






目录
Python对CMIP6数据进行插值
写在前面—为什么要写这篇博客?
小编最近接触到一个气候方面的项目,然后需要利用到CMIP6数据,需要对其进行数据插值,小编也是第一次接触这个数据,所以就想着学习一下如何利用Python对数据进行插值。在对数据插值之前,我们首先要了解一下我们的数据是什么样子的,也就是对CMIP6数据以及nc文件有个简单的了解。对源数据有个
简单了解之后,我们就可以选择合适的方法对数据进行插值。
一、引言
在气候科学和地球数据分析中,数据插值是一项基础且关键的任务。由于不同模型或观测数据的空间分辨率、层次结构存在差异,将数据统一到标准网格是后续分析的前提。本文结合一个实际的气候数据处理项目,详细介绍如何利用Python实现数据插值。
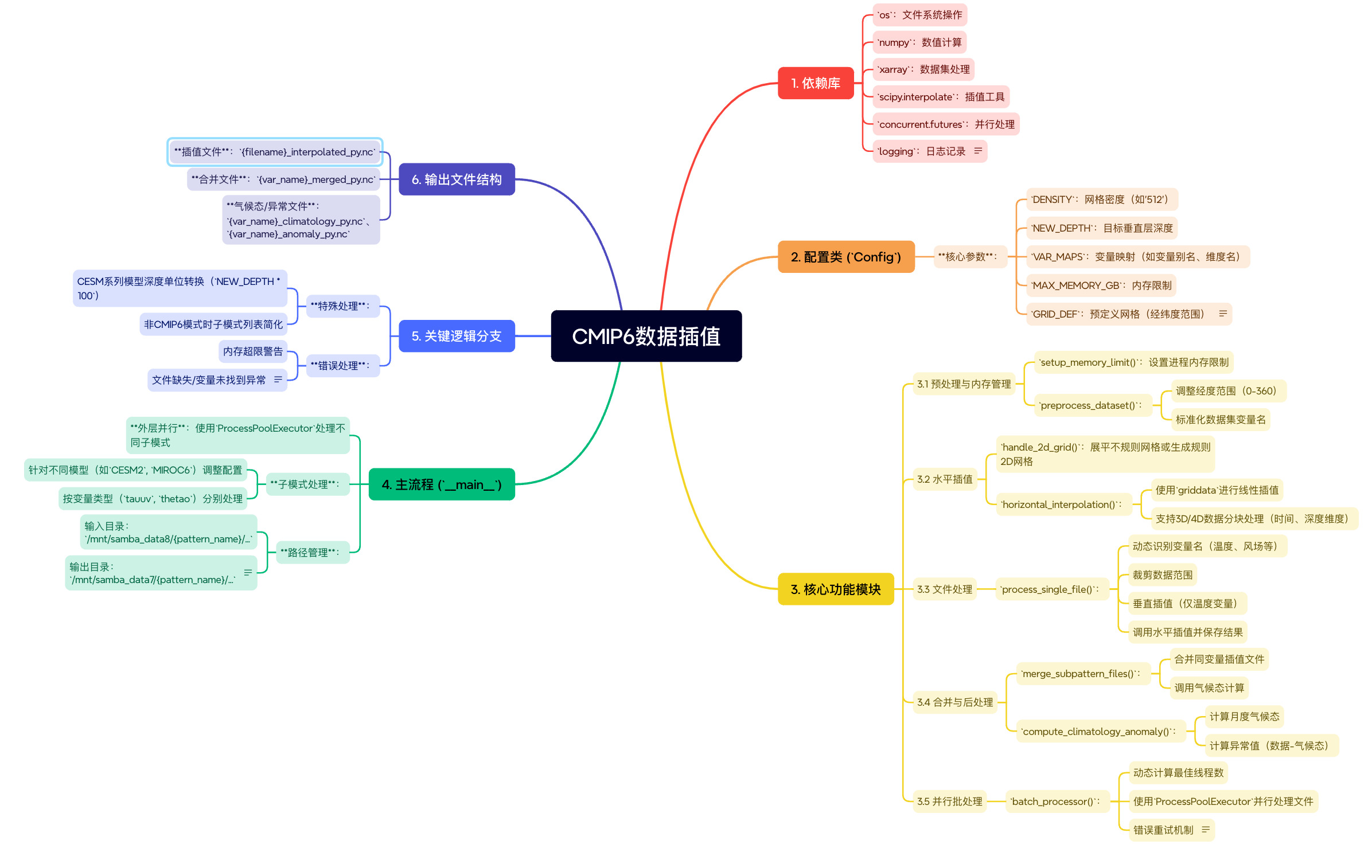
代码概览
代码主要功能包括:
- 数据预处理:调整经度范围、识别关键变量。
- 数据区域裁剪: 裁剪目标区域的数据。
- 垂直插值:将数据插值到指定深度层次。
- 水平插值:将数据映射到规则网格。
- 多线程处理:加速大规模文件处理。
- 文件合并与气候态计算:生成时间序列完整的数据集及异常分析。
思维导图
二、数据预处理
要想做好数据预处理,首先就要先了解CMIP6数据以及NC文件,关于CMIP6数据以及NC文件的的介绍可以参考:
原始数据可能包含不规则网格或非标准变量名,预处理阶段需解决以下问题:
- 变量识别:不同的模式可能有不同的变量名,因此我们在处理数据之前,首先要识别变量名称。本次数据处理用的变量名称主要有
thetao,lon,lat,time,level; 因此我们首先根据先验知识定义了一个变量别名表,如下所示:
VAR_MAPS = {
'thetao': ['votemper', 'thetao', 'pottmp', 'TEMP'],
'tauu': ['tauu', 'sozotaux', 'uflx', 'TAUX'],
'tauv': ['tauv', 'sometauy', 'vflx', 'TAUY'],
'lon': ['lon', 'longitude', 'nav_lon', 'LONN359_360'],
'lat': ['lat', 'latitude', 'nav_lat', 'LAT'],
'lev': ['lev', 'depth', 'deptht', 'level', 'olevel', 'LEV1_13'],
'time': ['time', 'TIME', 'time_counter'],
}
- 查找变量:根据预定义的变量别名表(如
thetao可能对应votemper、TEMP等),动态匹配数据中的变量名。
keys = list(ds.variables.keys())
# 示例:动态识别变量名
var = next((v for v in keys if v in config.VAR_MAPS['var']), None)
lon_var = next((v for v in keys if v in config.VAR_MAPS['lon']), None)
lat_var = next((v for v in keys if v in config.VAR_MAPS['lat']), None)
time_var = next((v for v in keys if v in config.VAR_MAPS['time']), None)
lev_var = next((v for v in keys if v in config.VAR_MAPS['lev']), None)
- 经度标准化:将经度范围从[-180°, 180°]转换为[0°, 360°],避免插值时的边界问题。
if lon_var and ds[lon_var].min() < 0:
ds[lon_var] = xr.where(ds[lon_var] < 0, ds[lon_var] + 360, ds[lon_var])
三、数据区域裁剪
我们在插值的时候可能并不需要全球的区域,所以我们可以进行区域裁剪来降低计算量,具体实现如下:
lon_mask = (ds[lon_var] >= config.LON_RANGE.start) & (ds[lon_var] <= config.LON_RANGE.stop)
lat_mask = (ds[lat_var] >= config.LAT_RANGE.start) & (ds[lat_var] <= config.LAT_RANGE.stop)
mask = (lon_mask & lat_mask).compute() # 显式计算布尔掩码
ds_cropped = ds.where(mask, drop=True)
四、插值
(一) 垂直插值
利用xarray的interp方法,将数据插值到预设深度(如5m、20m等):
ds_vert = ds.interp({lev_var: config.NEW_DEPTH}, method='linear')
(二) 水平插值
使用scipy.interpolate.griddata实现二维网格插值,支持不规则网格数据:
- 输入:原始经纬度(展平为1D数组)及对应的变量值。 由于不同的模式经纬度的构造方式可能不一致,所以在正式插值之前要先把原始数据的经纬度进行预处理,具体如下:
def handle_2d_grid(lon: np.ndarray, lat: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""处理不规则网格展平(兼容2D非正交网格)"""
if len(lon.shape) > 1:
lon = lon.flatten()
lat = lat.flatten()
else:
lat_2d, lon_2d = np.meshgrid(lat, lon, indexing='ij')
lon, lat = lon_2d.flatten(), lat_2d.flatten()
return lon, lat
- 目标网格:根据配置生成规则网格(如180*360)。 具体如下:
target_lon = config.GRID_DEF[config.DENSITY]['lon']
target_lat = config.GRID_DEF[config.DENSITY]['lat']
grid_lon, grid_lat = np.meshgrid(target_lon, target_lat)
- 插值方法:采用线性插值。
new_data = griddata((src_lon, src_lat), current_data.flatten(), (grid_lon, grid_lat), method='linear')
五、保存插值好的文件
保存为netcdf文件,具体代码如下:
coords = {
'time': ds[time_var].values,
'lev': config.NEW_DEPTH,
'lat': config.GRID_DEF[config.DENSITY]['lat'],
'lon': config.GRID_DEF[config.DENSITY]['lon'],
}
dims = ['time', 'lev', 'lat', 'lon']
output_ds = xr.Dataset(
{var: (dims, interp_data)},
coords=coords
)
# 保存文件 ----------------------------------------------------------
output_path = os.path.join(output_dir, f"{os.path.splitext(file_name)[0]}{config.INTER_NAME}{config.SUFFIX}.nc")
output_ds.to_netcdf(output_path)
output_ds.close() # 显式关闭输出数据集
六、文件合并与气候态计算
- 文件合并:将插值后的文件按时间维度拼接,生成完整数据集并保存。
datasets = [xr.open_dataset(file) for file in filtered_files]
combined_ds = xr.concat(datasets, dim='time').sortby('time')
# 保存合并文件
merged_path = os.path.join(merged_output_dir, f"{var_name}{config.MERGE_NAME}{config.SUFFIX}.nc")
combined_ds.to_netcdf(merged_path)
combined_ds.close()
- 气候态计算:选定起止时间,按月计算多年平均气候态,并生成异常数据(实际值减气候态)。
# 选择指定时间范围内的数据
ds = ds.sel(time=slice(start_date, end_date))
# 计算气候态(按月平均)
climatology = ds.groupby('time.month').mean(dim='time')
# 计算异常
anomaly = ds.groupby('time.month') - climatology
# 保存结果
climatology_path = os.path.join(output_dir, f"{var_name}{config.CLIMA_NAME}{config.SUFFIX}.nc")
anomaly_path = os.path.join(output_dir, f"{var_name}{config.ANOMALY_NAME}{config.SUFFIX}.nc")
climatology.to_netcdf(climatology_path)
anomaly.to_netcdf(anomaly_path)
七、代码优化技巧
- 内存优化:分块读取数据(
xarray的chunks参数)减少内存占用。
with xr.open_dataset(file_path, chunks={'time': 1}) as ds:
- 异常处理:捕获并记录处理失败的文件,支持重试机制。
- 日志记录:通过
logging模块记录运行状态,便于调试。
八、多线程处理
通过concurrent.futures.ProcessPoolExecutor实现多进程并行处理,显著提升大量文件的处理效率:
- 动态线程数:根据CPU核心数、内存限制和文件数量自动调整线程数。
- 内存管理:使用
resource模块限制进程内存,避免系统崩溃。
# 设置内存限制(单位:GB)
resource.setrlimit(resource.RLIMIT_AS, (config.MAX_MEMORY_GB * 1024**3,))
九、全部代码
import os
import time
import logging
import numpy as np
import xarray as xr
from scipy.interpolate import griddata
from scipy.interpolate import NearestNDInterpolator
# from xesmf import Regridder
import concurrent.futures
import sys
import warnings
from typing import List, Tuple, Dict
import resource
from concurrent.futures import ProcessPoolExecutor
import logging
import sys
# 配置日志记录
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s',
handlers=[
logging.FileHandler("data_inter.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
# 配置参数(可抽离为单独配置文件)
class Config:
"""全局配置参数类"""
DENSITY = '512'
NEW_DEPTH = np.array([5.0, 20.0, 40.0, 60.0, 90.0, 120.0, 150.0])
# NEW_DEPTH = np.array([5.0, 20.0])
VAR_MAPS = {
'var': ['votemper', 'thetao', 'pottmp', 'TEMP', 'tauu', 'sozotaux', 'uflx', 'TAUX', 'tauv', 'sometauy', 'vflx', 'TAUY'],
'thetao': ['votemper', 'thetao', 'pottmp', 'TEMP'],
'tauu': ['tauu', 'sozotaux', 'uflx', 'TAUX'],
'tauv': ['tauv', 'sometauy', 'vflx', 'TAUY'],
'lon': ['lon', 'longitude', 'nav_lon', 'LONN359_360'],
'lat': ['lat', 'latitude', 'nav_lat', 'LAT'],
'lev': ['lev', 'depth', 'deptht', 'level', 'olevel', 'LEV1_13'],
'time': ['time', 'TIME', 'time_counter'],
'start_dates': {'ORAS5': '1958-01-01',
'CMIP6': '1850-01-01',
'GODAS': '1980-01-01',
'SODA': '1871-01-01', },
'end_dates': {'ORAS5': '1979-12-31',
'CMIP6': '2014-12-31',
'GODAS': '2021-12-31',
'SODA': '1979-12-31'}
}
MAX_MEMORY_GB = 1024 # 最大内存限制
SUFFIX = '_py'
INTER_NAME = '_interpolated'
MERGE_NAME = '_merged'
ANOMALY_NAME = '_anomaly'
CLIMA_NAME = '_climatology'
# 定义经度和纬度范围
LON_RANGE = slice(0, 360) # 经度范围
LAT_RANGE = slice(-90, 90) # 纬度范围
start = LAT_RANGE.start
end = LAT_RANGE.stop
num = end-5
GRID_DEF = {
'512': {
'lon': np.linspace(0, 360, 180),
'lat': np.concatenate((
np.linspace(start, -6, num),
np.linspace(-5, 5, 21),
np.linspace(6, end, num)
))
},
'25': {
'lon': np.linspace(0, 360, 144),
'lat': np.linspace(-90, 90, 72),
},
'55': {
'lon': np.linspace(0, 360, 72),
'lat': np.linspace(-90, 90, 36),
},
'11': {
'lon': np.linspace(0, 360, 360),
'lat': np.linspace(-90, 90, 180),
},
}
warnings.filterwarnings('ignore')
def handle_2d_grid(lon: np.ndarray, lat: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
"""处理不规则网格展平(兼容2D非正交网格)"""
if len(lon.shape) > 1:
lon = lon.flatten()
lat = lat.flatten()
else:
lat_2d, lon_2d = np.meshgrid(lat, lon, indexing='ij')
lon, lat = lon_2d.flatten(), lat_2d.flatten()
return lon, lat
def setup_memory_limit(config: Config):
"""设置进程内存限制"""
try:
mem_limit = config.MAX_MEMORY_GB * 1024 ** 3
resource.setrlimit(
resource.RLIMIT_AS,
(mem_limit, mem_limit)
)
logger.info(f"内存限制设置为 {config.MAX_MEMORY_GB}GB")
except ValueError as e:
logger.warning(f"内存限制设置失败: {str(e)}")
def preprocess_dataset(ds: xr.Dataset, config: Config) -> xr.Dataset:
"""跳过坐标重命名,仅处理经度范围"""
print("开始进行数据预处理...")
try:
# 直接查找原始经度变量并标准化范围
keys = list(ds.variables.keys())
lon_var = next((v for v in keys if v in config.VAR_MAPS['lon']), None)
if lon_var and ds[lon_var].min() < 0:
ds[lon_var] = xr.where(ds[lon_var] < 0, ds[lon_var] + 360, ds[lon_var])
print("数据预处理完成。")
return ds
except Exception as e:
logger.error(f"预处理失败: {str(e)}")
raise
def merge_subpattern_files(sub_pattern_dir: str, merged_output_dir: str, var_name: str, config: Config) -> None:
"""合并指定目录下所有包含特定变量的 *_interp.nc 文件"""
# 获取所有待合并文件
files = [
os.path.join(sub_pattern_dir, f)
for f in sorted(os.listdir(sub_pattern_dir))
if f.endswith(f'{config.INTER_NAME}{config.SUFFIX}.nc')
]
if not files:
raise FileNotFoundError(f"无待合并文件于目录: {sub_pattern_dir}")
# 筛选包含目标变量的文件
filtered_files = []
for file in files:
with xr.open_dataset(file) as ds:
if var_name in list(ds.variables.keys()):
filtered_files.append(file)
if not filtered_files:
raise ValueError(f"目录 {sub_pattern_dir} 中无 {var_name} 变量文件")
# 合并文件
datasets = [xr.open_dataset(file) for file in filtered_files]
combined_ds = xr.concat(datasets, dim='time').sortby('time')
# 保存合并文件
merged_path = os.path.join(merged_output_dir, f"{var_name}{config.MERGE_NAME}{config.SUFFIX}.nc")
combined_ds.to_netcdf(merged_path)
combined_ds.close()
print(f"{var_name} 合并完毕,保存至: {merged_path}")
compute_climatology_anomaly(merged_path, merged_output_dir, var_name, config)
def compute_climatology_anomaly(merged_path: str, output_dir: str, var_name: str, config: Config) -> None:
"""计算气候态和异常"""
with xr.open_dataset(merged_path) as ds:
start_date, end_date = config.VAR_MAPS['start_dates'][pattern_name], config.VAR_MAPS['end_dates'][pattern_name]
ds = ds.sortby('time')
# 选择指定时间范围内的数据
ds = ds.sel(time=slice(start_date, end_date))
# 计算气候态(按月平均)
climatology = ds.groupby('time.month').mean(dim='time')
# 计算异常
anomaly = ds.groupby('time.month') - climatology
# 保存结果
climatology_path = os.path.join(output_dir, f"{var_name}{config.CLIMA_NAME}{config.SUFFIX}.nc")
anomaly_path = os.path.join(output_dir, f"{var_name}{config.ANOMALY_NAME}{config.SUFFIX}.nc")
climatology.to_netcdf(climatology_path)
anomaly.to_netcdf(anomaly_path)
def horizontal_interpolation(data: np.ndarray, src_lon: np.ndarray,
src_lat: np.ndarray, config: Config) -> np.ndarray:
"""支持三维和四维数据的水平插值"""
target_lon = config.GRID_DEF[config.DENSITY]['lon']
target_lat = config.GRID_DEF[config.DENSITY]['lat']
grid_lon, grid_lat = np.meshgrid(target_lon, target_lat)
print("src_lon:", src_lon.shape, "src_lat:", src_lat.shape)
print("开始水平插值...")
final_data = []
for time_idx in range(data.shape[0]):
print(f"处理时间步 {time_idx + 1}/{data.shape[0]}")
if data.ndim == 4:
# 温度数据分块处理
lev_data = []
for depth_idx in range(data.shape[1]):
current_data = data[time_idx, depth_idx, ...].flatten()
new_data = griddata((src_lon, src_lat),
current_data,
(grid_lon, grid_lat),
method='linear')
lev_data.append(new_data)
print(config.var_type, config.pattern_name, config.sub_pattern_name, time_idx, depth_idx, new_data.shape, np.nanmin(new_data), np.nanmax(new_data))
print()
final_data.append(lev_data)
else:
# 处理风数据
current_data = data[time_idx, ...].flatten()
new_data = griddata((src_lon, src_lat),
current_data,
(grid_lon, grid_lat),
method='linear')
print(config.var_type, config.pattern_name, config.sub_pattern_name, time_idx, new_data.shape, np.nanmin(new_data), np.nanmax(new_data))
print()
final_data.append(new_data)
final_data = np.array(final_data)
return final_data
def process_single_file(file_info: Tuple[str, str, str, str, Config]) -> bool:
"""直接通过原始变量名提取数据"""
file_name, input_dir, output_dir, pattern, config = file_info
file_path = os.path.join(input_dir, file_name)
try:
with xr.open_dataset(file_path, chunks={'time': 1}) as ds:
# ds = preprocess_dataset(ds)
print(ds)
keys = list(ds.variables.keys())
print(keys)
# 动态识别原始变量名 -------------------------------------------------
# 1. 查找目标变量
var = next((v for v in keys if v in config.VAR_MAPS['var']), None)
if not var:
raise ValueError("未找到温度变量(thetao)")
is_temp_var = var in config.VAR_MAPS['thetao']
# 2. 查找经纬度变量
lon_var = next((v for v in keys if v in config.VAR_MAPS['lon']), None)
if lon_var and ds[lon_var].min() < 0:
ds[lon_var] = xr.where(ds[lon_var] < 0, ds[lon_var] + 360, ds[lon_var])
lat_var = next((v for v in keys if v in config.VAR_MAPS['lat']), None)
time_var = next((v for v in keys if v in config.VAR_MAPS['time']), None)
# 4. 查找垂直层变量
if is_temp_var:
lev_var = next((v for v in keys if v in config.VAR_MAPS['lev']), None)
if not lev_var:
raise ValueError("缺失垂直维度")
ds_vert = ds.interp(
{lev_var: config.NEW_DEPTH},
method='linear',
kwargs={'fill_value': 'extrapolate'}
)
else:
ds_vert = ds
ds = ds_vert
# 3. 裁剪数据
lon_mask = (ds[lon_var] >= config.LON_RANGE.start) & (ds[lon_var] <= config.LON_RANGE.stop)
lat_mask = (ds[lat_var] >= config.LAT_RANGE.start) & (ds[lat_var] <= config.LAT_RANGE.stop)
mask = (lon_mask & lat_mask).compute() # 显式计算布尔掩码
ds_cropped = ds.where(mask, drop=True)
ds_vert = ds_cropped
# 5. 水平插值(使用原始经纬度)
src_lon = ds_vert[lon_var].values
src_lat = ds_vert[lat_var].values
data = ds_vert[var].values
src_lon, src_lat = handle_2d_grid(src_lon, src_lat)
print("ds_vert:", data.shape)
interp_data = horizontal_interpolation(data, src_lon, src_lat, config)
print(type(interp_data), type(ds_vert))
# 构建动态输出数据集
if is_temp_var:
coords = {
'time': ds[time_var].values,
'lev': config.NEW_DEPTH,
'lat': config.GRID_DEF[config.DENSITY]['lat'],
'lon': config.GRID_DEF[config.DENSITY]['lon'],
}
dims = ['time', 'lev', 'lat', 'lon']
else:
coords = {
'time': ds[time_var].values,
'lat': config.GRID_DEF[config.DENSITY]['lat'],
'lon': config.GRID_DEF[config.DENSITY]['lon'],
}
dims = ['time', 'lat', 'lon']
output_ds = xr.Dataset(
{var: (dims, interp_data)},
coords=coords
)
# 保存文件 ----------------------------------------------------------
output_path = os.path.join(output_dir, f"{os.path.splitext(file_name)[0]}{config.INTER_NAME}{config.SUFFIX}.nc")
output_ds.to_netcdf(output_path)
output_ds.close() # 显式关闭输出数据集
del ds, output_ds # 主动释放内存
return True
except Exception as e:
logger.error(f"处理失败 {file_path}: {str(e)}", exc_info=True)
return False
def batch_processor(input_dir: str, merged_dir: str, output_dir: str,
pattern: str, max_workers: int, config: Config) -> None:
"""安全批处理控制器"""
setup_memory_limit(config)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"输出目录 {output_dir} 不存在,已创建。")
if not os.path.exists(merged_dir):
os.makedirs(merged_dir)
print(f"合并目录 {merged_dir} 不存在,已创建。")
files = [ f
for f in sorted(os.listdir(input_dir))
if f.endswith('.nc') and not f.startswith('._')
]
ds0 = xr.open_dataset(os.path.join(input_dir, files[0]), chunks={'time': 1})
ds1 = xr.open_dataset(os.path.join(input_dir, files[-1]), chunks={'time': 1})
keys0 = list(ds0.variables.keys())
keys1 = list(ds1.variables.keys())
var_name0 = next((v for v in keys0 if v in config.VAR_MAPS['var']), None)
var_name1 = next((v for v in keys1 if v in config.VAR_MAPS['var']), None)
total_files = len(files)
print(f"发现 {total_files} 个待处理文件。")
# 自动计算最佳线程数
cpu_count = os.cpu_count() or 1
safe_workers = min(
cpu_count * 2, # 超线程优化
max_workers or 64, # 默认上限64
len(files),
(config.MAX_MEMORY_GB * 1024) // 2 # 每个进程约2GB内存
)
print(f"使用 {safe_workers} 个工作线程。")
# 使用进程池+重试机制
with concurrent.futures.ProcessPoolExecutor(max_workers=safe_workers) as executor:
futures = {executor.submit(process_single_file, (f, input_dir, output_dir, pattern, config)): f for f in files}
completed_files = 0
for future in concurrent.futures.as_completed(futures):
completed_files += 1
print(f"已完成 {completed_files}/{total_files} 个文件的处理。")
file_path = futures[future]
try:
result = future.result()
if not result:
logger.warning(f"需重试文件: {file_path}")
# 加入重试队列
except Exception as e:
logger.error(f"执行异常: {file_path} - {str(e)}")
print("主处理流程完成,开始合并文件...")
try:
merge_subpattern_files(output_dir, merged_dir, var_name0, config)
if var_name1 != var_name0:
merge_subpattern_files(output_dir, merged_dir, var_name1, config)
except Exception as e:
logger.error(f"合并失败: {str(e)}", exc_info=True)
if __name__ == "__main__":
# 配置日志记录(确保多进程安全)
logger = logging.getLogger(__name__)
def process_subpattern(var_type: str, sub_pattern_name: str, pattern_name: str) -> None:
"""处理单个子模式的独立函数(每个进程独立配置)"""
local_config = Config()
local_config.DENSITY = '512'
local_config.sub_pattern_name = sub_pattern_name
local_config.var_type = var_type
local_config.pattern_name = pattern_name
# CESM系列需要特殊处理深度(不影响其他进程)
if sub_pattern_name in ['CESM2', 'CESM2-WACCM']:
local_config.NEW_DEPTH = local_config.NEW_DEPTH * 100
try:
batch_processor(
input_dir=f"/mnt/samba_data8/{pattern_name}/{pattern_name}_{var_type}/{sub_pattern_name}",
output_dir=f"/mnt/samba_data7/{pattern_name}/{local_config.DENSITY}{local_config.INTER_NAME}/{var_type}/{sub_pattern_name}",
merged_dir=f"/mnt/samba_data7/{pattern_name}/{local_config.DENSITY}{local_config.MERGE_NAME}/{var_type}/{sub_pattern_name}",
pattern=pattern_name,
max_workers=4, # 调整内层并行度
config=local_config
)
except Exception as e:
logger.error(f"处理失败 {sub_pattern_name}/{var_type}: {str(e)}", exc_info=True)
raise
# 原始配置
sub_pattern_names = [
'ACCESS-CM2', 'ACCESS-ESM1-5', 'BCC-CSM2-MR', 'CAMS-CSM1-0', 'CanESM5-1',
'CMCC-CM2-SR5', 'E3SM-1-1', 'EC-Earth3', 'EC-Earth3-CC', 'FGOALS-f3-L',
'FGOALS-g3', 'FIO-ESM-2-0', 'INM-CM4-8', 'INM-CM5-0', 'NorESM2-LM',
'CESM2-WACCM-FV2', 'CNRM-ESM2-1', 'GISS-E2-1-G', 'CMCC-ESM2', 'EC-Earth3-Veg',
'NESM3', 'EC-Earth3-Veg-LR', 'CAS-ESM2-0', 'CanESM5', 'CIESM', 'GFDL-CM4',
'GFDL-ESM4', 'NorESM2-MM', 'CNRM-CM6-1', 'MCM-UA-1-0', 'MPI-ESM1-2-HR',
'MPI-ESM1-2-LR', 'CanESM5-CanOE', 'SAM0-UNICON', 'E3SM-1-0', 'HadGEM3-GC31-LL',
'UKESM1-0-LL', 'IPSL-CM6A-LR', 'KIOST-ESM', 'HadGEM3-GC31-MM', 'MRI-ESM2-0',
'MIROC6', 'MIROC-ES2L', 'CESM2', 'CESM2-WACCM'
]
pattern_name = 'CMIP6'
if pattern_name != 'CMIP6':
sub_pattern_names = ['']
var_types = ['tauuv', 'thetao']
# 创建外层进程池(根据系统资源调整max_workers)
with ProcessPoolExecutor(max_workers=45) as executor:
futures = []
# 生成所有任务
for var_type in var_types:
for sub_pattern_name in sub_pattern_names:
future = executor.submit(
process_subpattern,
var_type,
sub_pattern_name,
pattern_name
)
futures.append(future)
# 等待并处理结果
for future in concurrent.futures.as_completed(futures):
try:
future.result()
except Exception as e:
logger.error(f"子任务异常: {str(e)}")
logger.info("所有子模式处理完成")


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









