





作者:韩信子@ShowMeAI
教程地址:http://www.showmeai.tech/tutorials/84
本文地址:http://www.showmeai.tech/article-detail/179
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
1.Spark Streaming解读

1)Spark Streaming简介
Spark Streaming是Spark核心API的一个扩展,可以实现实时数据的可拓展,高吞吐量,容错机制的实时流处理框架。
Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming 也能和 MLlib(机器学习)以及 Graphx 完美融合。
(1)流数据特点
- 数据一直在变化
- 数据无法回退
- 数据始终源源不断涌进
(2)DStream概念
和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而DStream 是由这些RDD 所组成的序列(因此得名“离散化”)。
(3)DStream形成步骤
- 针对某个时间段切分的小数据块进行RDD DAG构建。
- 连续时间内产生的一连串小的数据进行切片处理分别构建RDD DAG,形成DStream。
定义一个RDD处理逻辑,数据按照时间切片,每次流入的数据都不一样,但是RDD的DAG逻辑是一样的,即按照时间划分成一个个batch,用同一个逻辑处理。
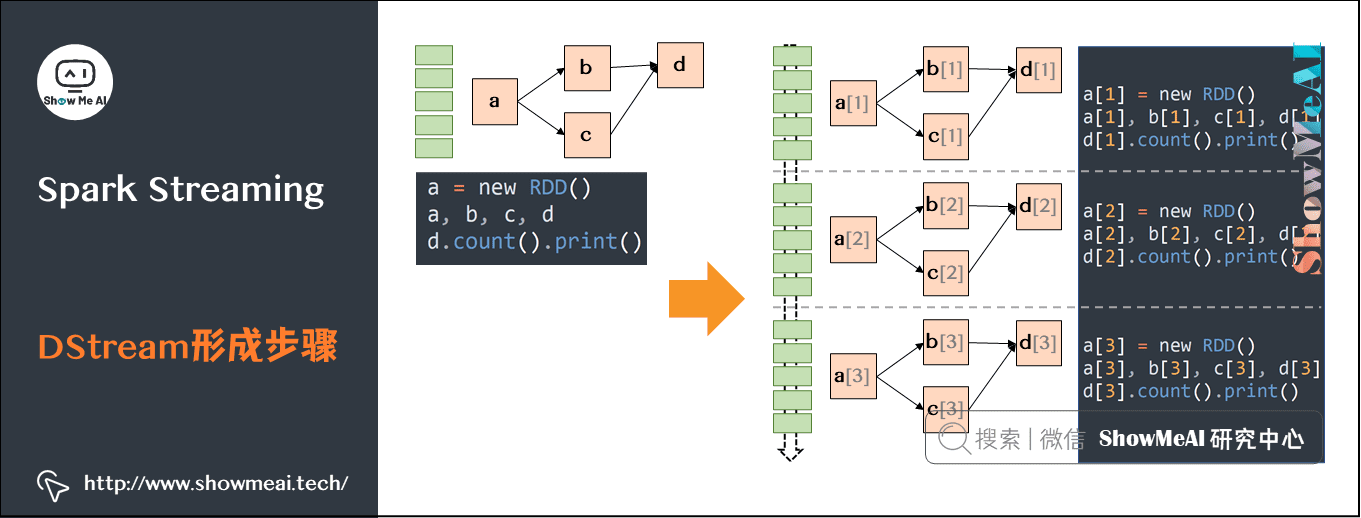
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的 DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
2)Spark Streaming特点

Spark Streaming有下述一些特点:
-
易用:Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序求照的器。
-
容错:Spark Streaming在没有额外代码和配置的情况下,可以恢复丢失的数据。对于实时计算来说,容错性至关重要。首先要明确一下Spak中RDD的容错机制,即每一个RDD都是个不可变的分布式可重算的数据集,它记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都可以使用原始输入数据经过转换操作重新计算得到。
-
易整合到Spark体系中:Spark Streaming可以在Spark上运行,并且还允许重复使用相同的代码进行批处理。也就是说,实时处理可以与离线处理相结合,实现交互式的查询操作。
3)Spark Streaming架构
大家知道Spark的工作机制如下:
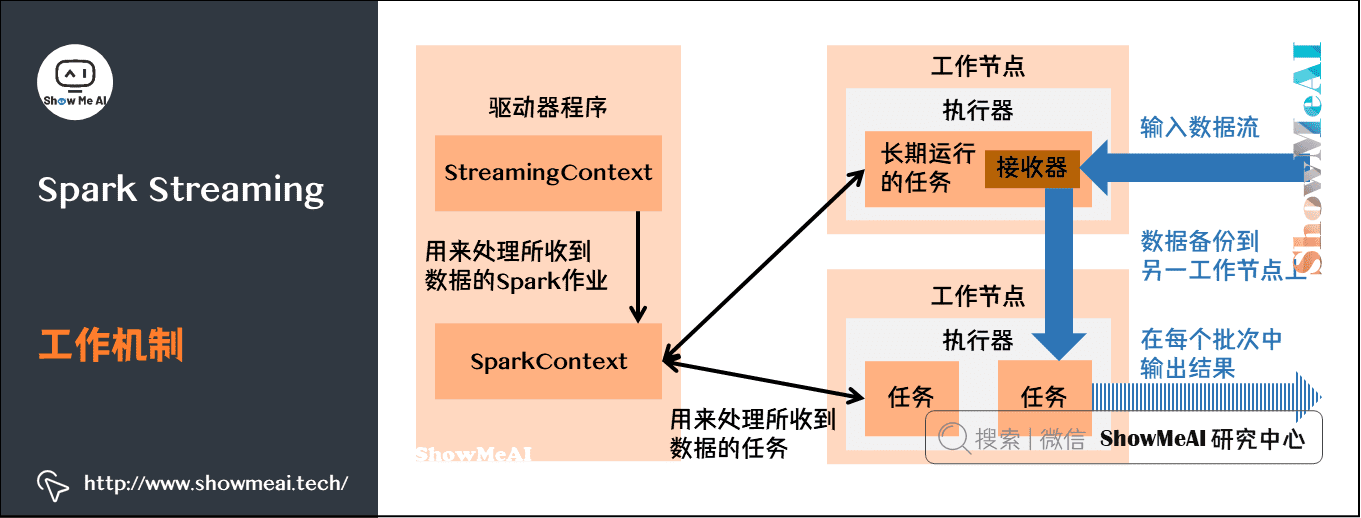
而SparkStreaming架构由三个模块组成:
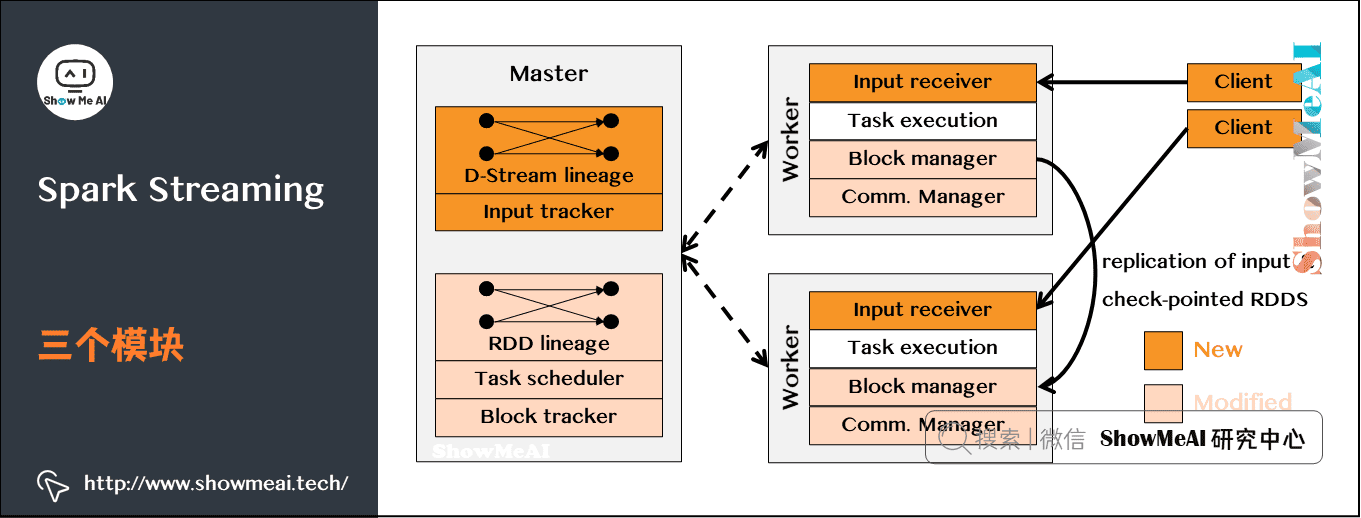
在上图中几个核心的角色和功能分别是:
-
Master:记录Dstream之间的依赖关系或者血缘关系,并负责任务调度以生成新的RD
-
Worker:
- ①从网络接收数据并存储到内存中
- ②执行RDD计算
-
Client:负责向Spark Streaming中灌入数据(flume kafka)
4)Spark Streaming 作业提交
(1)相关组件
Spark Sreaming的作业提交包含的组件和功能分别为:
- Network Input Tracker:跟踪每一个网络 received数据,并且将其映射到相应的 Input Dstream上
- Job Scheduler:周期性的访问 Dstream Graph并生成 Spark Job,将其交给 Job Manager执行
- Job Manager:获取任务队列,并执行 Spark任务
(2)具体流程
具体的作业提交流程如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











