




 针对大数据量商品集的处理,原Java Set结构因内存占用过高导致服务宕机。引入RoaingBitmap数据结构,通过位数组存储数据,降低内存占用并支持高效运算。在标签刷新场景中,使用RoaingBitmap进行差集运算,减少内存消耗,提升刷新速度和写入效率。对比测试表明,RoaingBitmap在内存占用和CPU耗时上优于其他Bitmap实现,平均提升刷新速度52.42%,写入量级降低86.98%。
针对大数据量商品集的处理,原Java Set结构因内存占用过高导致服务宕机。引入RoaingBitmap数据结构,通过位数组存储数据,降低内存占用并支持高效运算。在标签刷新场景中,使用RoaingBitmap进行差集运算,减少内存消耗,提升刷新速度和写入效率。对比测试表明,RoaingBitmap在内存占用和CPU耗时上优于其他Bitmap实现,平均提升刷新速度52.42%,写入量级降低86.98%。
背景
目前,在商品圈选投场景,每个标签id都会根据规则/指标绑定一定数据量的商品集,在圈选规则条件变动或者定时任务触发时会进行商品集的刷新,新增符合规则的商品,删除不符合规则的商品。
但是由于商品集下的spu数量大部分都在数十万,多的能达到上百万,如果直接将刷新前后各十万甚至百万的spu全量放到内存中互相做diff,再对diff得到的差集做增删,当同一时间刷新的标签数量过多时,内存就很容易溢出,造成整个服务宕机。
同时目前底层存储商品集的数据库为Hbase,因此在标签侧对于商品集的刷新场景目前都是采取全增全删的策略,即把刷新后的商品集先全量保存一次(利用Hbase 保存的幂等性,同一个rowkey的数据重复保存会进行覆盖,而不用在保存前做额外的数据是否存在的判断),并更新数据的modity_time=now(),然后再从Hbase中分批scan遍历商品集,找到modity_time<now的再进行删除,以此完成一次标签的刷新任务。
往往一个商品集在刷新前后真正变化的spu量并不大,通过取数分析得知变化的不会超过商品集数量的10%。而我们目前采用的这种全增全删的策略,每次刷新后都会有大量已有数据的重复插入,不仅延长了刷新的速度,也增加底层储存的压力,同时由于选投平台里有标签的指标,标签的变动需要推送变化的spu给选投平台进行重新圈品,同时spu es 中也存有标签的数据用于后台展示,所以当前全增全删的策略,尤其是大量已有数据的重复插入,都会同步到选投平台和spu es侧,对他们造成大量的性能浪费和处理成本,改造迫在眉睫。
优化方案
前面提到,由于传统的java Set结构在数据量较大的情况,占用内存较多,导致无法将前后海量商品集的数据全部存到内存中去做运算。
那么有没有一个数据结构可以在存海量数据时还能保持较低的内存占用,支持去重,还支持交集,差集等各种运算呢?
Bitmap完美满足要求。
Bitmap是通过bit数组来存储数据的数据结构,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。Bitmap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
同时由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。例如储存500W数据仅需5000000/8/1024/1024=0.5M内存。
因此准备使用Bitmap结构来存储刷新前后的商品集,然后分别对新老Bitmap互相求差集得到,最终对差集进行add和delete操作即可。
方案可行性分析
以标签场景为例。
标签可以绑定选投平台,标签系统会把选投平台圈选的所有商品集都打上标,此刻标签下的商品集记为oldSset(X+Y)。
选投平台刷新后,会重新圈选出一批满足选投平台指标的商品集,此时选投平台下的商品集记为newSet(Y+Z) 。
此时标签系统需要给newSet(Y+Z)打标,同时从oldSet(X+Y)删除不在本次圈选范围内的商品(X)。
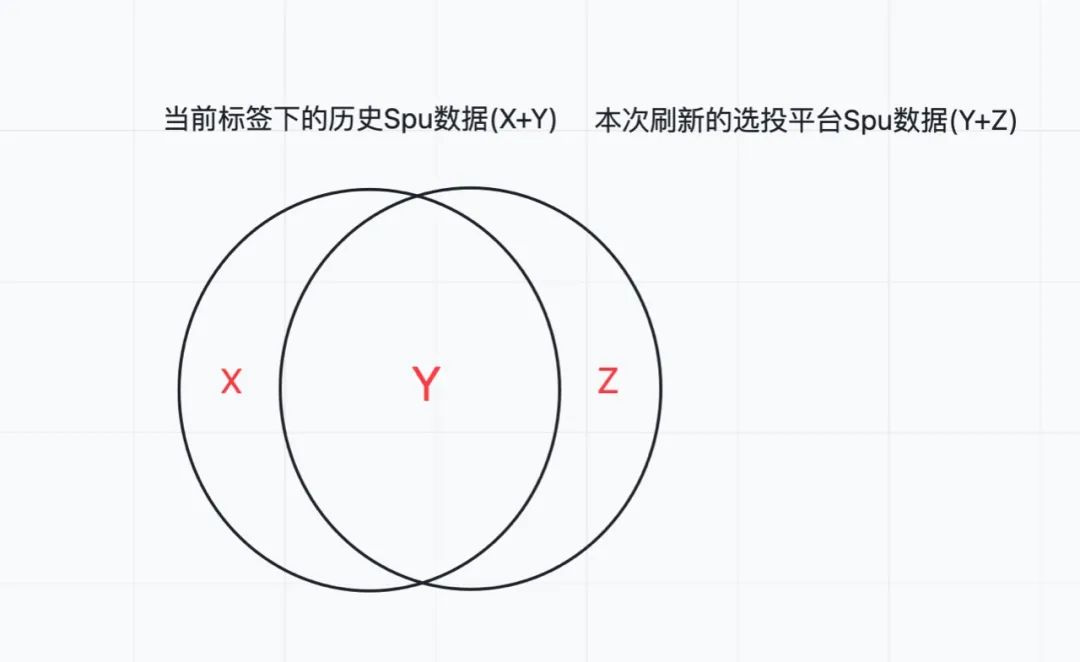
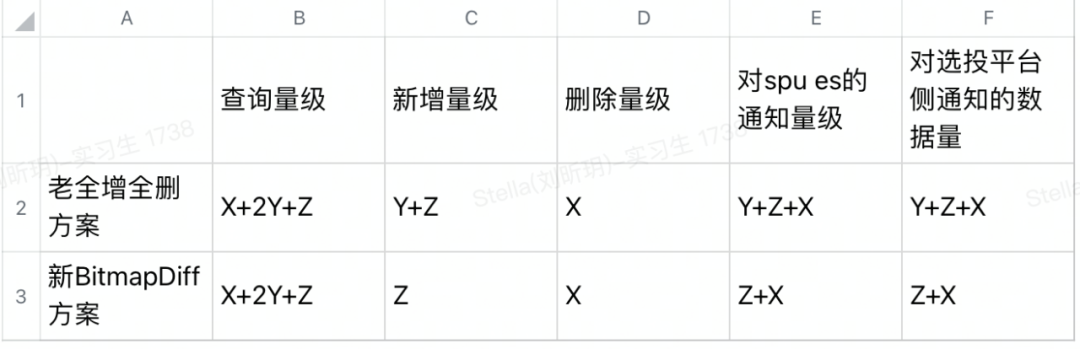
标签商品集底层储存是Hbase,对于已存在数据的插入,只要rowkey(标签id+spuId)不变, Hbase就会进行覆盖,保存最新时间戳的数据,可以理解为老Y已经被新Y覆盖(老Y数据=新Y数据,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









