从硬件的角度来讲,
- SP (Streaming Processor 线程处理器) 是CUDA 编程模型的最基本单位。每个SP都有自己的registers (寄存器) 和 local memory (局部内存, L0 cache)。寄存器和局部内存只能被自己访问,不同的线程处理器之间彼此独立。
- 由多个线程处理器 (SP) 和一块共享内存(shared memory, L1 cache)构成了一个SM。多核处理器里边的多个SP互相并行,且互不影响。每个SM内都有自己的共享内存,shared memory 可以被线程块内所有线程访问。
从软件的角度来讲,
- thread(线程):一个CUDA程序被分成多个threads执行。
- block 或 thread block (线程块):多个threads群组成一个block,同一个block中的threads可以同步,也可以通过shared memory 传递数据。
- grid(网格):多个blocks会再构成grid。
- warp:GPU执行程序时的调度单位。
对应关系:
- 一个SP可以执行一个thread。
- CUDA的device在执行任务时,会把任务分成一个个的block分配给SM执行, 而每个block又会以warp为单位执行(Nvidia把32个threads组成一个warp, warp即是SM调度和运行的基本单元,所有SP执行同一指令,但每个thread使用各自的data)。
- 一个warp需要占用一个SM,多个warps则会轮流进入SM处理。
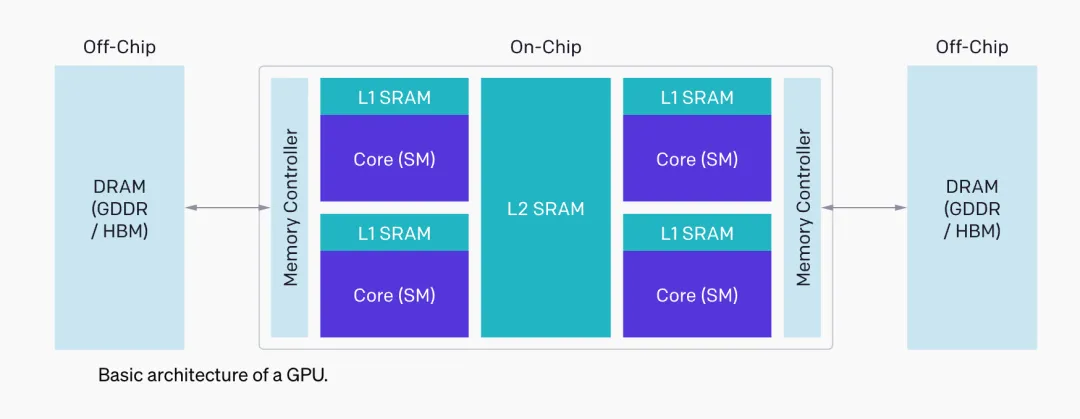
(图片来源:OpenAI official introduction )
将上述结构大致抽象成3个组成部分DRAM, SRAM和ALU, 其中DRAM即各个HBMs(即俗称的显存),SRAM指各级缓存,ALU即计算单元(GPU中的SM),而当用户优化CUDA代码时需要考虑:
- DRAM读写时的内存合并:以保证充分利用GPU的内存带宽;
- 数据必须手动分配至各级SRAM:以尽可能地避免共享内存冲突;
- 计算流程必须在SM内部和外部谨慎合理地设计、分配和调度:以促进并行线程的计算效率。
而在编程设计时充分考虑以上,即使是对于富有经验的CUDA编程者也颇具挑战,因而Triton希望底层编译器对多数的调度细节能自动优化,而用户只需要考虑一些顶层的逻辑设计,即SMs层级的,例如矩阵分片,SM之间数据同步等问题。
其官网介绍给出了一个对比,
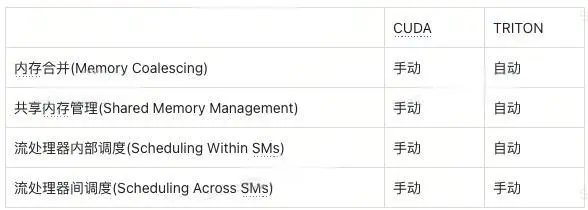
(表格来源:OpenAI official introduction)
通俗而言,相比于CUDA,使用Triton,你不必控制所有内容,因为有些事情可以留给工具自动优化;用Triton编写的模块可能不一定优于顶级的CUDA算子,但是性能通常能优于普通的CUDA kernel;而前者的门槛大大低于后者。
因而Triton的编程设计过程,其关键在于SM层级的并行处理过程的设计,即画好SM层级的网格图以表示算子的计算过程。
三、Triton 编程实例
向量求和
内核函数
向量求和对于Triton是一个"Hello World"式的示例。使用Pytorch,对于两个同长度的vector,直接相加,非常简单。
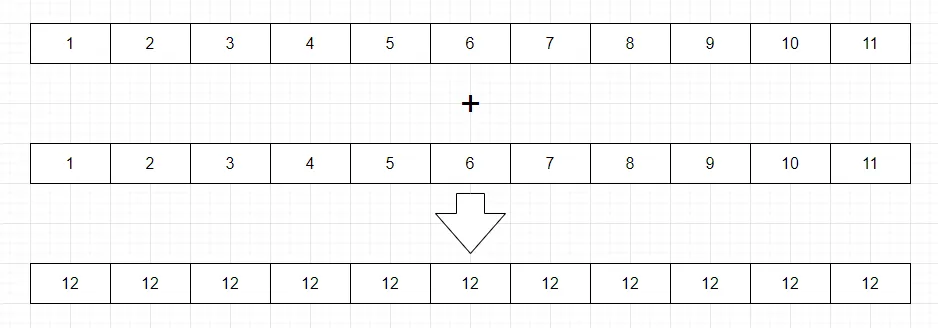
size = 1024
x = torch.rand(size, device='cuda')
y = torch.rand(size, device='cuda')
output_torch = x + y
而对于Triton,需要编写一个内核函数(kernel)和一个调用函数(wrapper),调用时的并行网格图如下:
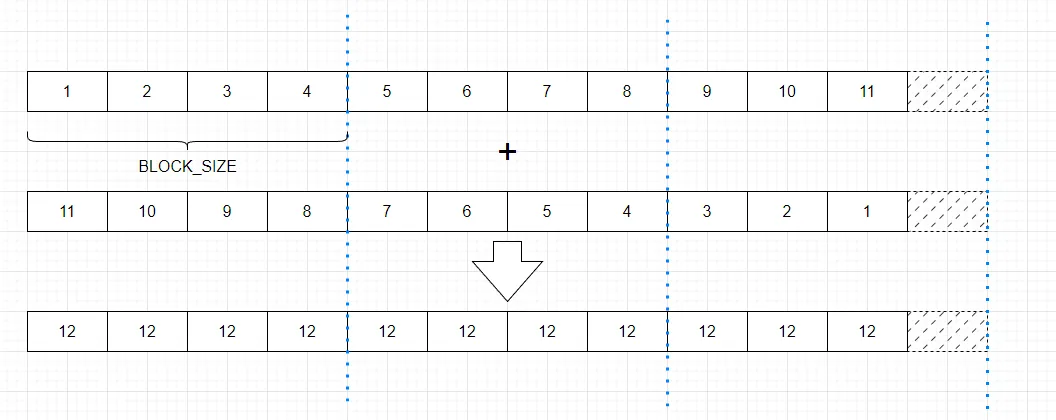
kernel 函数代码如下:
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, # 第一个输入向量的指针
y_ptr, # 第二个输入向量的指针
output_ptr, # 输出向量的指针
n_elements, # 向量长度
BLOCK_SIZE: tl.constexpr, # 每个线程块处理的元素数量
):
# 有多个'程序'处理不同的数据, 用pid标识当前是哪个程序
pid = tl.program_id(axis=0)
# 计算当前程序所需要的数据的偏置
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
# 创建一个掩码以防止内存操作超出范围
mask = offsets < n_elements
# 从 DRAM 加载 x 和 y
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
# 将计算结果output写回 DRAM
tl.store(output_ptr + offsets, output, mask=mask)
-
@triton.jit装饰器用于定义内核函数,在程序执行时即时编译并在GPU上执行。
-
x_ptr, y_ptr, output_ptr 分别是两个输入向量和一个输出向量的指针,n_elements表示向量长度,BLOCK_SIZE 的数据类型为 tl.constexpr,表示一个编译时的常量,定义了每个线程块处理数据时的数据长度。
-
向量相加虽然简单,但是基本体现了内核函数通常的编写流程,定义维度 -> 计算偏置 -> 设置掩码 -> 读取数据 -> 计算过程 -> 写回数据。
- 定义维度:当前程序(线程块)通过tl.program_id 获取自己的pid, 该程序id标识了当前程序的唯一性。tl.program_id和块大小(BLOCK_SIZE)也决定了并行处理时对整个数据块的划分,比如在这个向量数据的处理时,axis=0表示一维的划分,再比如矩阵乘法的操作,当我们用分块矩阵的思路设计内核时,则是在二维层面的操作。
- 计算偏置:得到当前程序的id时,我们需要从整个数据块拿取当前程序所需的那块数据,所以需要通过id和块大小(BLOCK_SIZE)计算offsets。需要注意的是,这里的offsets是一个list,即是当前需要的数据的所有索引。
- 设置掩码:因为数据的长度通常无法被我们预设的块大小整除,比如下图示例中的最后一块,所以需要设置mask,防止内存操作超出范围。
- 读取数据:根据输入数据的指针、偏置和掩码,从DRAM(显存) 读取数据到当前程序所在的SRAM(缓存)。
- 计算过程:在这里定义我们所需要的计算流程,例如将两段数据 x和y相加。
- 写回数据:处理完数据后,同样根据输出数据的指针、偏置和掩码,把结果output从SRAM写回DRAM。
线程块在GPU的计算模型里又被称为CTA(Cooperative Thread Array),以上的计算过程相当于一个CTA处理单个block。

而当缓存受限时,我们也可以在单个CTA中处理多个blocks, 如下图和相应的写法:

@triton.jit
def add_kernel(x_ptr, y_ptr, o_ptr, n_elements, num_blocks_per_CTA, BLOCK_SIZE: tl.constexpr,):
pid = tl.program_id(axis=0)
program_offsets = pid * num_blocks_per_CTA * BLOCK_SIZE
offsets = program_offsets + tl.arange(0, BLOCK_SIZE)
for i in range(num_blocks_per_CTA):
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(o_ptr + offsets, output, mask=mask)
offsets += BLOCK_SIZE
接口函数
有了内核函数,我们需要再写一个wrapper,就可以调用内核(好比Pytorch的torch.Add api, 即加号"+")。
def add(x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_ele 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









