




 本文详细介绍了Hadoop的HDFS和YARN组件,包括HDFS的三台服务器节点配置、元数据管理、文件读写过程、SNN的合并机制,以及YARN的服务器节点配置、ResourceManager与NodeManager的角色。同时,提到了Hadoop的配置文件作用和安全模式。
本文详细介绍了Hadoop的HDFS和YARN组件,包括HDFS的三台服务器节点配置、元数据管理、文件读写过程、SNN的合并机制,以及YARN的服务器节点配置、ResourceManager与NodeManager的角色。同时,提到了Hadoop的配置文件作用和安全模式。
hdfs
hdfs三台服务器节点配置:

各节点说明:
-
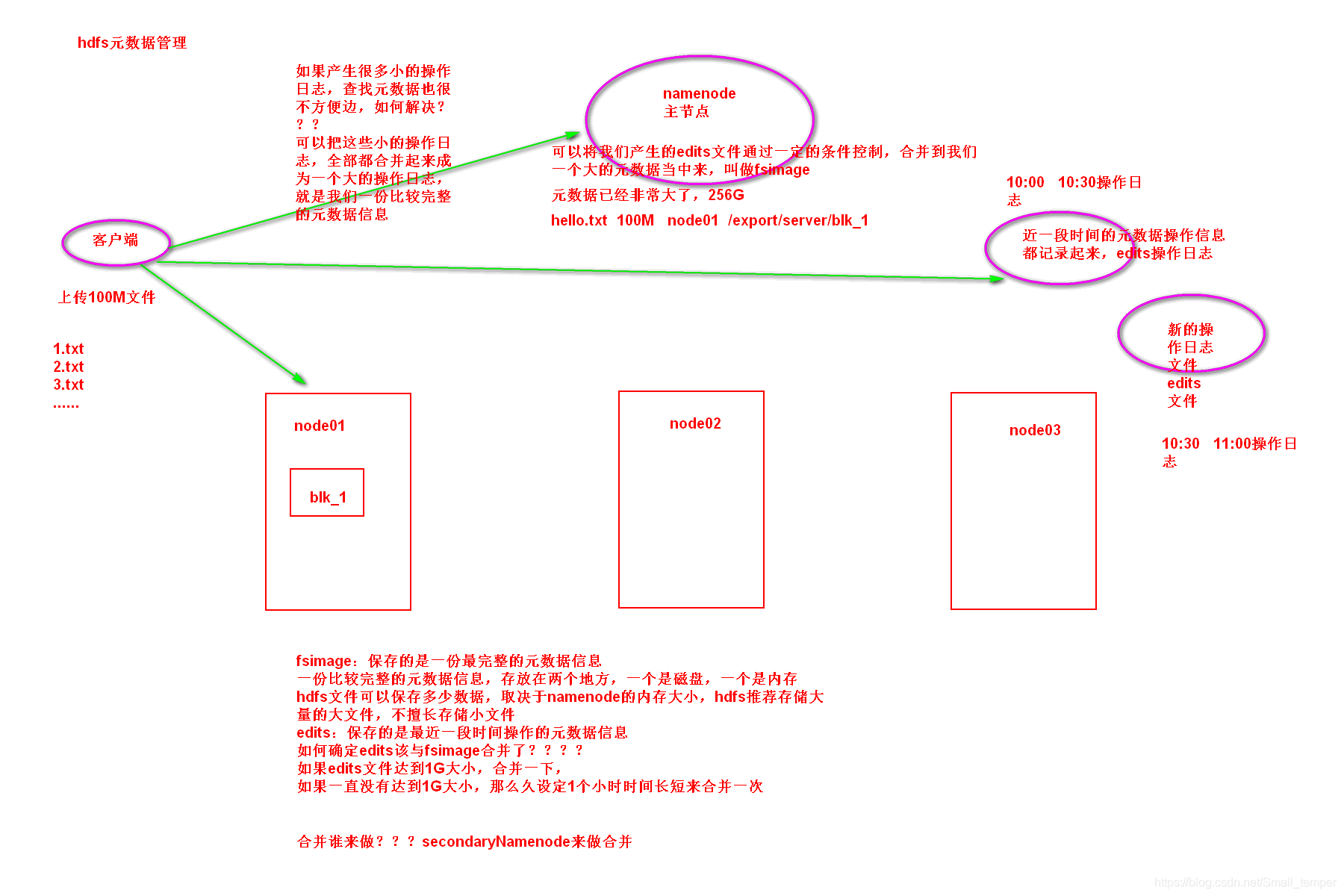
namenode :HDFS的守护进程,负责维护整个文件系统,存储着整个文件系统的元数据信息,有image+edit log ,namenode不会持久化存储这些数据,而是在启动时重建这些数据。
-
datanode:是具体文件系统的工作节点,当我们需要某个数据,namenode告诉我们去哪里找,就直接和那个DataNode对应的服务器的后台进程进行通信,由DataNode进行数据的检索,然后进行具体的读/写操作
-
secondarynamenode :一个冗余的守护进程,相当于一个namenode的元数据的备份机制,定期的更新,和namenode进行通信,将namenode上的image和edits进行合并,可以作为namenode的备份使用
如果namenode是高可用,那么就没有secondaryNamenode了,多了journalnode,并且journalnode最好是奇数个
journalNode:同步元数据信息,保证两个namenode里面的元数据是一模一样的,不然就会出现脑裂
zkfc:zkFailoverController 守护进程,与我们的namenode启动在同一台机器,监听namenode的健康状况
- 元数据信息:描述数据的数据 文件的名称,文件的位置,文件的大小,创建时间,修改时间,权限控制
- datanode数据存储:出磁盘,用于存储我们的文件数据
- 一次写入,多次读取:hdfs文件系统,适用于频繁读取的情况,不适用与频繁写入的情况 改变文件,涉及到元数据的改变
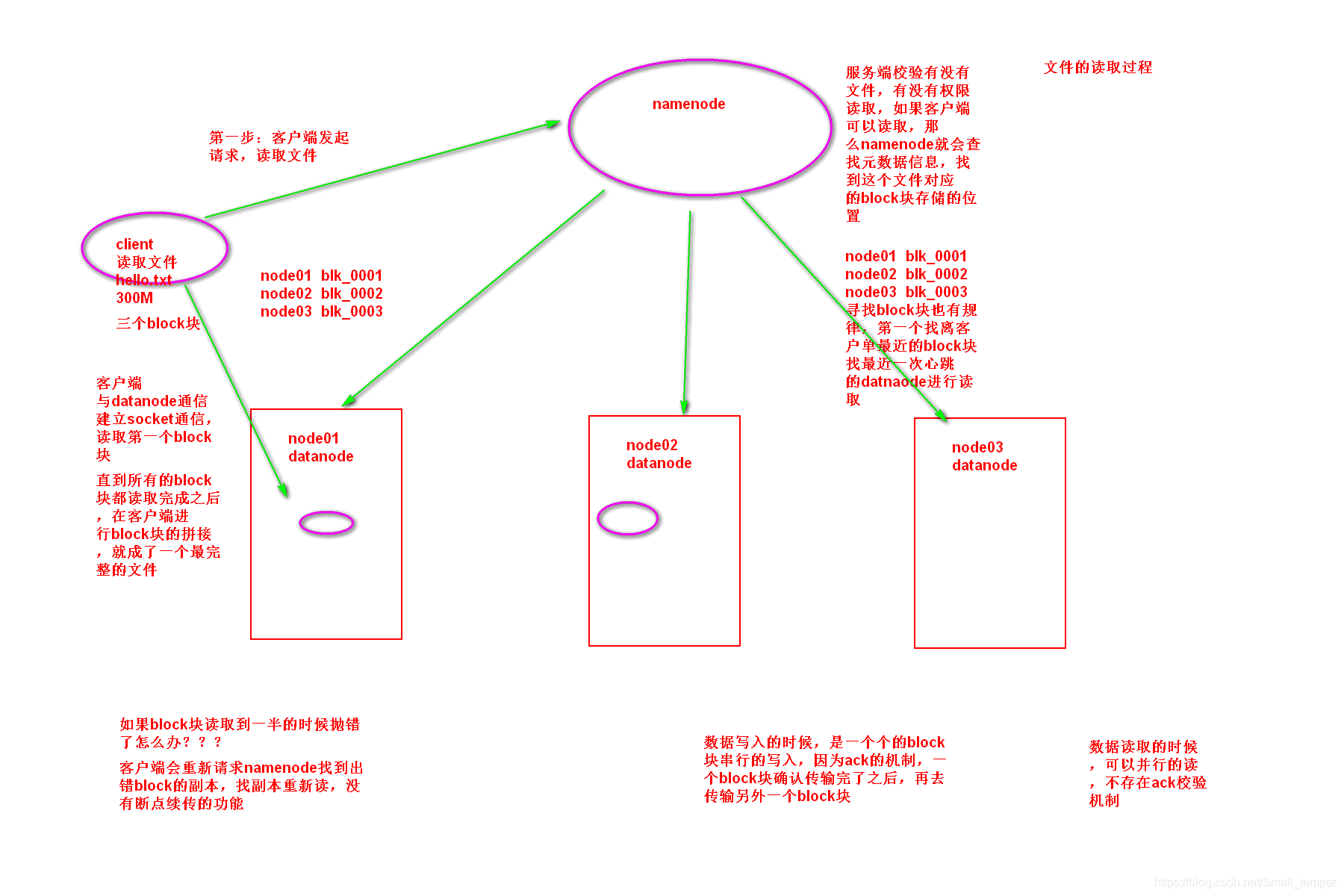
hdfs文件的读取过程:
- 客户端请求namenode读取数据
- namenode校验权限,文件是否存在等等
- namenode返回给客户端一个block块的列表
- 客户端读取block块
- 客户端拼接block块
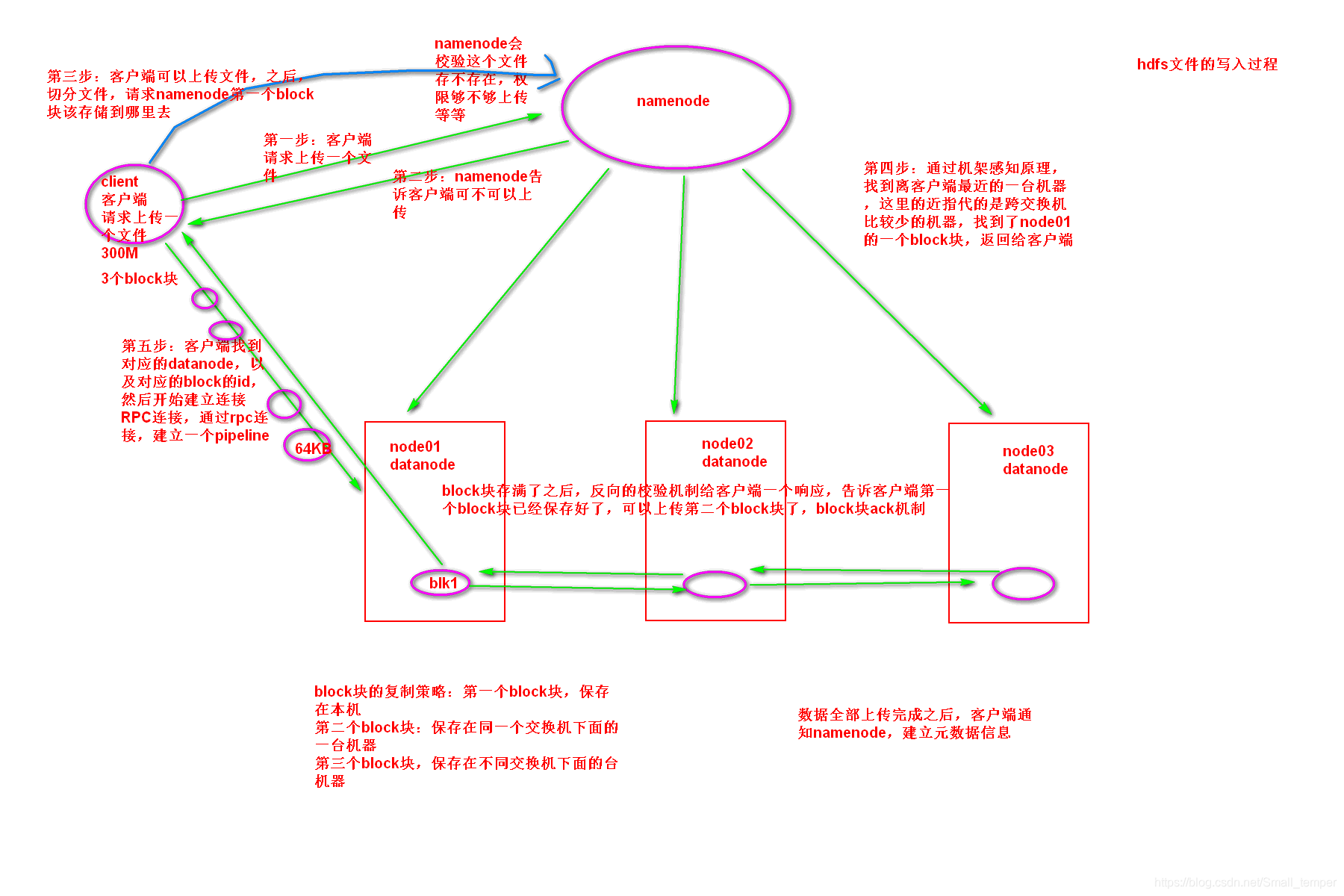
hdfs的文件的写入过程
- 客户端请求namenode上传数据
- namneode校验有没有权限,数据是否存在
- 客户端请求namenode第一个block块的位置
- 客户单与对应的datanode进行通信,建立pipeline管道 ,发送数据包 64KB ,反向的datanode需要校验block块是否上传成功
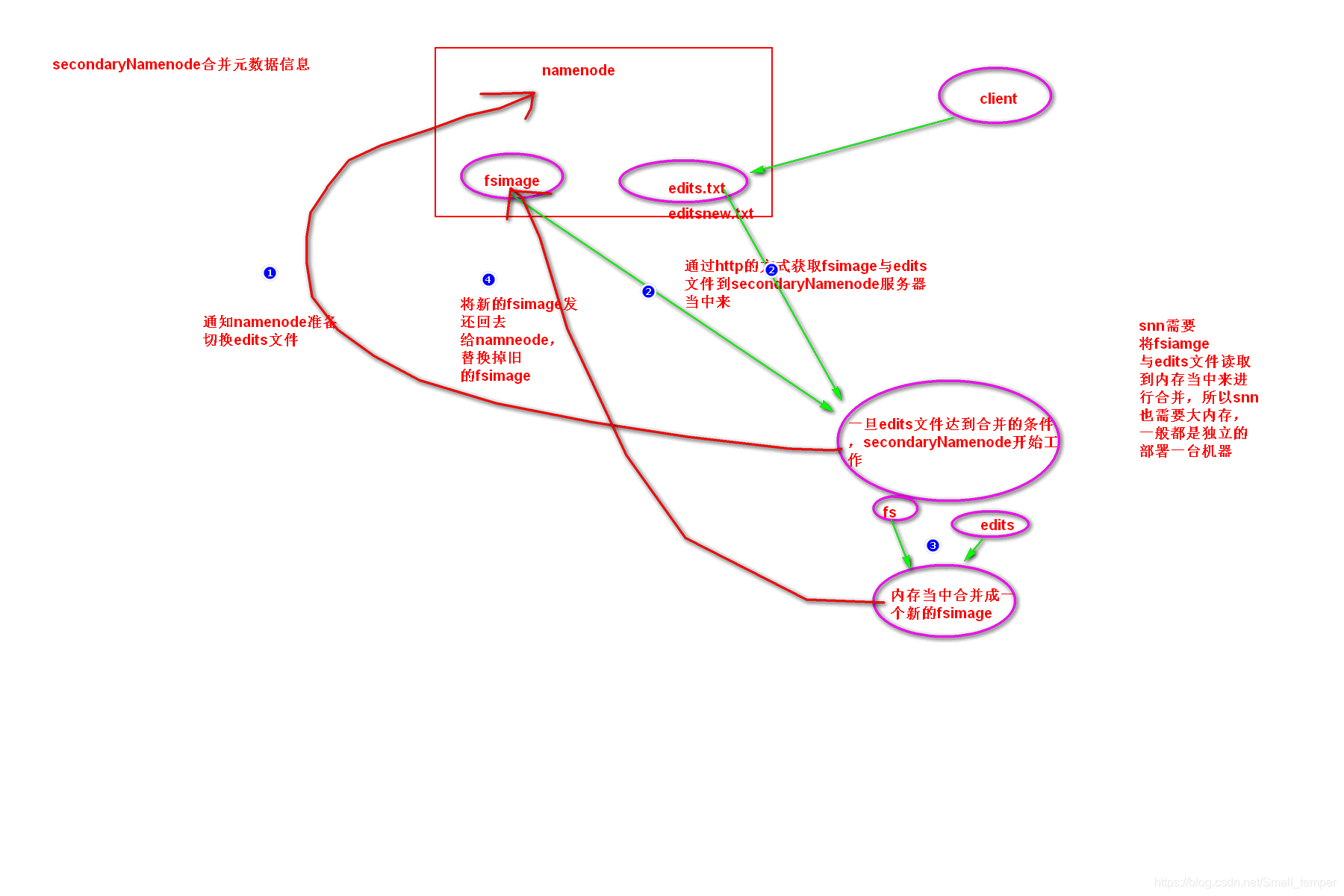
snn如何 合并fsimag与edits
- 通知namenode切换edits文件
- 通过http的方式获取fsimage与edits文件
- 将fsimage与edits文件加载到内存当中合并 snn需要大内存
- 将最新的fsimage发还给namenode,替换掉旧的fsimage
hdfs的架构图
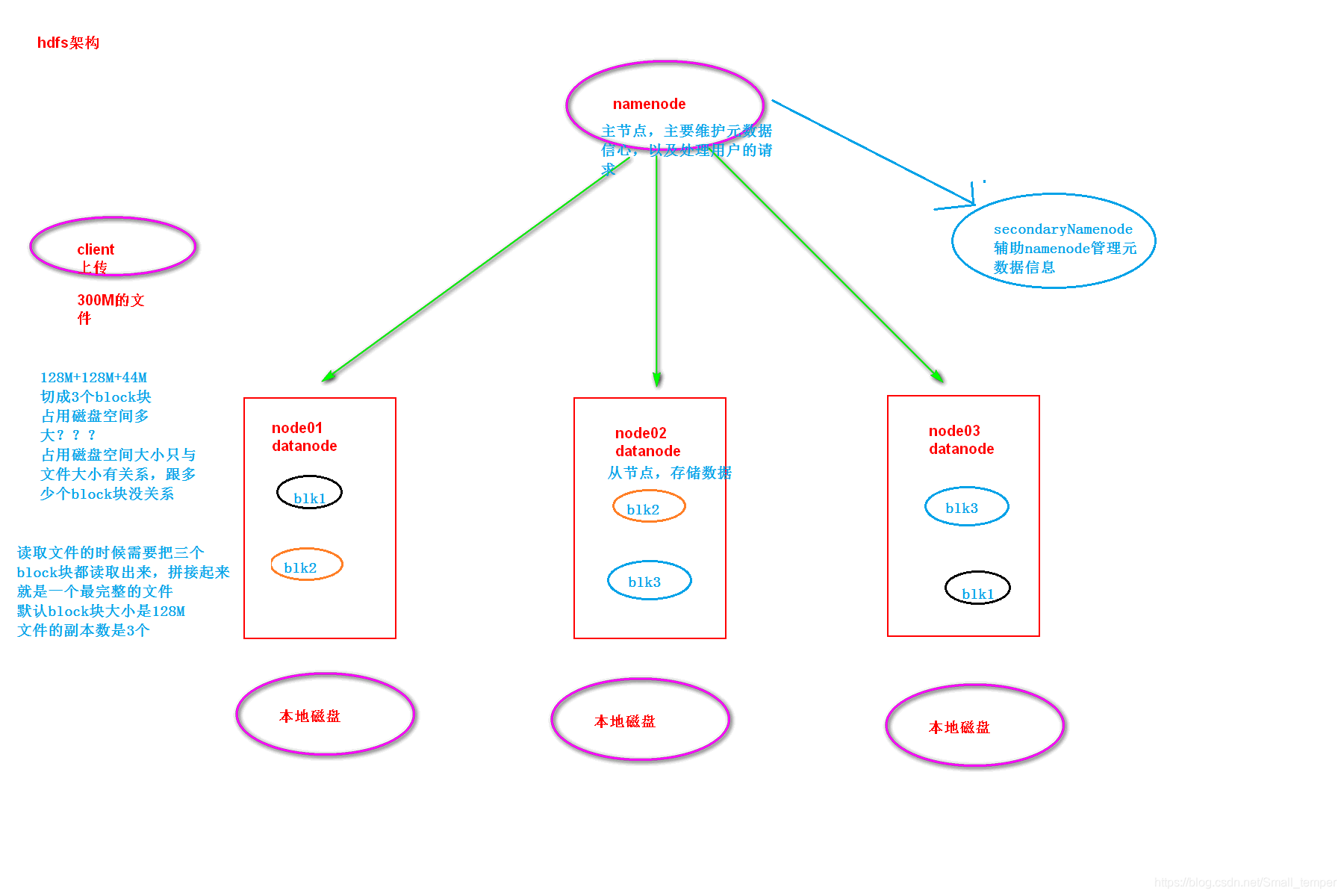
hdfs元数据管理
YARN
yarn三台服务器节点配置:

各节点说明:
- resourcemanager:是yarn平台的守护进程,负责所有资源的分配与调度,client的请求由此负责,监控nodemanager
- nodemanager :是单个节点的资源管理,执行来自resourcemanager的具体任务和命令
hadoop 的六个配置文件的作用
- core-site.xml:核心配置文件,主要定义了我们的集群是分布式,还是本机运行
- hdfs-site.xml: 分布式文件系统的核心配置 决定了我们数据存放在哪个路径,数据的副本,数据的block块大小等等
- hadoop-env.sh 配置我们jdk的home路径
- mapred-site.xml 定义了我们关于mapreduce运行的一些参数
- yarn-site.xml 定义我们的yarn集群
- slaves 定义了我们的从节点是哪些机器 datanode nodemanager运行在哪些机器上
- hadoop 的格式化:只在集群初次启动的时候执行一次
namenode与resourceManager的高可用
- hadoop 2.0版本引入namenode高可用机制
- resourcemanager 2.4.0版本引用高可用机制
hdfs的安全模式:
- 在我们集群刚刚启动的时候,集群是出于安全模式的,对外不提供任何服务,专门干一件事情,集群的自检
- 如果集群自检没有什么问题,那么过三十秒钟,自动脱离安全模式,可以对外提供服务
hadoop的基准测试:
- 集群启动成功之后,第一件事就是做基准测试,说白了就是压测,测试我们的网络带宽,测试我们的文件读取和写入速度等等
- 真实的服务器性能,写入速度大概在20-30M每秒的样子:
真实服务读取速度测试:50-100M左右的样子
实际线上环境该如何压测: 写入10G 100G文件 500G文件 1T文件
MR
mapreduce编程可控的八个步骤
天龙八部:
map阶段两个步骤
1、第一步:读取文件,解析成key,value对,这里是我们的K1 V1
2、第二步:接收我们的k1 v1,自定义我们的map逻辑,然后转换成新的key2 value2 进行输出 往下发送 这里发送出去的是我们k2 v2
shuffle阶段四个步骤
3、第三步:分区 相同key的value发送到同一个reduce里面去,key合并,value形成一个集合
4、第四步:排序 默认按照字段顺序进行排序
5、第五步:规约
6、第六步:分组
reduce阶段两个步骤
7、接收我们的k2 v2 自定义我们的reduce逻辑,转换成新的k3 v3 进行输出
8、将我们的K3 v3 进行输出
单词统计,现在要统计,每一个单词在文本当中出现了多少次
hello world
hadoop hive
sqoop hive
hadoop hive
第一步:读取文件,解析成key,value对 key是我们的行偏移量 value是我们行文本内容
下一行是上一行的行偏移量
key1 value1
0 hello world
11 hadoop hive
22 sqoop hive
第二步:自定义map逻辑,接收我们的key1,value2 转换成新的key2 value2进行输出
获取我们的value1 ,按照空格进行切割 [hello,world] [hadoop ,hive] [sqoop,hive]
hello world
hadoop hive
sqoop hive
转换成新的key2 value2 往下发送
key2 value2
hello 1
world 1
hadoop 1
hive 1
sqoop 1
hive 1
第三步:分区 相同key的value发送到同一个reduce当中去,key进行合并,value形成一个集合
hive [1,1]
第四步:排序
第五步:规约
第六步:分组
第七步:reduce阶段,接收我们的key2 value2 转换成新的key3 value3进行输出
接收 key2 value2
hive 1
hive 1
key2 value2已经变成了一个集合
hive [1,1]
转换成新的key3 value3
hive 1+1 = 2
第八步:输出我们的key3 value3
hive 2
sqoop 1
hello 1
world 1
hadoop 1

















 2837
2837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









