



Chapter 1 概述
1.1 概念
编译器:翻译官,语义要相同
编译器静态计算生成目标程序,动态计算得到结果;
解释器:边解释边运行
1.2 结构
非常模块化,分为前端和后端;
按照阶段来看,可以看作流水线。
一、没有优化的结构
(字符序列)词法分析(记号序列)语法分析(抽象语法树)语义分析(中间代码)代码生成(目标代码)
1.3 例子
一、栈式计算机
包含,一个栈、两条指令
1+2+3->加法树(IR)->代码生成
1.4 转移图
转移图:判断分析代码的流程,比如,可以分析大于小于号
标识符(变量名)和关键字有交集,词法分析角度上来看,关键字是标识符一部分。
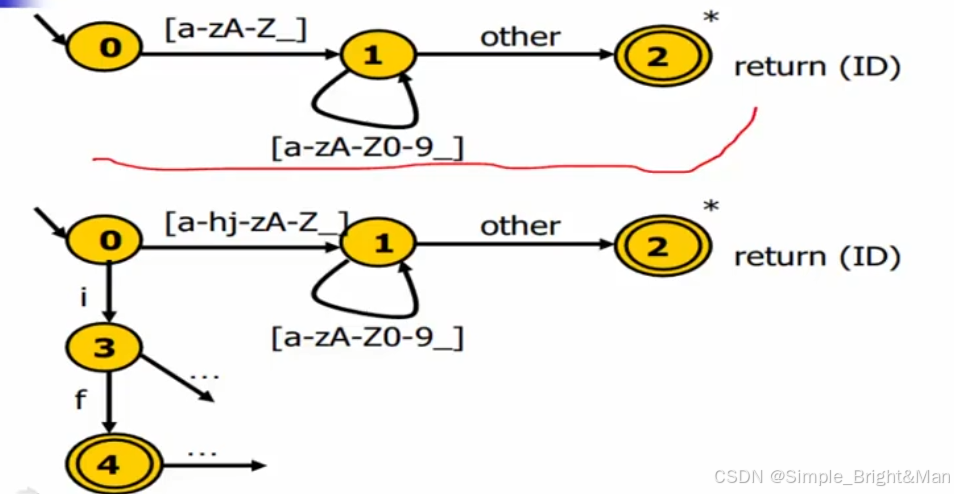
除了转移图,还能用哈希表,哈希表存入所有关键字。
方法:先转移图,识别完成后查表,看看是不是关键字。
1.5 正则表达式
也就是自动生成了
一、规则
空串是正则表达式;
任意字符集,是正则表达式;
如果M、N是正则表达式,那么M|N选择、MN连接、M*闭包也是正则表达式。

1.6 有限状态自动机
分析输出的到底是什么,要用到词法分析器。
输入字符串->FA->{Yes, No}
仍旧是节点(状态)+边(外部条件)的结构
转移函数:(q_0, a)->q1
有时,转移函数的输出不一定确定,就叫非确定有限状态自动机NFA。确定状态有限自动机DFA。
Chapter 3 正则表达式转换DFA
流程如下:

3.1 Thompson算法
RE->NFA
一、特点
1. 对RE结构做归纳(基本的RE直接构造,复合的RE递归构造)
2. 递归
二、画图
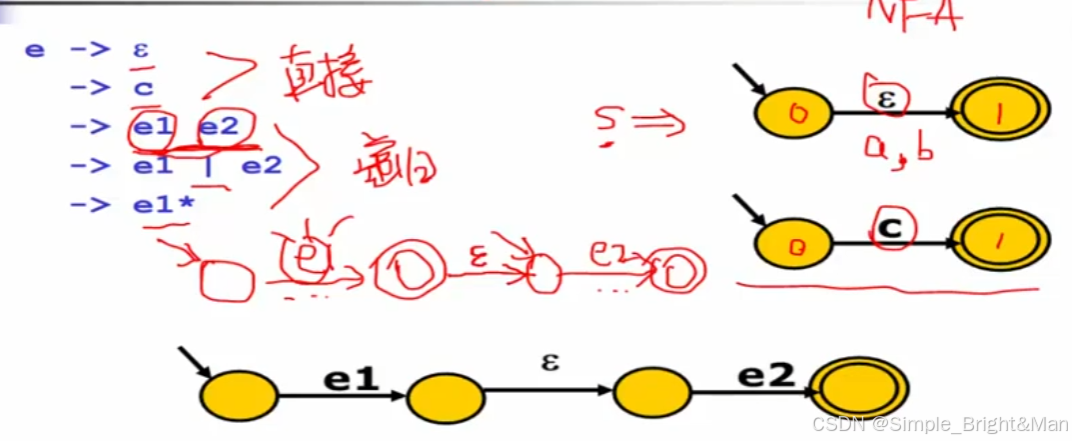
为什么中间要放一个空集?方便实现;
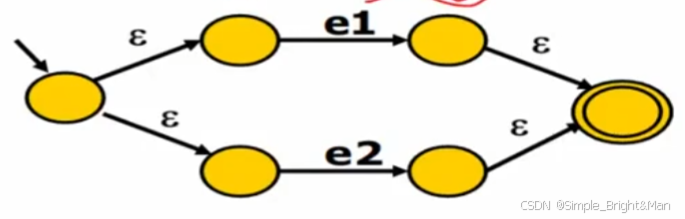

3.2 子集构造算法
NFA需要回溯,DFA不要。
思想:每次读入,都会改变当前能到达的节点集合,通过不断地读入,不断地改变集合。
讨论:算法为什么能终止?因为元素组合可能一定有上限。时间复杂度最坏为2的n次方。
这个过程中,需要求艾普斯龙闭包,可以使用深度优先、宽度优先,没什么区别。

q123都是结束状态

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









