




前言:
得物消息中心每天推送数亿消息给得物用户,每天引导数百万的有效用户点击,为得物App提供了强大,高效且低成本的用户触达渠道。这么庞大的系统,如何去监控系统的稳定性,保证故障尽早发现,及时响应至关重要。为此,我们搭建了得物消息中心SLA体系,相关架构如图:
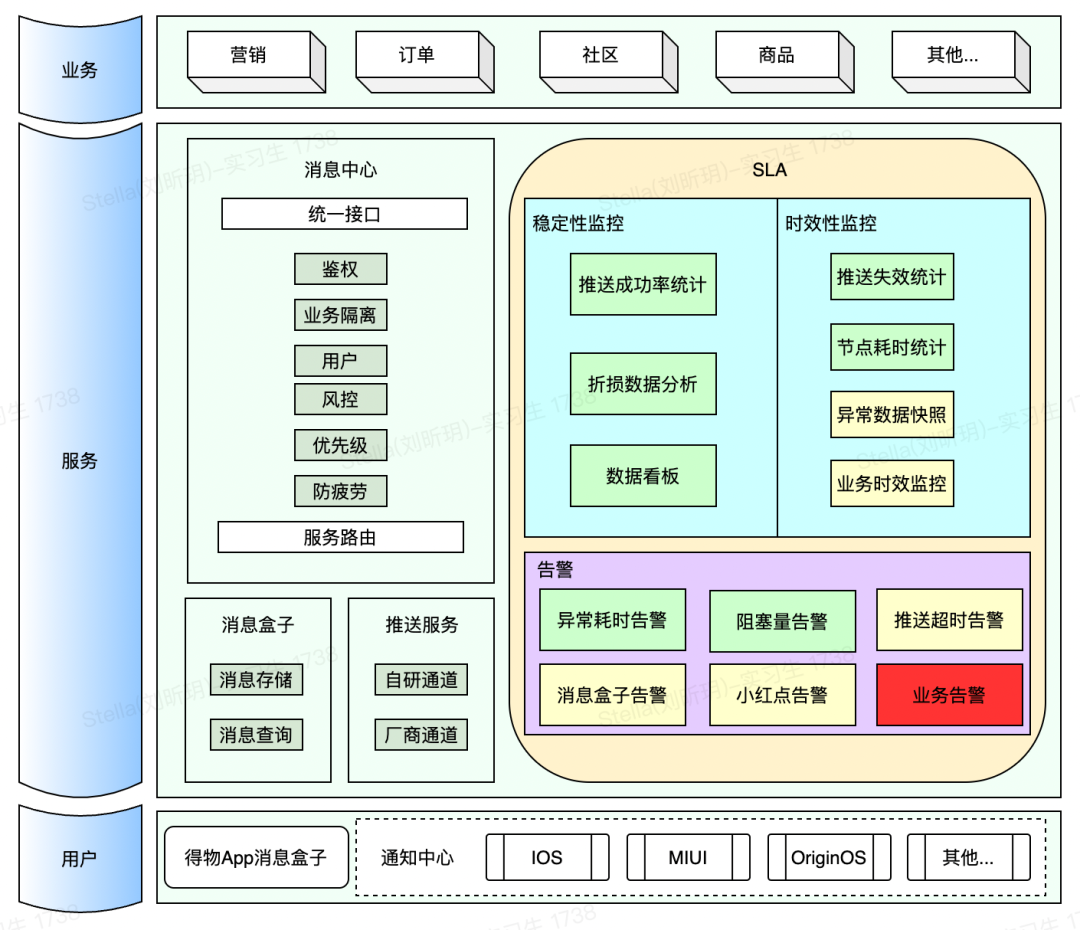
本文主要介绍我们如何实现SLA监控体系,并一步步重构优化的,作为过去工作的经验总结分享给大家。
1. 背景
得物消息中心主要承接上游各业务的消息推送请求,如营销推送、商品推广、订单信息等。消息中心接受业务请求后,会根据业务需求去执行【消息内容检验,防疲劳,防重复,用户信息查询,厂商推送】等节点,最后再通过各手机厂商及得物自研的在线推送通道触达用户。整体推送流程简化如下:

我们希望能够对各个节点提供准确的SLA监控指标和告警能力,从而实现对整体系统的稳定性保证。下面是我们设计的部分指标:
- 监控指标
- 节点推送量
- 节点推送耗时
- 节点耗时达标率
- 整体耗时达标率
- 节点阻塞量
- 其他指标
- 告警能力
- 节点耗时告警
- 节点阻塞量告警
- 其他告警能力
那我们如何实现对这些指标的统计呢?最简单的方案就是在每个节点的入口和出口增加统计代码,如下:
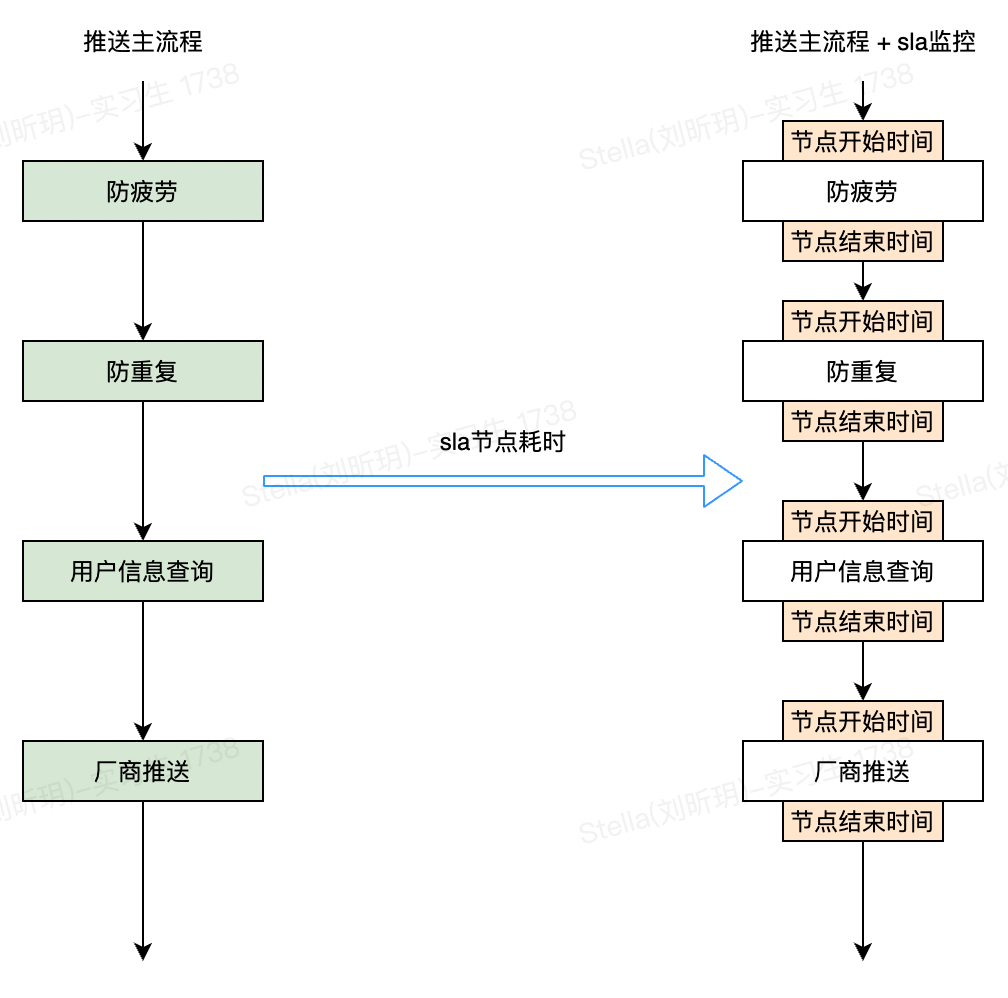
这就是我们的 方案0 我们用这种方案快速落地了SLA-节点推送数量统计的开发。但是这个方案的缺点也很明显,考虑以下几个问题:
- 如何实现另一个SLA指标开发?比如节点耗时统计,也需要在每个节点的方法内部增加统计代码。
- 如果有新的节点需要做SLA统计,怎么办?需要把所有的统计指标在新节点上面再实现一遍。
- 如何避免SLA统计逻辑异常导致推送主流程失败?到处加try{}catch()去捕获异常吗?
- 如何分工?除了节点耗时统计外还有很多其他指标要实现。最简单的分工方式就是按照SLA指标来分工,各自领几个指标去开发,问题在于各个指标的统计逻辑都耦合在一起,按照统计指标来分工事实上变的不可能。
项目开发不好分工,通常意味着代码耦合度过高,是典型的代码坏味道,需要及时重构。
2. 痛点和目标
从上面的几个问题出发,我们总结出 方案0 的几个痛点,以及我们后续重构的目标。
2.1 痛点
- 监控节点不清晰。消息推送服务涉及多个不同的操作步骤。这些步骤我们称之为节点。但是这些节点的定义并不明确,只是我们团队内部约定俗成的一些概念。这就导致日常沟通和开发中有很多模糊空间。
在项目开发过程中,经常会碰到长时间的争论找不到解法。原因往往是大家对基础的概念理解没有打通,各说各话。这时候要果断停止争论,首先对基本概念给出一致的定义,然后再开始讨论。模糊的概念是高效沟通的死敌。
- 维护困难。
- 每个节点的统计都需要修改业务节点的代码,统计代码分散在整个系统的各个节点,维护起来很麻烦;
- 同时推送流程的主要逻辑被淹没在统计代码中。典型的代码如下,一个业务方法中可能有三分之一是SLA统计的代码。
protected void doRepeatFilter(MessageDTO messageDTO) {
//业务逻辑:防重复过滤
//...
//业务逻辑:防重复过滤
if (messageSwitchApi.isOpenPushSla && messageDTO.getPushModelList().stream()
.anyMatch(pushModel -> pushModel.getReadType().equals(MessageChannelEnums.PUSH.getChannelCode()))) {
messageDTO.setCheckRepeatTime(System.currentTimeMilli 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









