




今天主要是对心脏病的数据进行一个预处理
首先是读取数据并找出缺失值。
import pandas as pd
data = pd.read_csv(r'C:\Users\许兰\Desktop\打卡文件\python60-days-challenge-master\heart.csv')
print(data.isnull().sum())但是结果是没有缺失值,所以没有进行缺失值补全
第二步是找到离散特征,并尝试分别对一个离散特征做独热编码,和一次性对所有离散特征做独热编码。
import pandas as pd
data = pd.read_csv(r'C:\Users\许兰\Desktop\打卡文件\python60-days-challenge-master\heart.csv')
print(data.columns)
for discrete_features in data.columns:
if data[discrete_features].dtype =='object':
print(discrete_features)
print(data['target'].value_counts())
data = pd.get_dummies(data, columns = ['target'])
data['target_0'] = data['target_0'].astype(int)
print(data.head())这里主要是对target这一个离散特征做了独热编码
过程是for循环找到离散变量,用其中的一个离散变量用.value_counts查看类型分布,确定没有顺序关系后进行独热编码,最后转化数据类型。
然后我再对所有的离散特征进行独热编码
import pandas as pd
data = pd.read_csv(r'C:\Users\许兰\Desktop\打卡文件\python60-days-challenge-master\heart.csv')
print(data.columns)
discrete_list = []
for i in data.columns:
if data[i].dtype =='object':
discrete_list.append(i)
data = pd.get_dummies(data,columns=discrete_list,drop_first=True)
data2 = pd.read_csv(r'C:\Users\许兰\Desktop\打卡文件\python60-days-challenge-master\heart.csv')
list_final = []
for i in data.columns:
if i not in data2.columns:
list_final.append(i)
for i in list_final:
data[i] =data[i].astype(int)
print(data.isnull().sum())过程:首先还是读取数据,然后定义列表存放离散特征,并进行独热编码,对比原先的数据,找到独热编码后的数据名称存放到新的列表,并改变数据的类型,最后统计缺失值,发现并没有。
数据可视化
准备先找个连续变量和标签整个箱线图和核密度直方图;然后整个离散变量和标签的直方图
import pandas as pd
data = pd.read_csv(r'C:\Users\许兰\Desktop\打卡文件\python60-days-challenge-master\heart.csv')
print(data.head())
continuous_features = []
for i in data.columns:
if data[i].dtype != 'object':
continuous_features.append(i)
print(continuous_features)
import matplotlib.pyplot as plt
import seaborn as sns
sns.boxplot(x=data['sex'],y=data['trestbps'])
plt.title('sex vs trestbps')
plt.xlabel('sex')
plt.ylabel('trestbps')
plt.show()过程是,先读取数据,查看表格内的分类标签,如性别,找到连续变量,绘制箱线图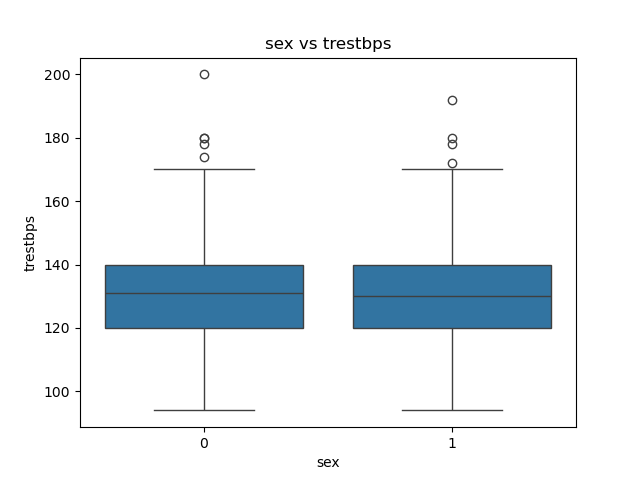
核密度直方图
import matplotlib.pyplot as plt
import seaborn as sns
sns.histplot(x='trestbps', hue='sex', data=data, kde=True, element="step")
plt.title('sex vs trestbps')
plt.xlabel('trestbps')
plt.ylabel('count')
plt.show()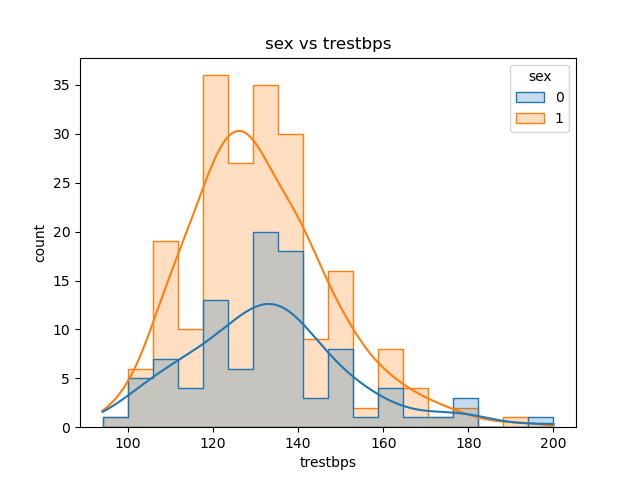
我尽力了,是我选的连续变量不好 ,这个图还是不够美观。
然后是离散变量与标签的计数条形图
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(x='exang', hue='sex', data=data)
plt.title('sex vs exang')
plt.xlabel('exang')
plt.ylabel('count')
plt.show()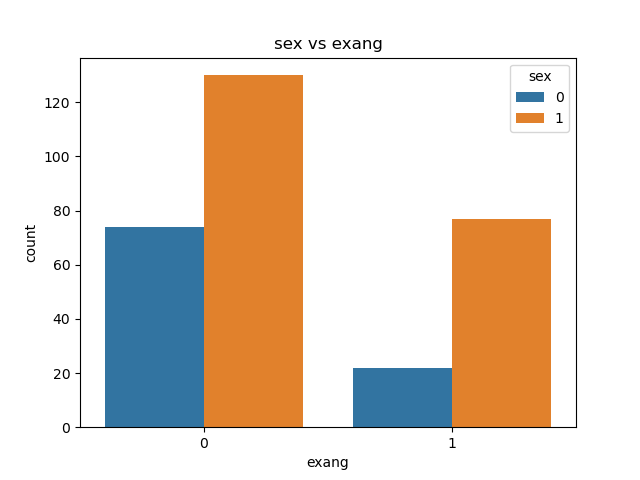
复习完毕,这里@浙大疏锦行

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









