





论文网址:Code Synonyms Do Matter: Multiple Synonyms Matching Network for Automatic ICD Coding - ACL Anthology
论文代码:https://github.com/GanjinZero/ICD-MSMN
目录
2.3.3. Multi-synonyms Attention
1. 心得
(1)感觉创新一般般,正文内容偏少
2. 论文逐段精读
2.1. Abstract
①作者认为现在大家都在关注标签相似度,但作者也想关注同义词编码
②作者想把ICD标签和UMLS知识库对齐以收集同义词
2.2. Introduction
①作者觉得需要匹配同义词如“甲状腺功能减退”=“低的t4指标”
②作者提出Multiple Synonyms Matching Network (MSMN)去解决同义词问题
2.3. Approach
①设自由诊断文本为,其中的单词集是
②任务:多标签分类
③MSMN框架图:
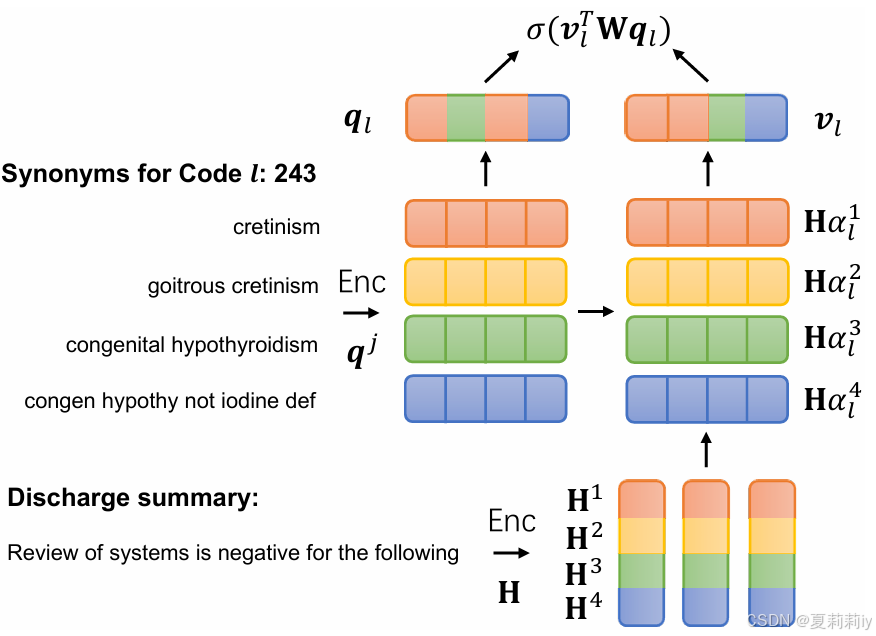
2.3.1. Code Synonyms
①先把每个ICD标签对齐UMLS的概念唯一标识符(CUIs)
②将同义词去掉连字符和NOS(Not Otherwise Specified)之后与ICD标签
连接
③每个词组都由很多单词组成:
hyphen n.连字符
2.3.2. Encoding
①以前的工作觉得BERT不能帮助ICD分类所以作者选了LSTM作为文本编码器??这,这样写真的好吗
②作者使用一个层的双向LSTM去编码每个单词:
③对同义词也采用同样的编码方式:
2.3.3. Multi-synonyms Attention
①受多头自注意力的启发,将原始标签特征拆分成
个(契合多头的不同头)
:
分别对每个头把同义词标签组和文本特征实行点积计算相似度,然后把每个头算出的相似度分别和文本特征乘起来:
只要至少一个同义词匹配到了相关文本,该特征就会被保留。增强了模型对表达多样性的鲁棒性。
2.3.4. Classification
①使用biaffine transformation计算相似度用于分类:
减少了计算量
2.3.5. Training
①交叉熵损失:
2.4. Experiments
2.4.1. Dataset
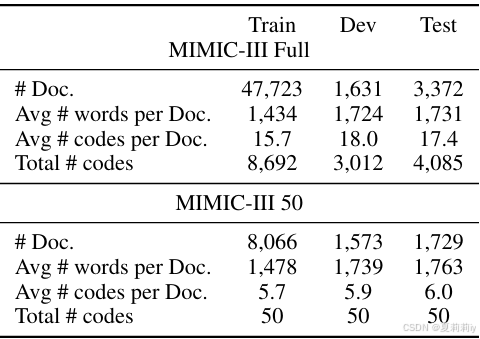
①数据集:MIMIC-III full和MIMIC III 50
②数据集统计:
2.4.2. Implementation Details
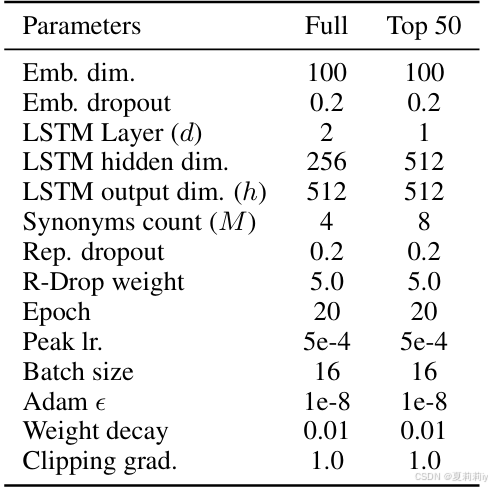
①同义词数量:在MIMIC III full中,在在MIMIC III 50中
②同义词是随机挑选的同个数,如果数量不够就一直重复
③文本嵌入是用的别的文章的,CBOW什么的
④使用R-Drop且
⑤嵌入后的Dropout rate:
⑥一些超参数:
2.4.3. Baselines
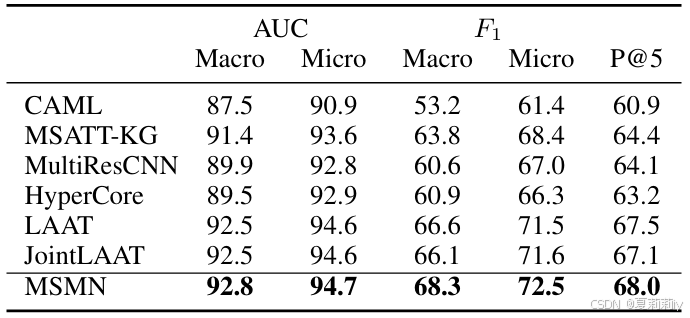
①基线:CAML、MSATT-KG、MultiResCNN、HyperCore、LAAT%JointLAAT
2.4.4. Main Results
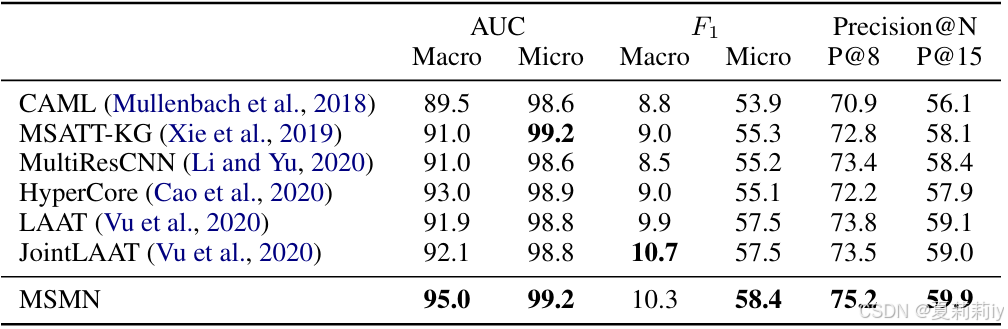
①在MIMIC III full上的对比实验:
②在MIMIC III 50上的对比实验:
2.4.5. Discussion
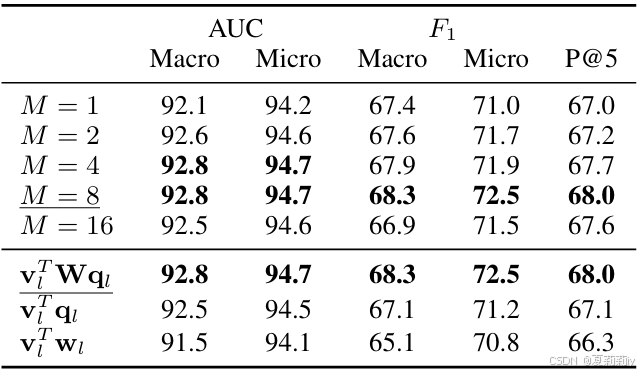
①尝试不同的同义词数量和不同的文本-标签匹配方式:
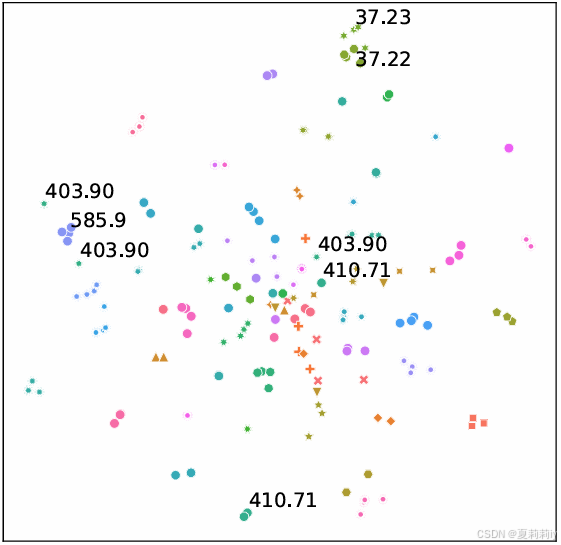
②同义词表征空间:
2.4.6. Memory Complexity
①使用Einstein 求和优化来少求注意力得分的中间内存
2.5. Related Work
①举例一些机器学习,RNN/CNN,标签注意力,图卷积,知识图谱
2.6. Conclusions
~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









