




 本文详细介绍了YOLOv1目标检测算法,包括其提出背景、网络结构、检测策略、算法流程以及优劣势。YOLOv1作为实时性极高的One-Stage算法,虽有速度快和迁移性强的优点,但对靠近的物体、小物体检测和角度目标泛化能力较弱。
本文详细介绍了YOLOv1目标检测算法,包括其提出背景、网络结构、检测策略、算法流程以及优劣势。YOLOv1作为实时性极高的One-Stage算法,虽有速度快和迁移性强的优点,但对靠近的物体、小物体检测和角度目标泛化能力较弱。
0. 紧接上一篇目标检测算法的介绍
本篇YOLO算法系列,参考优秀作者-AI菌,文章链接:YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)_yolov9-优快云博客
1. YOLOv1
1.1 概述
YOLOv1算法出现之前,目标检测领域以R-CNN系列算法(Two-Stage)担任主力军,但是因为是Two-Stage网络结构,在实时性上一直很差。
2016年Joseph等人提出了首个One-Stage的目标检测网络,它的检测速度非常快,每秒45帧图像,这就是大名鼎鼎的You Only Look Once。
YOLO的核心思想就是将目标检测问题转变成回归问题,以前都是分类问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框)的位置及其所属的类别。
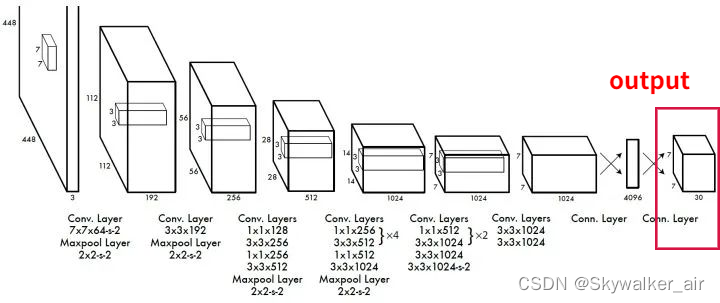
图1 YOLOv1网络图
网络结构简洁清晰,端到端的网络结构:
- 网络输入:448×448×3的彩色图片;
- 中间层:由若干个卷积层和最大池化层组成,用于提取图片的抽象特征;
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值;
- 网络输出:7×7×30的预测结果。
1.2 具体实现
1.2.1 检测策略
- 核心思想是“分而治之”,将一张图片平均分成7×7个网格中,每个网格分别负责预测中心点落在该网格内的目标;
- Faster R-CNN网络中的RPN网络需要额外再训练,在YOLO中7×7=49个网格就是目标的感兴趣区域;
1.2.2 算法流程
- 将输入图像分成S×S个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object;
- 每个网格预测B个bounding box,每个bounding box要预测(x,y,w,h)和confidence共5个值;
- 每个网格还要预测一个类别信息,记为C类;
- 总的来说,S×S个网格,每一个网格要预测B个bounding box,还要预测C个类。网络输出就是S×S×(5×B+C)的张量。
1.2.3 目标损失函数 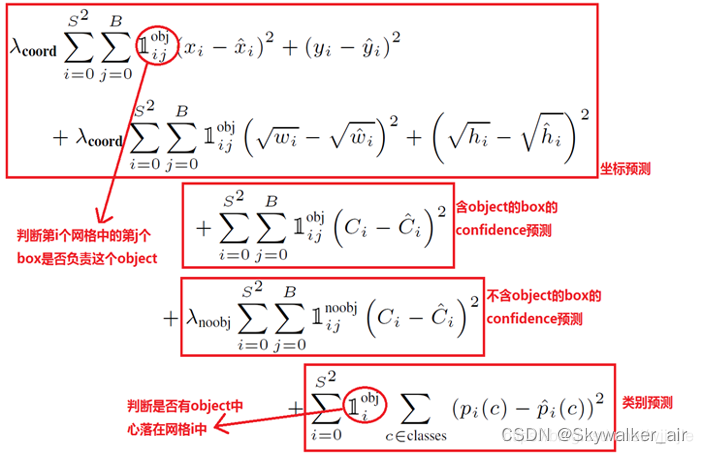
-
损失函数由三部分组成:坐标预测损失、置信度预测损失和类别预测损失;
-
使用的是差方和误差,w和h的误差计算是用平方根,小box框的预测偏一点是不能忍受的;
-
定位误差比分类误差更大,所以增加定位误差的惩罚;
-
若网格中不包含任何目标,则训练时,这些网格中的置信度分数为零,可能导致模型训练早期发散,故要减少不包含目标框的置信度预测的损失。
1.3 优劣势
1.3.1 优点
- YOLO检测速度非常快,每秒45张图像,达到了实时的效果;
- 实时检测的平均精度是其他实时检测系统的两倍;
- 迁移能力强,能运用到其他的新领域。
1.3.2 缺点
- YOLO对相互靠近的物体、很小的群体检测效果不好,网格中只预测了2个框,并且属于同一类;
- 由于损失函数的问题,定位误差影响检测效果很明显,尤其是在大小物体的处理上;
- YOLO对不常见的角度目标泛化性能偏弱。

















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









