





论文网址:[2405.18812] MindSemantix: Deciphering Brain Visual Experiences with a Brain-Language Model
论文代码:Page not found · GitHub · GitHub
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.1. Pre-training: Self-supervised Brain-Encoder-Decoder (BED)
2.3.2. Training: End-to-end Brain-Language Model (BLM)
2.3.3. MindSemantix for Visual Reconstruction
2.4.4. MindSemantix for Reconstruction
1. 心得
(1)代码好像还是coming soon的情况,是打不开的(我反正打不开)(作者arXiv也写的之后公布)
(2)谁在push我!!!我只是一个无忧无虑读论文的博主啊
2. 论文逐段精读
2.1. Abstract
①Challenge: brain activity decoding
Decipher v. 破译,辨认(难认、难解的东西);理解(神秘或难懂的事物)
2.2. Introduction
①"captioning could facilitate visual decoding by approximatively simulating the reverse process of perceiving stimuli" 字幕预测为什么是视觉感知刺激逆向过程?感觉在默认人看到图片就一定会内心中有语义的解答,而且有些ADHD的看了不和没看一样(虽然一般不收录这种
②"low-level visual processing and high-level semantic processing"为什么看图片刺激是低级视觉刺激?还有高级语义?为什么不认可人的语言功能自动包含了低级语义(比如人已经会语法了)
③Recent works utilize ridge regression to extract fMRI feature(这股风到底怎么兴起的!!确实到处都在岭回归)
④Pipeline of MindSemantix:
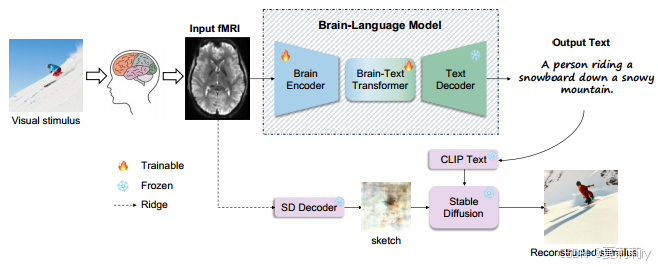
(如果作者只认同高级语义那么这右边的output text不会只是key words吗)
2.3. MindSemantix
①Specific pre-training and training processes:
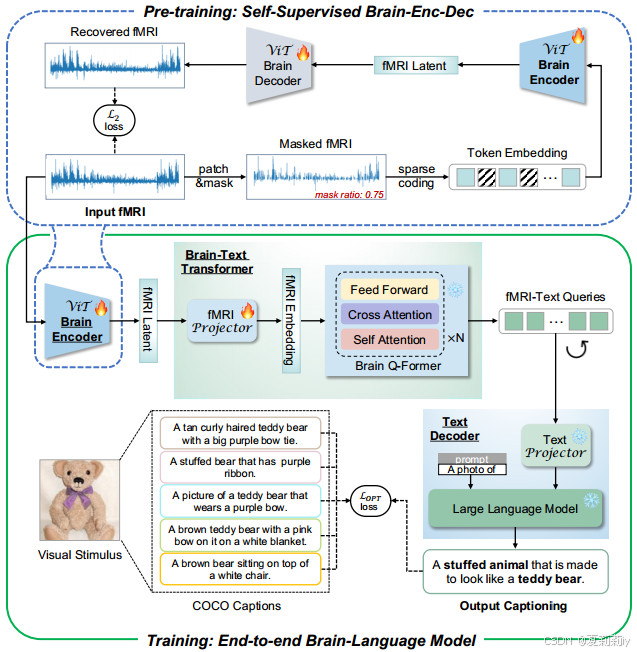
(哥们儿上半和BrainChat好相似啊哈哈哈虽然可能也是常见操作了)(为什么预训练对着mask之后的fMRI进行编码但是到了下面绿框是直接对原始信号进行编码了不会有问题吗!!)
2.3.1. Pre-training: Self-supervised Brain-Encoder-Decoder (BED)
①Reason for mask and reconstruction fMRI signal: spatial blurring brought by hemodynamic response and spatial smoothing
②L2 loss for brain signal (patch-wise) reconstruction:
where denotes real fMRI token and
denotes recovered
2.3.2. Training: End-to-end Brain-Language Model (BLM)
①fMRI projector: a fully-connected (FC) layer and a 1D convolutional layer
②Text projector: FC in BLIP-2, the same weights
③Caption generation loss:
where and
is real caption and predicted caption,
is the caption number of each image in COCO dataset (
)
2.3.3. MindSemantix for Visual Reconstruction
①SD decoder: ridge regressor, to mapping fMRI as a sketch (low level visual information contained)
②Visual reconstruction: by stable diffusion
2.4. Experimental Results
2.4.1. Dataset and Setting
①Dataset: NSD
②Subjects: 1/2/3/7 in total 8
③ROI: nsdgeneral
④Patch size of fMRI: 16
⑤各种预训练和训练的epoch还有什么预热啥的真的不想搬运了好多
2.4.2. Evaluation Metric
①Low level metrics: Meteor, Rouge, CIDEr
②High level metrics: SPICE, CLIP, Sentence
2.4.3. Captioning Results
①Performance of MindSemantix when Gaussian noise added:
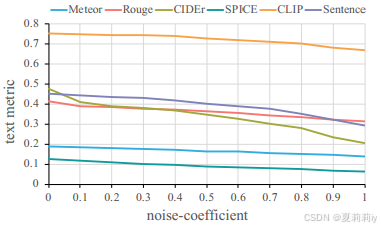
②Visualization of caption generation:
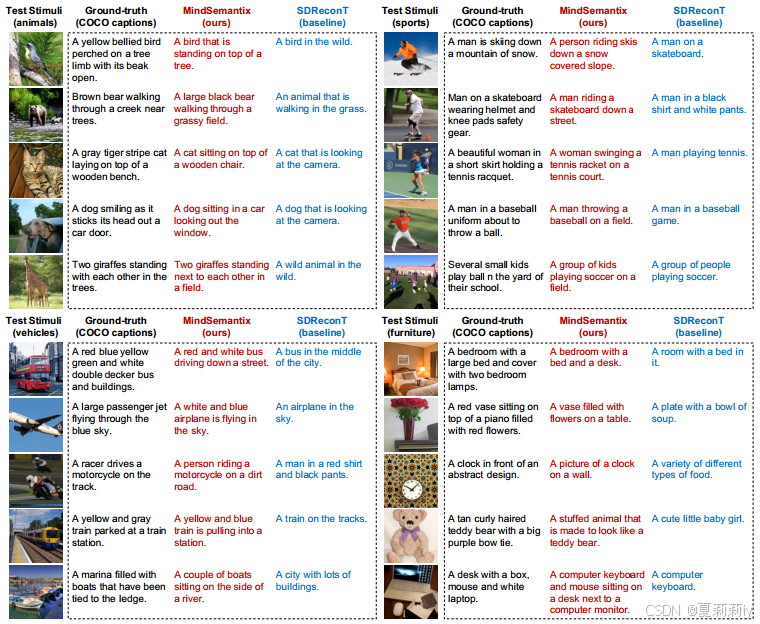
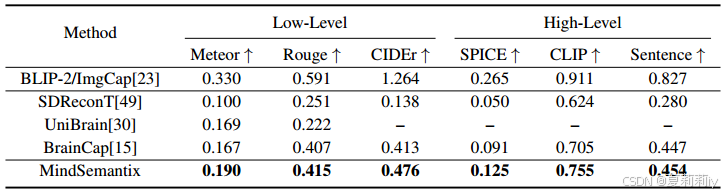
③Quantitative results:
2.4.4. MindSemantix for Reconstruction
①Example of image reconstruction:

②Comparison of image reconstruction:

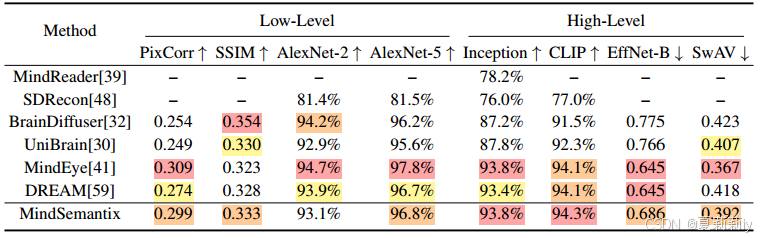
③Comparison table of quantitative metrics:
2.4.5. Ablation Study
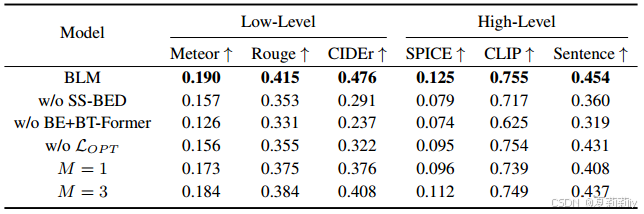
①Module ablation on subject 1:
②How caption assists image reconstruction:

2.5. Discussion
①可以优化生成的字幕,也可以用更好的预训练模型
2.6. Conclusion
~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









