



一、项目简介
本项目是一个基于深度学习的手写汉字识别系统,系统采用 MobileNet_v1 轻量化卷积神经网络作为特征提取模型,并利用 PyTorch 框架进行构建与训练。
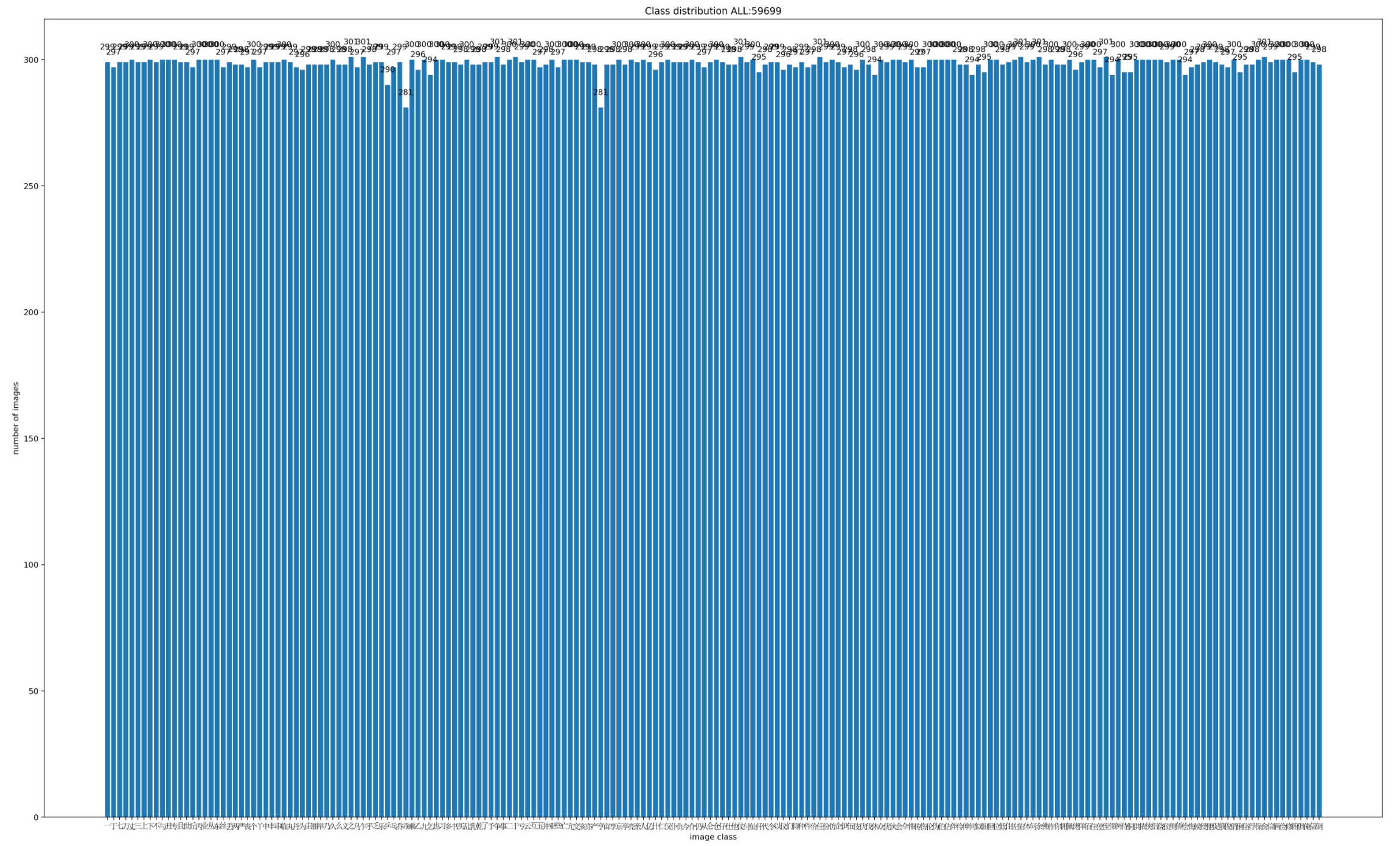
在数据集方面,从网络采集了 200 类共计 59699 张手写汉字图像,按 8:2的比例划分为训练集、验证集,并结合随机裁切、随机翻转方法进行数据增强以提高模型的泛化能力。
实验过程中,设置输入图像尺寸为 224×224,采用 AdamW 优化器与交叉熵损失函数进行训练,并以验证集损失最低点作为模型保存的依据。
测试结果表明,系统在数据集上平均准确率达到 98%
最后,基于Pyqt5 框架开发了可视化 GUI 界面,实现了手写汉字图像的可视化上传与分类识别功能。
PS注:本项目设计了两种不同的界面样式项目01和02,分别如下(两者除界面样式和功能略有不同外,其他算法数据集等其他部分及对应代码全部是一样的,大家根据自己的喜好选择即可,两者分开,任选其一):
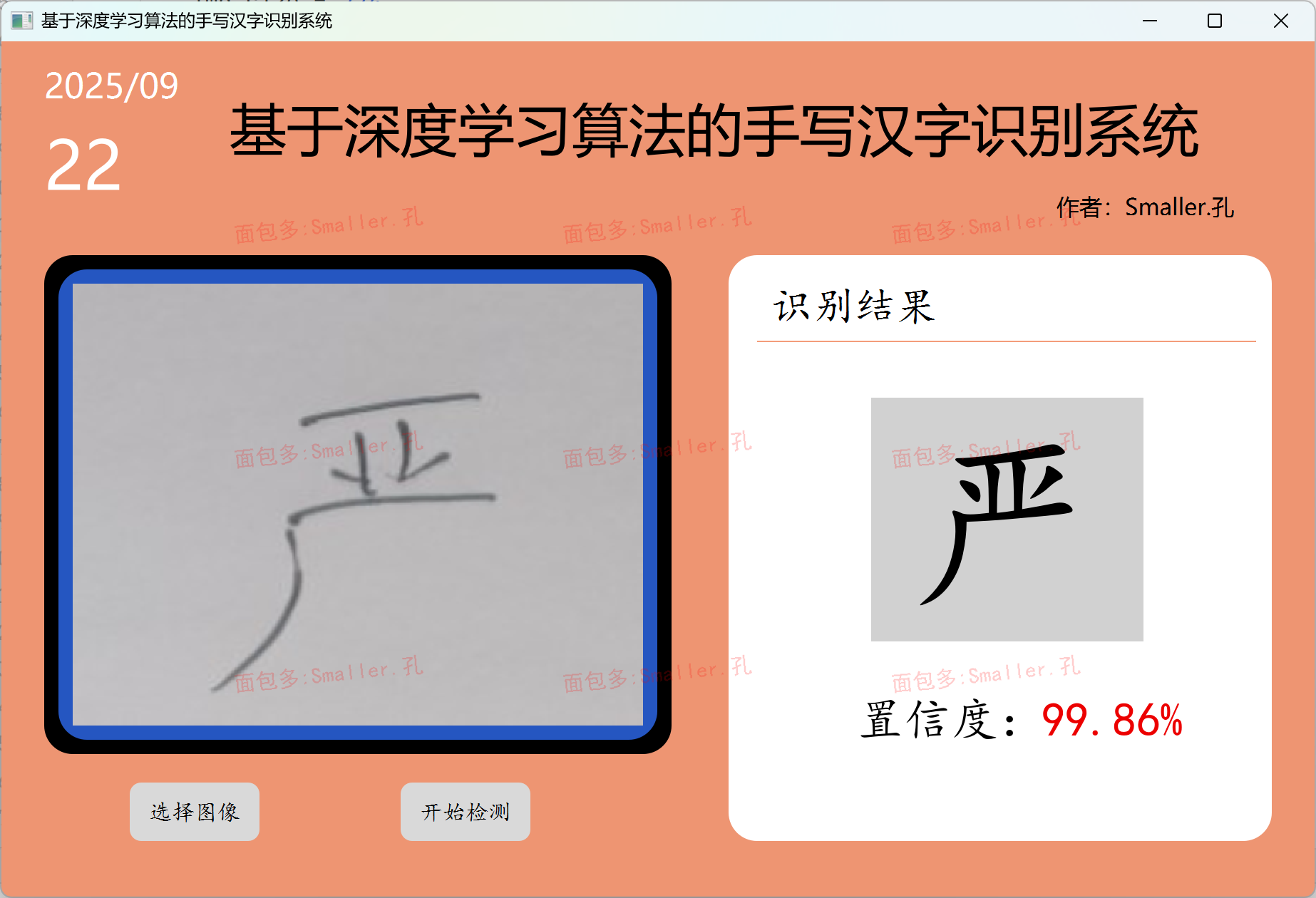
样式01:界面简洁,只单张图像检测功能,可自由设置纯色背景颜色或背景图像
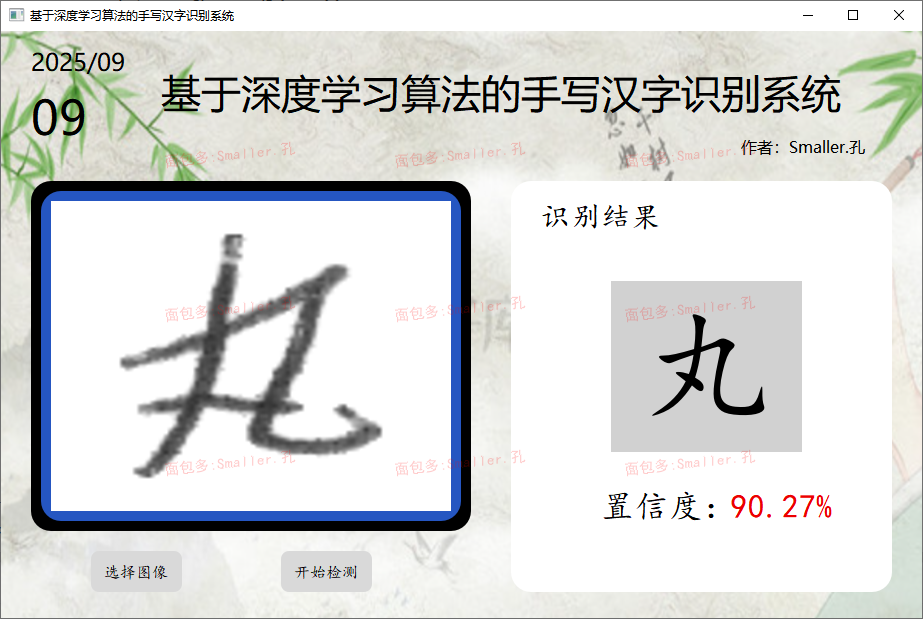
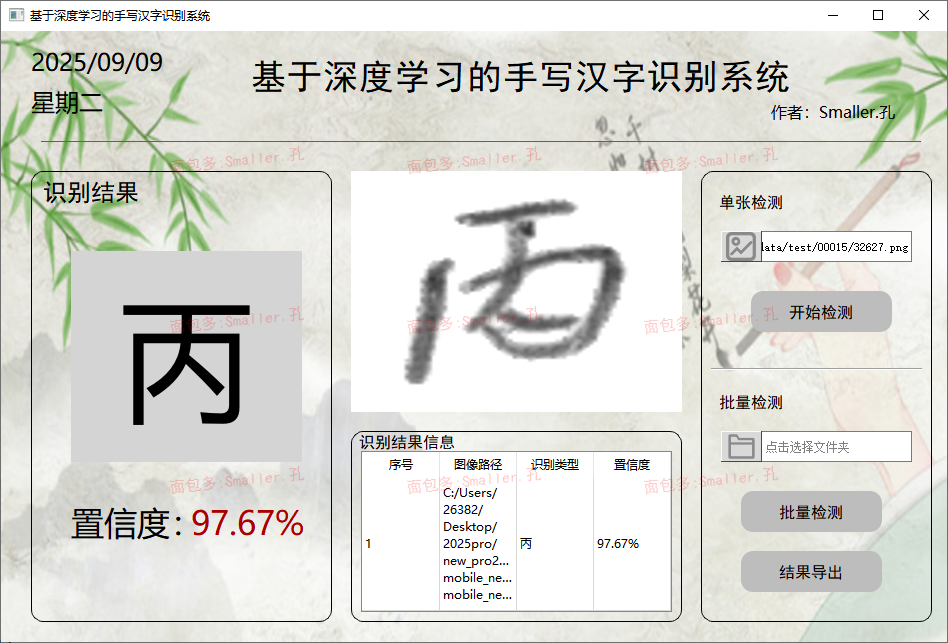
样式02:含单张图像和批量图像检测两种功能,可自由设置背景图像
二、项目文件介绍
样式01项目:

样式02项目:

先看我-项目使用说明
核心文件
- train.py —— 模型训练主脚本,包含完整的训练流程,包括数据加载、模型构建、训练循环、验证评估、日志记录和训练曲线可视化
- models/mobilenet.py —— MobileNet_v1网络架构定义
- my_dataset.py —— 自定义数据集类,继承PyTorch的Dataset,实现图像加载和预处理
- utils.py ——工具函数集合,包含数据集分割、训练评估函数、图像可视化等通用功能
- predict.py —— 单张图像预测脚本,用于模型推理和分类结果输出
用户界面文件
- 主界面.py - PyQt5图形界面后端主程序,提供图像选择、分类检测和结果显示功能
- ui.py - PyQt5界面设计代码,定义GUI布局和控件
- ui.ui - Qt Designer界面文件,用于界面设计
评估和可视化文件
- process - 数据预处理可视化代码及结果
- confusion_matrix.py - 混淆矩阵生成和可视化,用于模型性能分析
配置和数据文件
- class_indices.json - 类别索引映射文件,存储汉字编号与数字ID的对应关系
- data_name-汉字编号对应的中文汉字名
- weights/best-epoch.pth - 训练好的模型权重文件
- font/ - 中文字体文件目录
数据集目录
- all_data/ - 完整数据集目录
三、项目环境配置
硬件要求
- CPU:Intel i5或同等性能
- 内存:8GB以上
- 存储:10GB可用空间
- GPU:NVIDIA GPU(可选,用于加速训练)
软件环境
- 操作系统:Windows 10/11, Linux, macOS
- Python版本:3.11
- CUDA版本:11.0+(如使用GPU)
依赖包版本
torch==2.5.1
torchvision==0.20.1
matplotlib==3.10.0
scikit-learn==1.6.0
pyqt5==5.15.11
opencv-python==4.11.0.86
tensorboard==2.18.0
tqdm==4.67.1
环境配置教程
获取到项目文件后,将项目文件下载到电脑本地任意路径,然后解压后,严格根据如下环境配置教程一步步即可完成配置使用(注:建议新手和对环境配置不太熟悉的同学最好按照下方视频教程一步步操作即可,基本不会出现问题,若出现问题咨询售后即可,百分百确保程序运行使用):
https://mbd.pub/o/bread/mbd-YZWXkpxqag==
四、项目使用说明
根据第三部分环境配置教程,完成本地项目的环境部署配置后即可运行使用。
使用说明(确保pycharm打开项目文件并配置好环境):
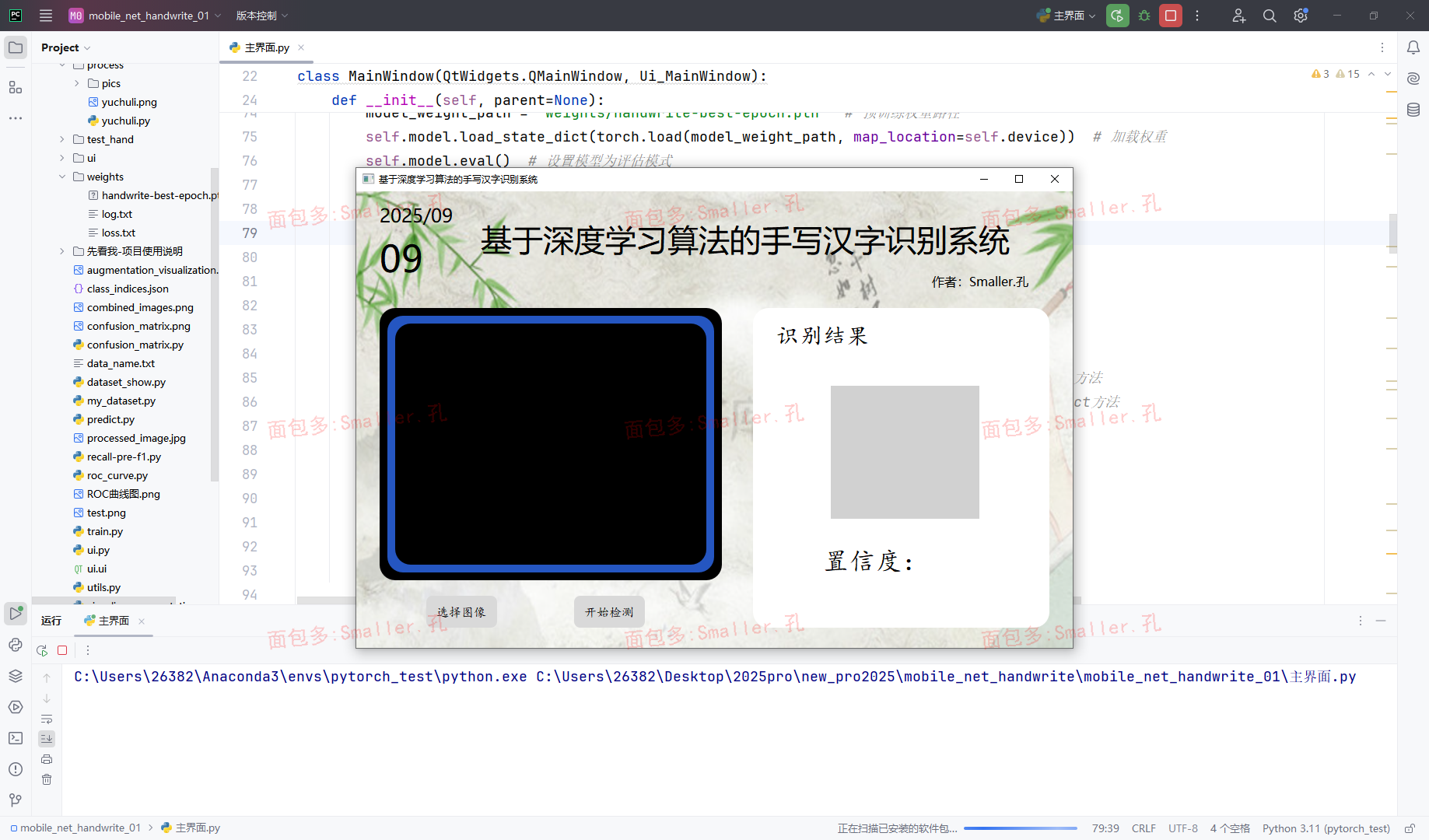
主程序运行使用
打开主界面.py,然后鼠标右键点击run运行(01和02项目相同),等待程序加载完毕界面弹出即可
具体可看如下项目运行使用效果视频:
项目01运行效果视频:https://www.bilibili.com/video/BV15TUpYEEwL
项目02运行效果视频:https://www.bilibili.com/video/BV133UpYyEs4
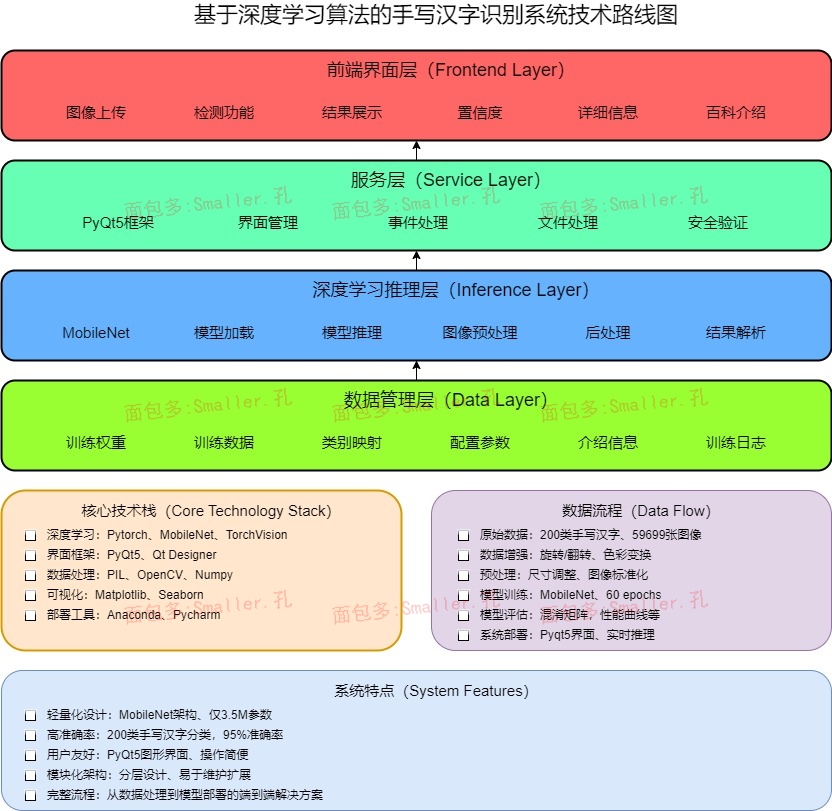
五、项目技术路线
核心技术栈
深度学习: PyTorch 2.5.1
界面框架:Pyqt5、Qt Designer
网络架构: MobileNet v1
图像处理: PIL/Pillow, OpenCV
数据可视化: Matplotlib, TensorBoard
部署工具:Anaconda、Pycharm
六、项目开发流程
训练流程
原始数据 → 数据增强 → 数据预处理 → 模型训练 → 模型评估 → 本地环境部署
↓ ↓ ↓ ↓ ↓ ↓
200类汉字图像 旋转/翻转 图像标准化 MobileNet 混淆矩阵 Anaconda Pycharm
59699 张 色彩变换 尺寸调整 60 epochs 精确度曲线 Python3.11 Pytorch
推理流程
用户上传图像 → 文件验证 → 图像预处理 → 模型推理 → 后处理 → 结果返回
↓ ↓ ↓ ↓ ↓ ↓
前端界面 格式检查 尺寸调整 MobileNet Softmax JSON响应
点击上传 安全检查 标准化 前向传播 概率计算 置信度
1)数据集准备
all_data文件夹,每个文件夹中分别含有相同的类别文件夹,训练时按照8:2将数据集划分为训练集:验证集
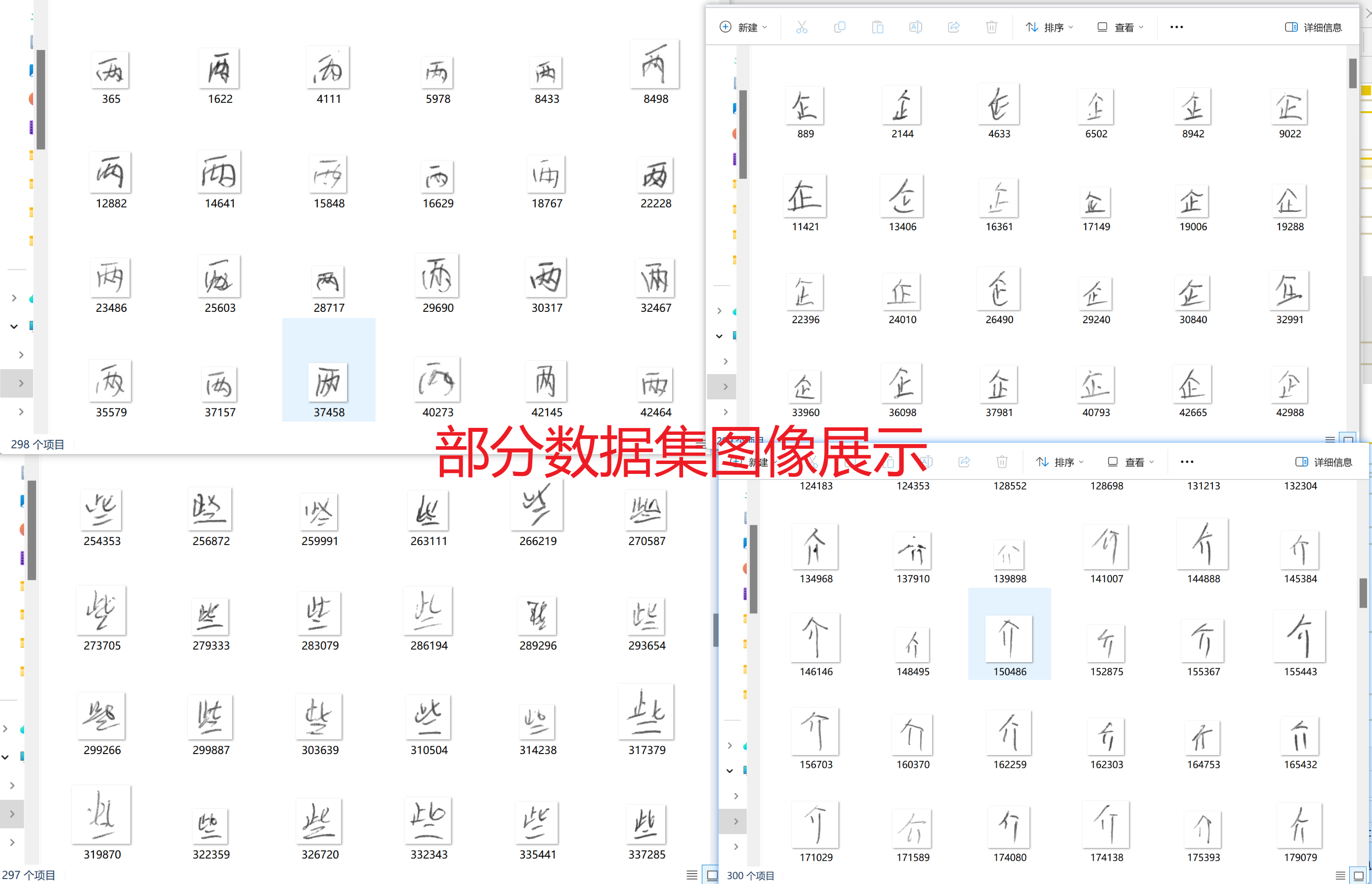
如果需要替换数据集,则在all_data文件夹中创建子类别文件夹,类别文件夹中分别放入不同数量类别图像即可。(注意替换数据集后需要重新按照下面的步骤训练新的模型才可以正常使用,因为数据集和训练好的模型是一一对应的,并且训练时间通常较长)
比如我需要重新训练模型使其可以识别类别1,类别2,类别3,则在all_data文件夹创建名称为类别1,类别2,类别3的子文件夹(原来不需要的类别文件夹要删除),然后在对应文件夹放入对应的类别图像即可。
即需要训练识别哪些类别,就在all_data文件夹创建哪些类别名的文件夹并放入对应数量的类别图像。
以上部分为有需要替换数据集需要的,不需要替换的同学忽略即可。
2)数据集分布可视化
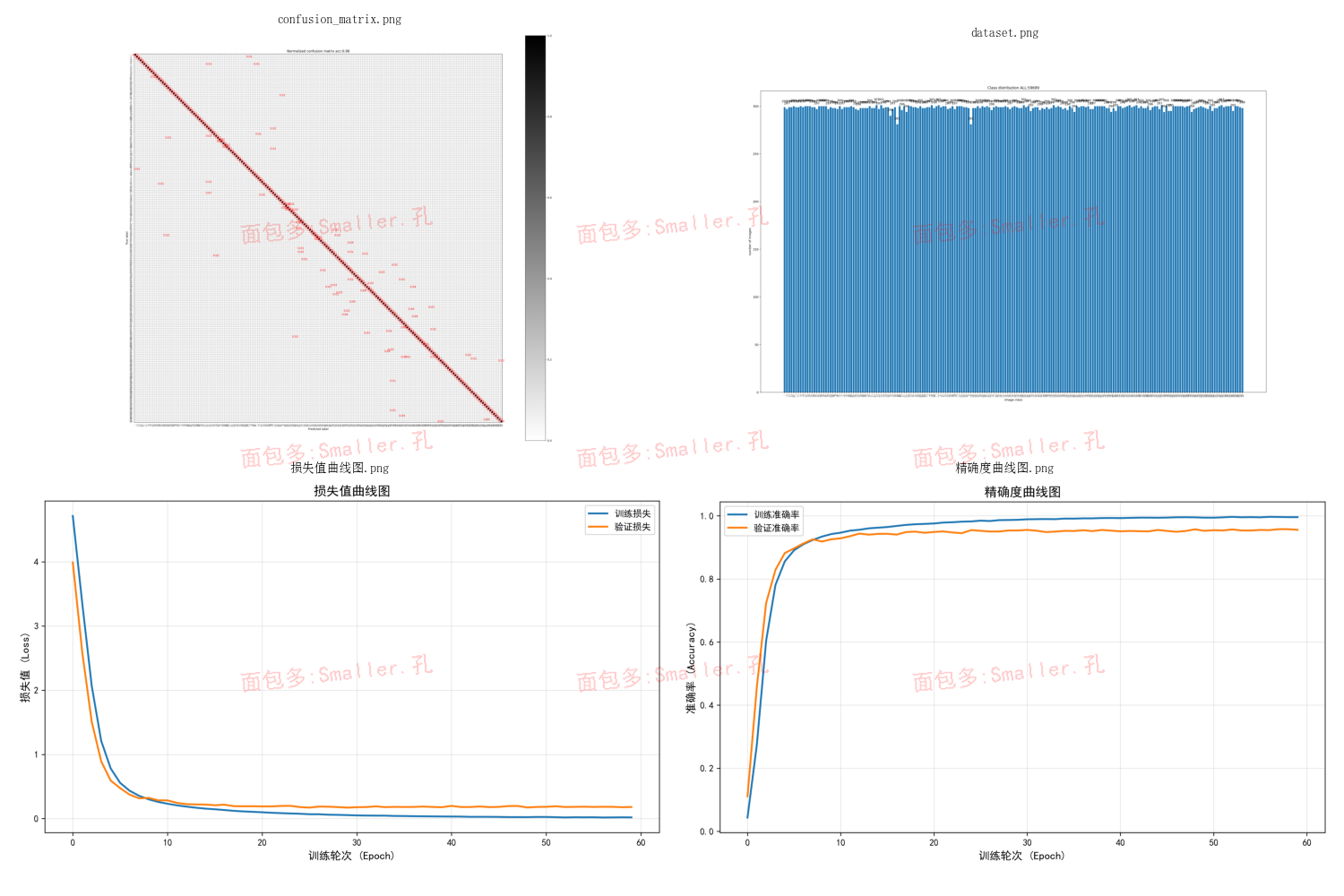
运行train.py代码后,会生成dataset.png,展示各类数据集的分布情况。
3)数据增强可视化
系统在模型训练时会采用数据增强策略,具体代码在train.py中如下:
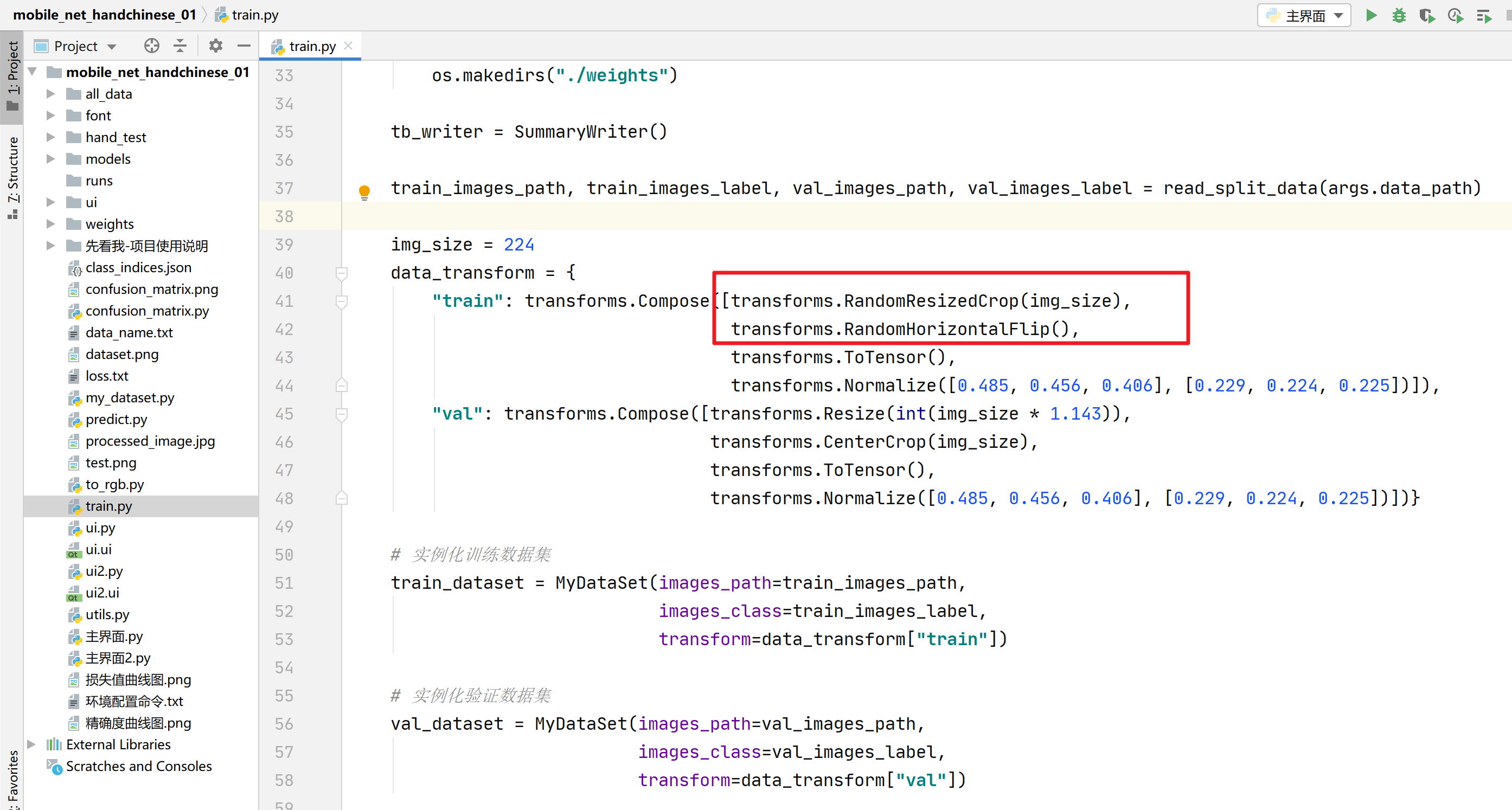
基础增强(所有强度):
随机裁剪和缩放 (RandomResizedCrop)
随机水平翻转 (RandomHorizontalFlip)
4)数据预处理可视化
数据预处理流程包括以下步骤:
- 图像读取和格式转换
- 直方图均衡化 —— 增强图像对比度
- 灰度化处理 —— 统一颜色空间
- 尺寸统一 —— 调整到224×224像素
- 归一化 —— 像素值缩放到[0,1]范围
执行process文件夹中的yuchuli.py代码,可生成yuchuli.png图像,可视化预处理过程。

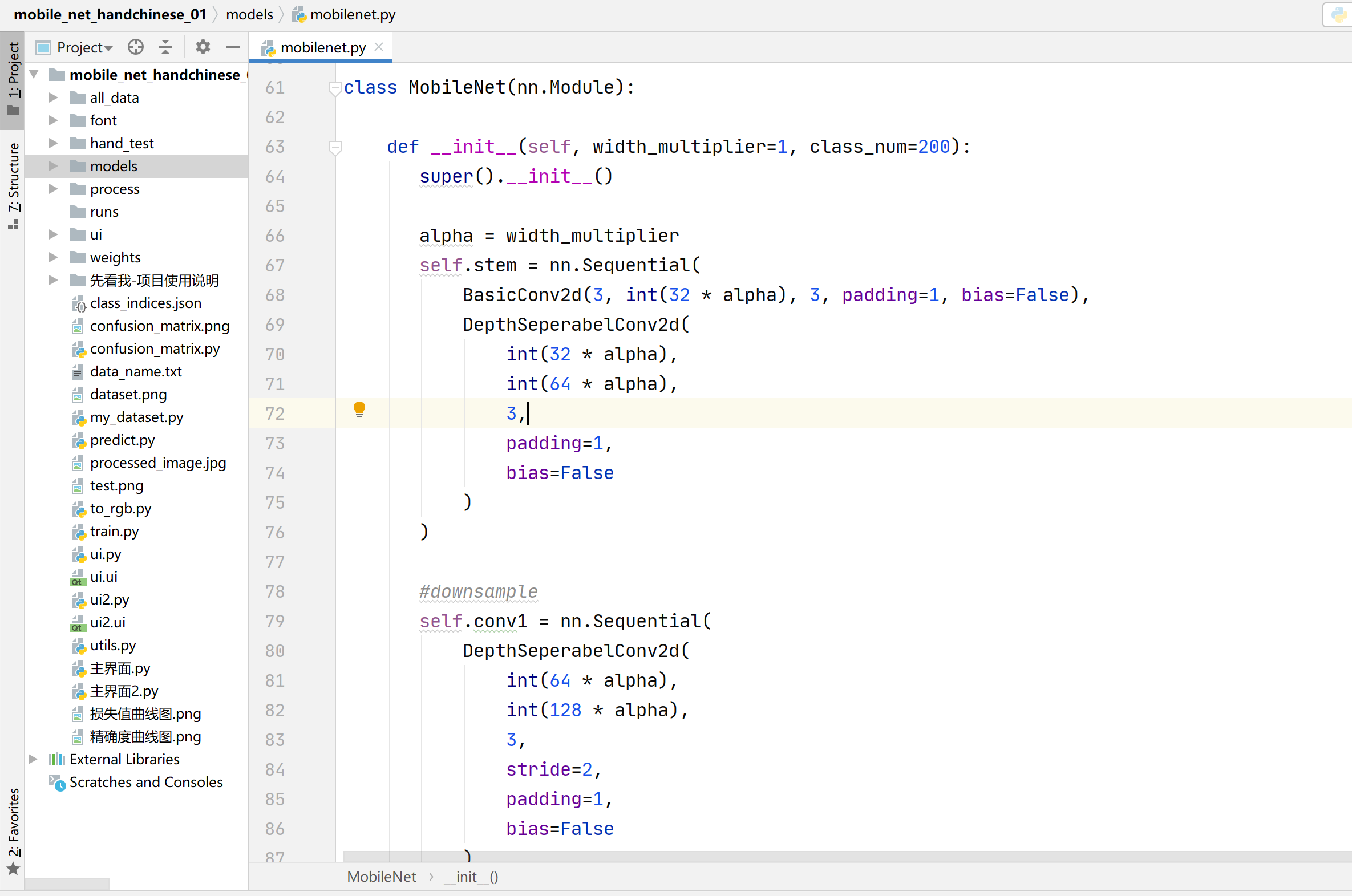
5)算法网络构建
通过Pytorch深度学习框架搭建mobilenet_v1算法网络,具体代码见models文件夹中的mobilenet.py
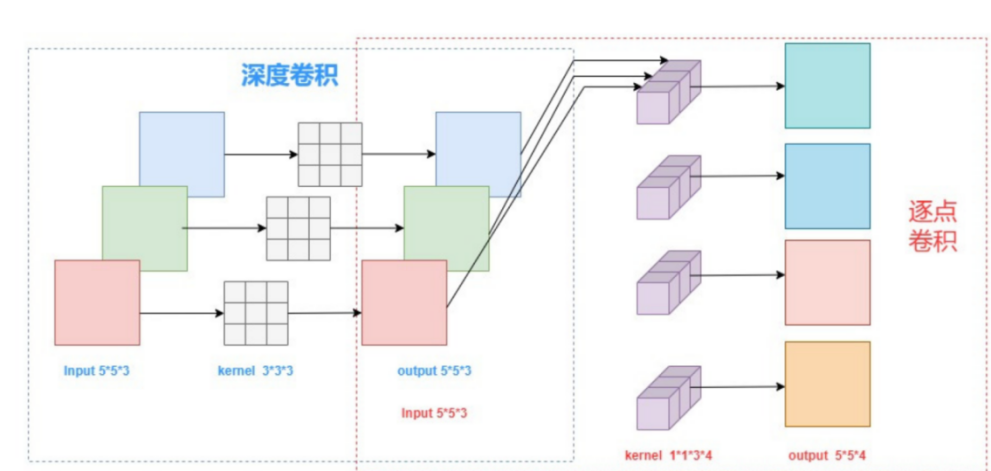
核心创新
MobileNet采用深度可分离卷积技术,将标准卷积分解为:
深度卷积: 每个输入通道独立卷积
逐点卷积: 1×1卷积进行通道组合
计算量优化
标准卷积: H×W×K×K×C_in×C_out
深度可分离卷积: H×W×K×K×C_in + H×W×C_in×C_out
计算量减少: K×K倍 (3×3卷积减少9倍)
Mobilenet_v1算法网络结构图
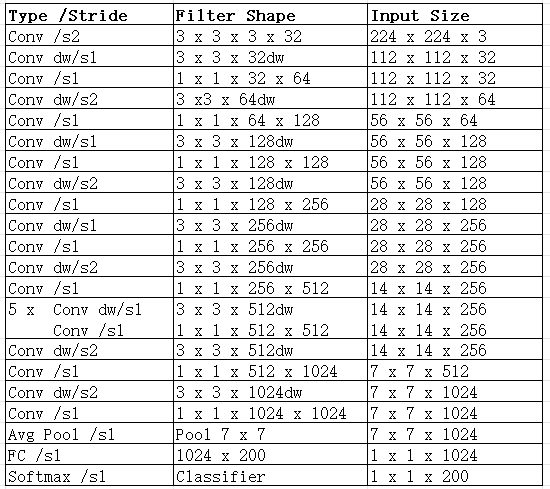
更多mobilenet_v1算法网络相关介绍,可自行搜索即可,参考资料很多。
6)训练超参数设置
准备好数据集和算法网络后,则开始进行训练阶段的超参数设置。train.py最下方可进行超参数设置
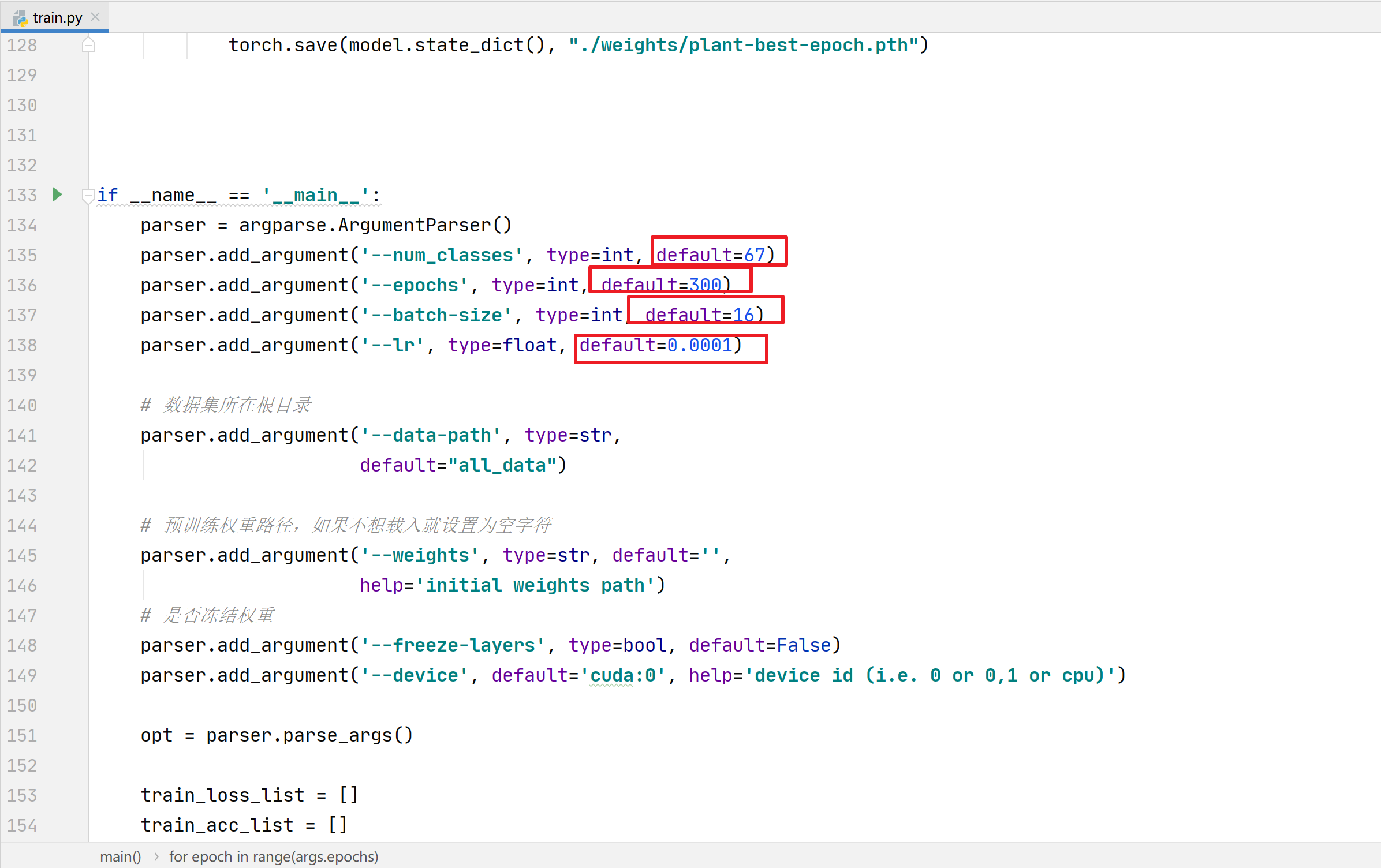
本项目相关超参数设置情况:
优化器:AdamW
损失函数:CrossEntropyLoss(交叉熵损失函数)
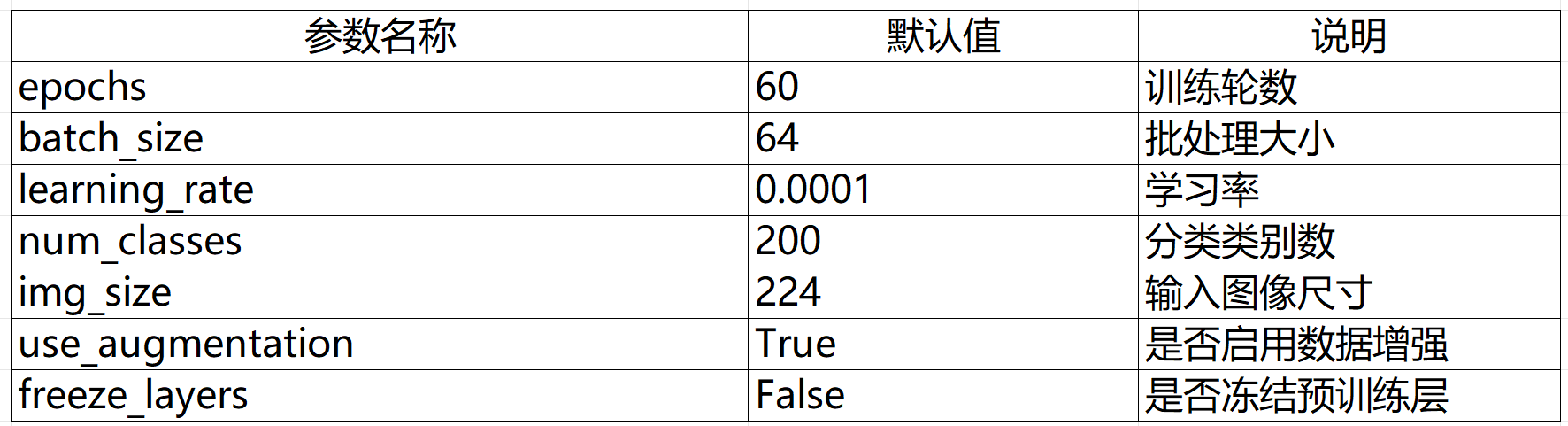
注:数据集中的类别数要和num_classes对应,如果替换了数据集这个参数要对应修改下,其余可不变
7)模型训练
在train.py中设置好相关超参数后运行train.py即可开始模型训练(注:深度学习项目训练时间通常较长,故本项目提供已训练好的权重文件weights文件夹,可供大家直接使用即可,省去训练步骤,但若重新对数据集进行替换调增,则必须要按步骤训练完毕才可正常使用)
训练流程:
- 数据加载和预处理
- 模型初始化和权重加载
- 优化器配置 (AdamW)
- 训练循环:
- List item
- 前向传播
- 损失计算(CrossEntropyLoss)
- 反向传播
- 参数更新
- 验证评估
- 模型保存
训练监控:
训练完毕后会自动生成如下几个文件:
- log.txt日志记录(记录每一个epoch的epoch,train-loss,train-acc,val-loss,val-acc
数据) - loss.txt记录(记录保存的模型对应的epoch,train-loss,train-acc,val-loss,val-acc
数据) - 训练曲线绘制(自动生成准确率曲线图.png和损失值曲线图.png)
- 最佳模型保存(weights文件夹生成训练好的pth模型权重文件)
8)非界面预测使用
训练完毕,得到训练好的模型权重文件后,可以通过predict.py来进行非界面的简单测试使用:
在框选位置输入要测试的图像路径,运行predict.py即可测试使用,运行后pycharm下方显示预测结果信息
9)模型评价指标生成
除上述训练后自动生成的训练集和验证集上的准确率和损失值曲线图外,本项目提供其他分类指标以评估训练好的模型效果。
混淆矩阵图
运行confusion_matrix.py,等待程序运行完毕后,即可生成confusion_matrix.png图像
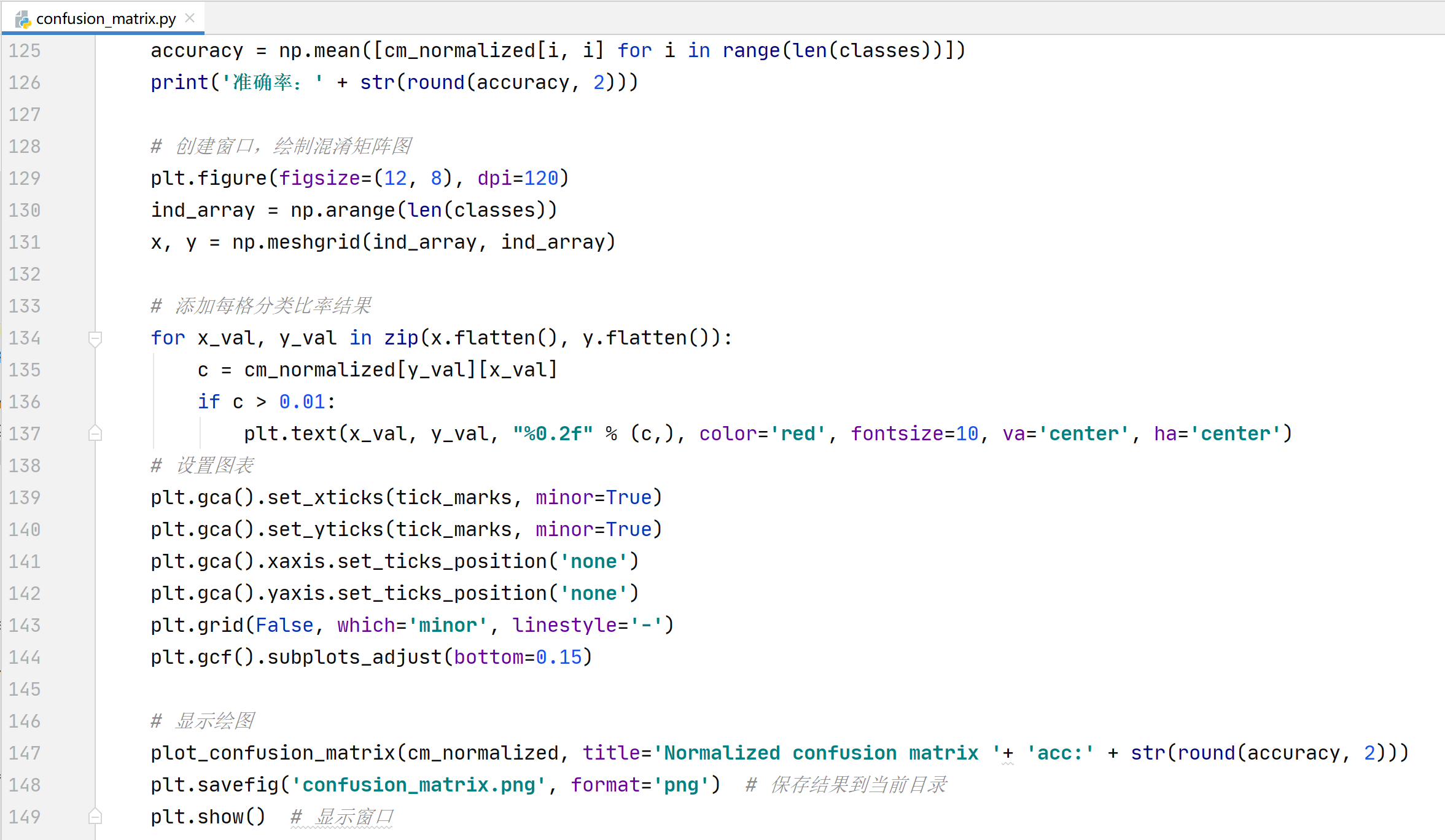
斜对角线显示了模型在随机一部分数据集上每一类的准确率,标题中的数据为模型在随机一部分数据集上的平均准确率。
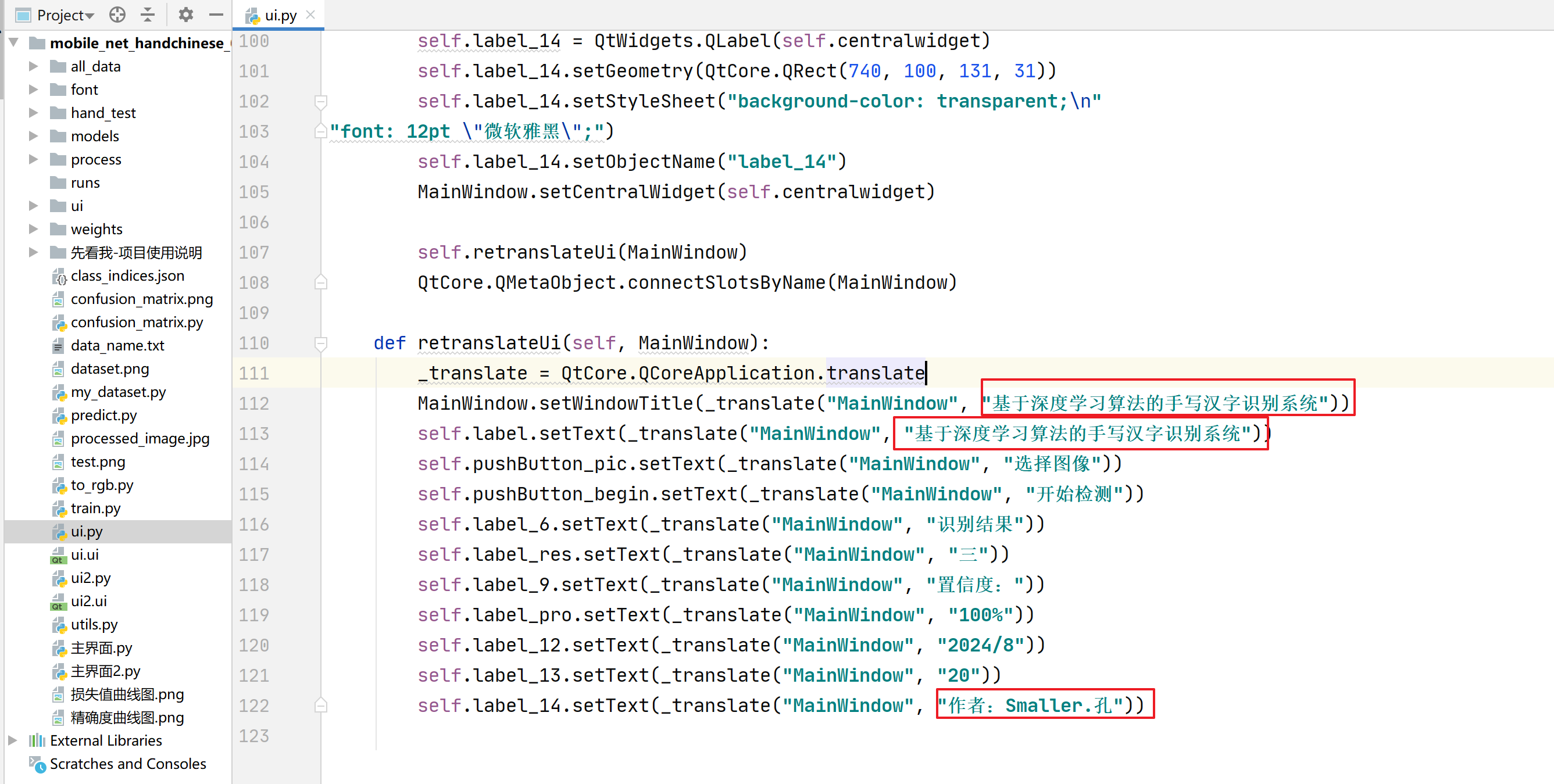
10)Pyqt5端前端界面(系统标题/作者水印/界面背景修改)
样式01和02项目对应的界面代码:
界面对应代码:ui.py/ui2.py
在此代码中可进行系统标题、界面对应文本和作者水印的修改,对应修改如下对应文本内容即可
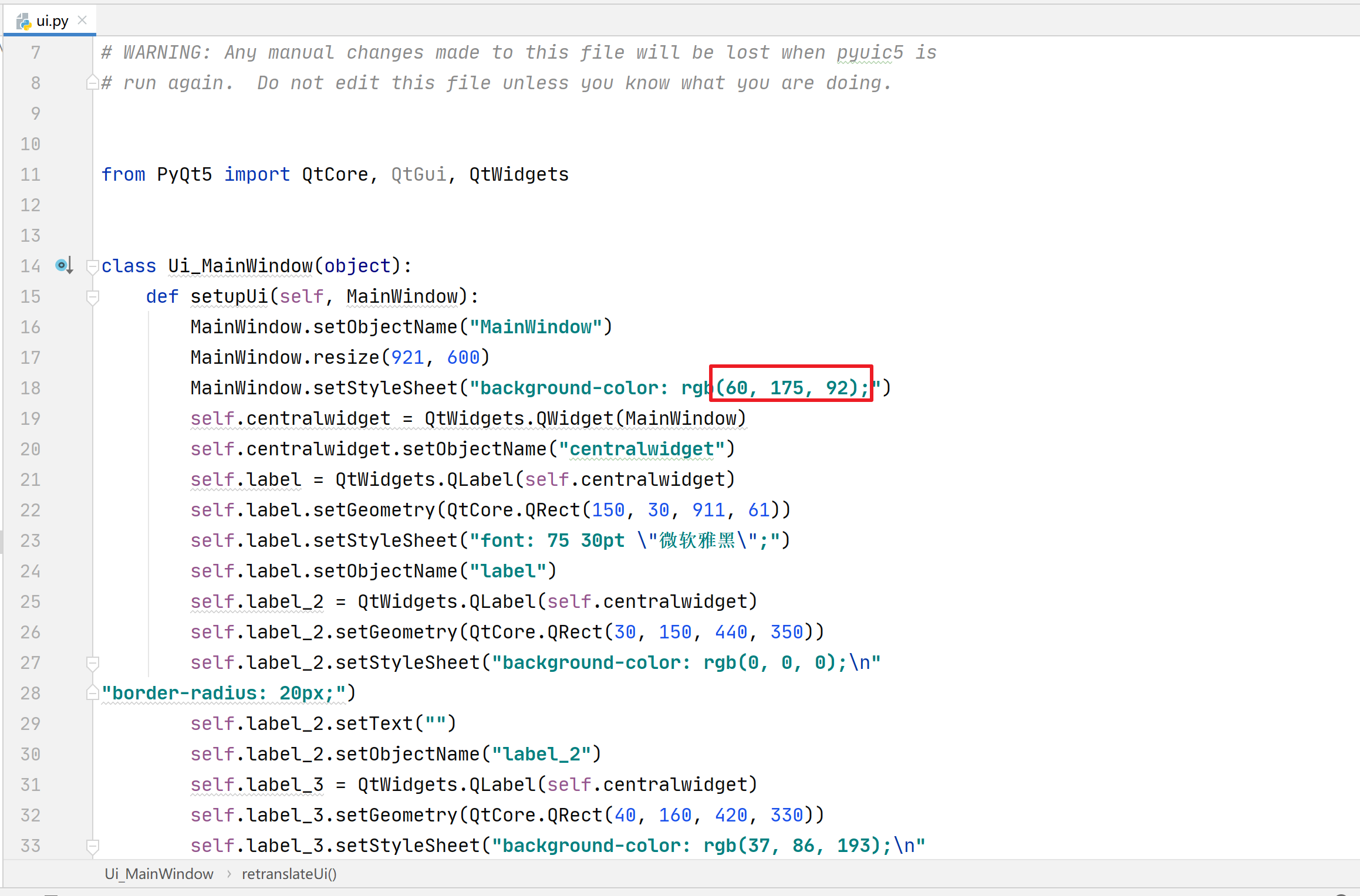
背景修改项目01:
项目01中,运行主界面.py为纯色背景,运行主界面2.py为背景图像界面
如果想要设置界面为纯色背景,则从此颜色对照表中(https://www.kjson.com/files/rgb/)选取自己需要的RGB颜色编码后,打开ui.py,修改对应的RGB颜色值,然后重新运行主界面.py即可:
同样如果想要修改背景图像,首先把ui文件夹中的background.png图像替换为自己想要的背景图像(命名要相同background.png,大小差不多一致),然后重新运行主界面2.py即可:
背景修改项目02:
项目02中运行主界面.py为背景图像界面,如果想要修改背景图像,把ui文件夹中的background.png图像替换为自己想要的背景图像(命名要相同background.png,大小差不多一致),然后重新运行主界面.py即可:
11)系统Pytorch后端模型检测
后端架构:
通过Pytoch框架来完成后端检测模型的调用和推理,Pyqt5库来完成前端界面的显示和与后端的交互功能

应用结构:
主界面.py
- 布局与控件初始化(setupUi)
- 背景图自适应处理
- 模型加载与推理
- 交互信号与业务逻辑
核心功能:
- 文件上传和验证
- 图像预处理
- 模型推理
- 结果格式化
- 结果及相关信息显示
以上11个步骤即为对项目开发流程的详细介绍,使得大家对项目开发流程和项目文件有充分的了解,项目中相关主要代码部分都有对应注释,同时也为大家准备了视频形式的项目讲解说明,结合本文档使用效果更佳哦:
https://www.bilibili.com/video/BV1JRUHYxEJk
七、项目代码文件获取
通过网盘分享的文件:mobile_net_handwrite.zip
链接: https://pan.baidu.com/s/1Ew47lHDz3IcfWT_6xItWbw?pwd=af5n
提取码: af5n
--来自百度网盘超级会员v5的分享


















 6738
6738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









