




一、背景
最近我们在生产环境批量部署了大模型专用推理集群,并成功让包括70B在内的大模型推理速度提升50%,大幅缩减部署成本,稳定应用于生产环境。本文基于我们在部署大模型推理集群时的一些经验,分享一些有效提升大模型的推理速度方法。最后,我们在结尾处推荐了几个经过我们评测且表现优异的大模型推理框架。希望这些建议能帮助读者在项目中选择适合自己的推理框架。
OpenAI的科学家Hyung Won Chung在2023年的公开演讲《Large Language Models》[8]中指出,大模型的某些能力仅在达到特定规模时才能显现,可见未来大模型的参数量肯定会越来越大,这也是大模型的发展趋势。随着参数量的增加,对大模型的推理速度要求越来越高,有哪些方法可以提高大模型的推理速度或吞吐量?
首先我们将探讨大模型的加速优化方向,随后文章将依据时间线,介绍一些业界内较为经典的实用大模型加速技术,包括但不限于“FlashAttention[1]”和“PageAttention[3]”等技术。
以下为按时间顺序业界的一些经典大模型推理加速技术,本文试图为读者提供一个按时间发展顺序的大模型加速方法综述。

除了上面提到的技术外,提高大模型推理速度的还有大模型的量化技术等,这里先不探讨,后面有机会,我们会单独发文章来介绍。
二、大模型发展面临的挑战
未来大模型的参数量肯定会越来越大,这也是大模型的发展趋势,对推理加速的要求会越来越高。
OpenAI在其论文《Scaling Laws for Neural Language Models》[7]中介绍了大模型的扩展规则,这些规则阐释了模型能力与其规模之间的关系。具体来说,模型的能力强烈依赖于其规模,包括模型参数的数量,数据集的大小,以及训练过程中所需的计算量。此外,OpenAI的科学家Hyung Won Chung在2023年的公开演讲《Large Language Models》[8]中指出,大模型的某些能力仅在达到特定规模时才能显现。
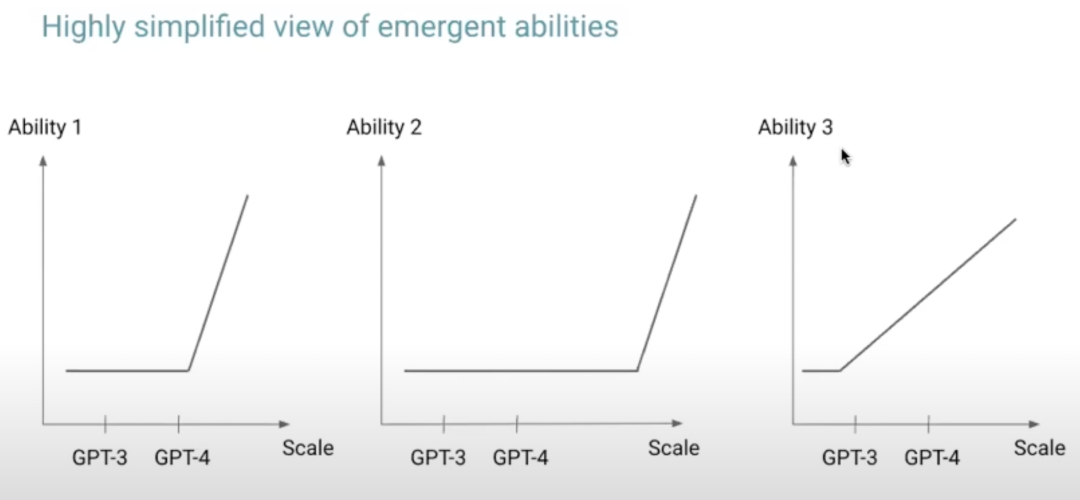
上图摘自Hyung Won Chung演讲中的ppt[8]。图中主要表达一个观点,随着模型规模的增大,比如GPT3到GPT4,模型的能力变的越来越强,甚至会出现新的能力。
但是随着模型的规模增大,大模型的推理速度将会逐渐降低,这是因为更多的参数量需要更多的GPU计算。推理速度的下降进一步带来更差的用户体验,因此如何对大模型推理加速变得越来越重要了。
三、大模型推理加速的优化方向
Llama2的模型结构
我们先简单了解一下Llama 2模型系列的结构,参考自Llama 2的论文[9]。目前,像Llama系列这样的大多数生成式语言模型,主要采用了Transformer架构中的Decoder模块。在Huggingface平台上,这类模型结构通常被称作CausalLM,即因果语言模型。
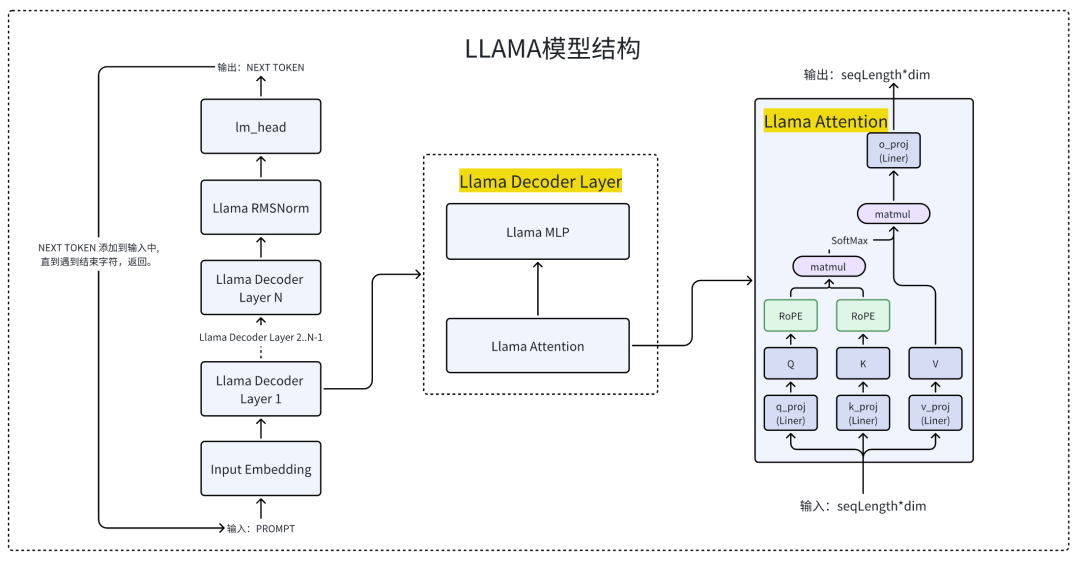
上图为Llama2大模型的结构,其中最核心的是注意力计算(Llama Attention)。这也是整个推理过程中最耗费时间的模块,后面的优化大部分都是基于Attention去实施的。为了更好的理解Llama 2大模型的结构,我们先简单对Llama2模型的整个推理过程进行拆解,不感兴趣同学可以直接跳过。
-
用户向模型提交Prompt后,模型首先进行的操作是预测下一个字符(Token),并将预测出的字符添加到输入中继续进行预测。这个过程会一直持续,直到模型输出一个停止符号(STOP token),此时预测停止,模型输出最终结果。
-
在生成下一个字符(Token)的过程中,模型需要执行N次的Llama解码器层(Llama Decoder Layer)计算。具体来说,Llama-2-7B模型执行32次计算,而Llama-2-13B模型执行40次。
-
Llama解码器层(Llama Deco
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 297
297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









