




 本文详细介绍了C++中通过数组模拟实现的数据结构,包括单链表、双链表、栈、队列、单调栈、单调队列、KMP算法以及Trie树,并讨论了并查集在连通块中点数量的维护。这些内容是算法设计和基础数据结构学习的重要部分。
本文详细介绍了C++中通过数组模拟实现的数据结构,包括单链表、双链表、栈、队列、单调栈、单调队列、KMP算法以及Trie树,并讨论了并查集在连通块中点数量的维护。这些内容是算法设计和基础数据结构学习的重要部分。
第二章:数据结构
2.1 单链表:单链表
算法思想:
- 该部分主要通过数组模拟单链表,进行插入结点、删除结点等操作。之所以需要用数组进行模拟,是因为在
C ++或java中,new操作是非常慢的,在数据范围比较大的情况和容易TLE,并且,在很多时候,容器可以做的数组都可以做,而数组可以做的,容器不一定可以做。那么利用数组模拟就显得十分有优势。通过数组模拟单链表,需要定义head, e[], ne[], idx,其中head表示头结点,e[]表示每个点的值,ne[]表示每个点所指向的下一个点的下标,idx表示当前已经用到了哪个点(此时idx还没被用)。 - 该部分是后面邻接表部分的基础,十分重要。
代码实现:
// head存储链表头,e[]存储节点的值,ne[]存储节点的next指针,idx表示当前用到了哪个节点
static int head;
static int[] e = new int[N];
static int[] ne = new int[N];
static int idx;
// 初始化
public static void init() {
head = -1;
idx = 0;
}
// 在表头插入一个数x
public static void addHead(int x) {
e[idx] = x;
ne[idx] = head;
head = idx;
idx ++;
}
// 在下标为k的结点后面插入一个数x
public static void add(int k, int x) {
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx;
idx ++;
}
// 删除下标为k的结点后面的一个结点
public static void remove(int k) {
if (k == 0 && head != -1) head = ne[head]; // 特判是否为头结点,删除头结点时需要判断头结点是否存在
else ne[k] = ne[ne[k]];
}
// 单链表的遍历
for (int i = head; i != -1; i = ne[i])
System.out.printf("%d ", e[i]);
2.2 双链表:双链表
算法思想:
与单链表相似,用数组模拟双链表。需定义e[], l[], r[], idx,其中e[]表示每个结点的值,l[]表示结点的上一个结点下标,r[]表示结点的下一个结点下标,idx表示当前用到了哪个点(此时idx还未被使用)。
代码实现:
int e[N], l[N], r[N], idx;
// 初始化链表
public static void init() {
// 0是左端点,1是右端点
r[0] = 1;
l[1] = 0;
idx = 2;
}
// 在节点k的右边插入一个数x
public static void insert(int k, int x) {
e[idx] = x;
l[idx] = k;
r[idx] = r[k];
l[r[k]] = idx;
r[k] = idx ++ ;
}
// 删除节点k
public static void remove(int k) {
// 先后顺序无所谓
l[r[k]] = l[k];
r[l[k]] = r[k];
}
// 遍历双链表
for (int i = r[0]; i != 1; i = r[i])
System.out.printf("%d ", e[i]);
2.3 栈和队列:模拟栈 模拟队列
算法思想:
用数组模拟栈和队列,操作相对简单,具体见代码实现。
代码实现:
// 数组模拟栈
static int[] stk = new int[N];
static int tt = 0; // 栈顶指针
stk[ ++ t] = x; // 在栈顶插入x
tt --; // 栈顶元素出栈
// 数组模拟队列
static int[] queue = new int[N];
static int hh = 0, tt = -1;
queue[ ++ tt] = x; // 在队尾插入元素x
hh ++; // 弹出队头元素
2.4 单调栈:单调栈
算法思想:
单调栈用于维护一个递增或递减的序列,可以快速求出每个数左边离它最近的比它大/小的数。
代码实现:
int n = sc.nextInt();
final int N = 100010;
int[] stk = new int[N];
int tt = 0;
for (int i = 0; i < n; i ++) {
int x = sc.nextInt();
while(tt > 0 && check(stk[tt])) tt --; // check为具体题目的判断
if (tt > 0) System.out.printf("%d ", stk[tt]);
else System.out.printf("%d ", -1);
stk[++ tt] = x; // 插入新元素
}
2.5 单调队列:滑动窗口
算法思想:
单调队列与单调栈比较类似,用一个队列动态维护一组有序序列。每次先判断对头是否需要出栈,然后从队尾开始向前检查队尾元素与当前枚举元素的关系,如果满足check(a[i]),则让队尾元素弹出。最后再将当前枚举元素加入队列。值得注意的是,队列q[]存储的是数组中元素的下标。该算法常用的场景为求解滑动窗口中的最大或最先值。
代码实现:
int[] a = new int[N]; // 存储所有元素
int[] q = new int[N]; // 用于动态维护队列,存储的是元素下标
int n = sc.nextInt(), K = sc.nextInt(); // n表示所有元素个数, k表示滑动窗口大小
for (int i = 0; i < n; i ++){
if(hh <= tt && i - k + 1 > q[hh]) hh ++; // 判断对头元素是否需要出栈
while (hh <= tt && a[i] <= a[q[tt]]) tt --; // 判断队尾元素是否需要弹出,a[i] <= a[q[tt]]可根据题目具体条件更换
q[ ++ tt] = i; // 将枚举的元素插入队尾
if (i >= k - 1) System.out.printf("%d ", a[q[hh]]); // 判断是否为前k个元素
}
2.6 KMP算法:KMP字符串
算法思想:
kmp算法是比较经典的字符串匹配算法,kmp是其三个发明人名字缩写。kmp算法是将模式串P与主串S进行匹配,其核心思想是将已经匹配过的字符利用起来,例如主串S为abaabac,模式串P为abac,当匹配到第四个字符发现不匹配时,主串中前三个字符已经匹配成功,我们可以将这个信息利用起来,那么下次匹配可以将P串的第一个字符直接与S串的第四个字符开始匹配,跳过了中间的一段,从而降低算法时间复杂度。而P串最少可以往前移动多少且可能匹配成功只取决于P串本身以P[i]结束的字串的前缀和后缀相等的最大值(next[i]),这便是KMP算法中比较抽象的next数组的含义。
代码实现:
// s[]为主串,p[]为模式串,n为模式串的长度, m为主串的长度
// 求next数组
for (int i = 2, j = 0; i <= n; i ++){ // ne[1] = 0
while (j != 0 && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++;
ne[i] = j;
}
// 匹配过程
for (int i = 1, j = 0; i <= m; i ++){
while (j != 0 && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++;
if (j == n){
// 匹配成功
j = ne[j]; // 之所以匹配成功还需要 j = ne[j]是因为一个主串里可能包含多个模式串
bw.write(i - n + " "); // 每道题的具体逻辑,这里是输出匹配成功的开始下标
}
}
2.7 Trie树:字符串统计
算法思想:
Trie树是一种用于存储字符串的高效的数据结构,以一棵树的形式存储字符串中的每个字符,如果该字符已经存在,则不重新创建,否则创建该字符,并在树中每个字符串结尾的地方做标记,表示树中含有以该字符结尾的字符串。
图示:
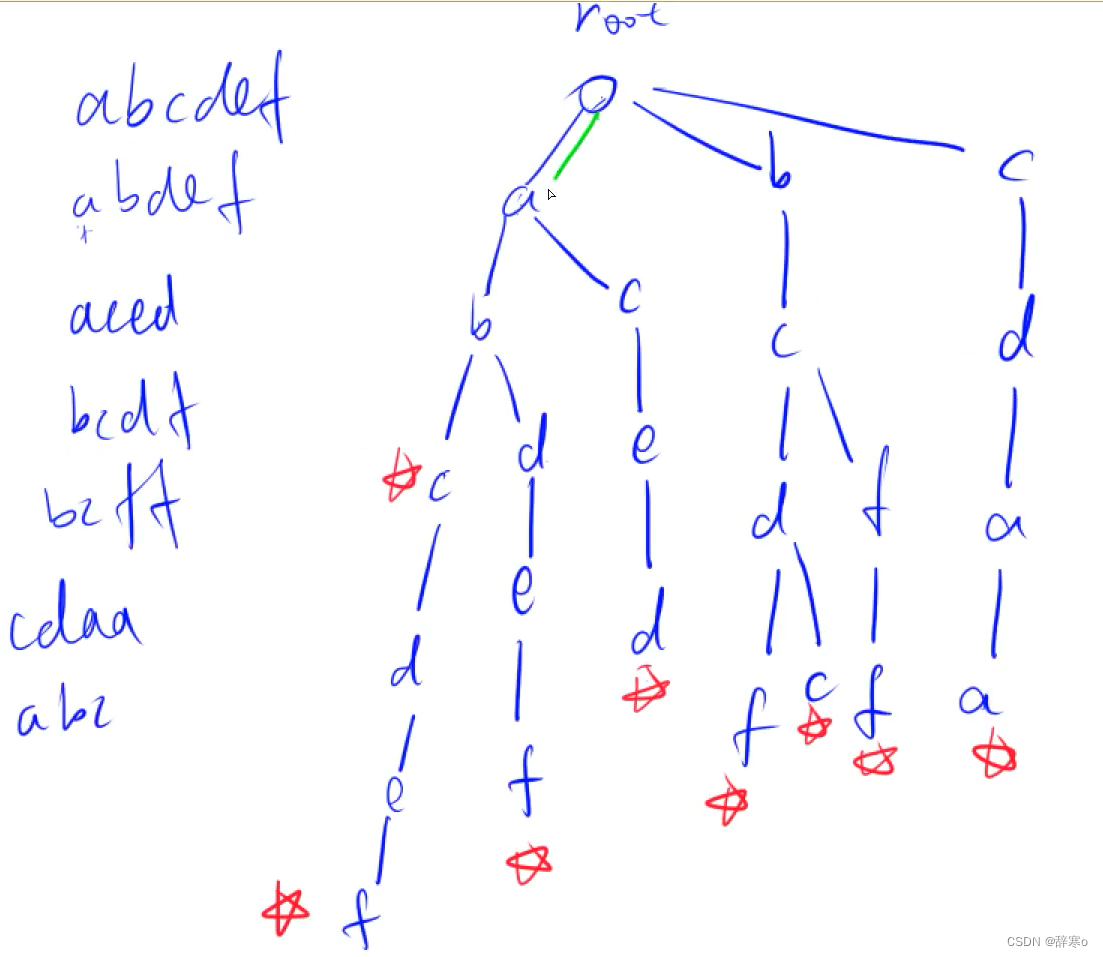
代码实现:
//
static int[][] son = new int[N][26]; // 表示每个字符的所有儿子结点
static int idx; // 表示当前son中用到了哪个下标
static int[] cnt = new int[N]; // 表示以cnt[p]这个字符结尾的字符串个数
// 插入字符串到Trie树中
public static void insert(char[] str) {
int p = 0; //从根节点开始找
for (int i = 0; i < str.length; i ++){ //遍历要插入字符串的每个字符
int u = str[i] - 'a'; // 将该字符转换为0 ~ 25的数字
if(son[p][u] == 0) son[p][u] = ++ idx; // 如果p结点不存在u这个儿子,则创建一个
p = son[p][u]; // 然后更新p的位置
}
cnt[p] ++; // 添加成功后将以p位置结尾的这个字符串数量+1
}
// 查询字符串是否在Trie树中
public static int query(char[] str) {
int p = 0;
for (int i = 0; i < str.length; i ++){
int u = str[i] - 'a';
if (son[p][u] == 0) return 0; // 如果发现某个字符在当前查询的路线中不存在,则说明该字符串不在树中,直接返回0个
p = son[p][u]; // 更新p的位置
}
return cnt[p]; // 返回以p位置处的字符结尾的字符串个数
}
2.8 并查集:连通块中点的数量
算法思想:
-
并查集是用来动态维护集合的,可以在近乎
O(1)的时间内将两个集合合并,其原理为让一个集合的根节点直接指向另一个集合的根节点,成为另一个集合的一个子集。可以通过寻找一个节点的祖宗节点判断该元素属于哪个集合,其时间复杂度与树的高度相关,所以,需要对其进行优化。 -
优化思想 :将每个节点直接指向其祖宗节点,该操作是在寻找祖宗节点的回溯过程中完成的。
-
查找两个点是否在同一个集合当中时,可以通过其祖宗节点是否是同一个节点进行判断。
-
规定: 祖宗节点的父节点等于自己(递归的退出条件)
代码实现:
// find函数,并查集的核心
public static int find(int x){
if(p[x] != x) p[x] = find(p[x]);
return p[x];
}
for (int i = 1; i <= n; i ++) p[i] = i; // 初始化父亲数组,即每个节点开始都是一个集合
待续……

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









