



前言
Whisper-large-v3 是 OpenAI 推出的高性能多语言语音识别模型,基于 Transformer 架构,支持超过 99 种语言 的语音到文本转换和翻译,具备出色的准确率和鲁棒性。该模型适用于复杂音频场景,如噪声环境、不同口音和长音频转录,广泛用于字幕生成、语音助手和跨语言沟通等任务。
本文旨在本地电脑环境上实现Whisper-large-v3模型的部署和运行,较为简单
一、AutoDL
首先l浏览器搜索,点开AutoDL官网,AutoDL官网位置
申请/登录账号充好钱,选择自己需要的服务器。
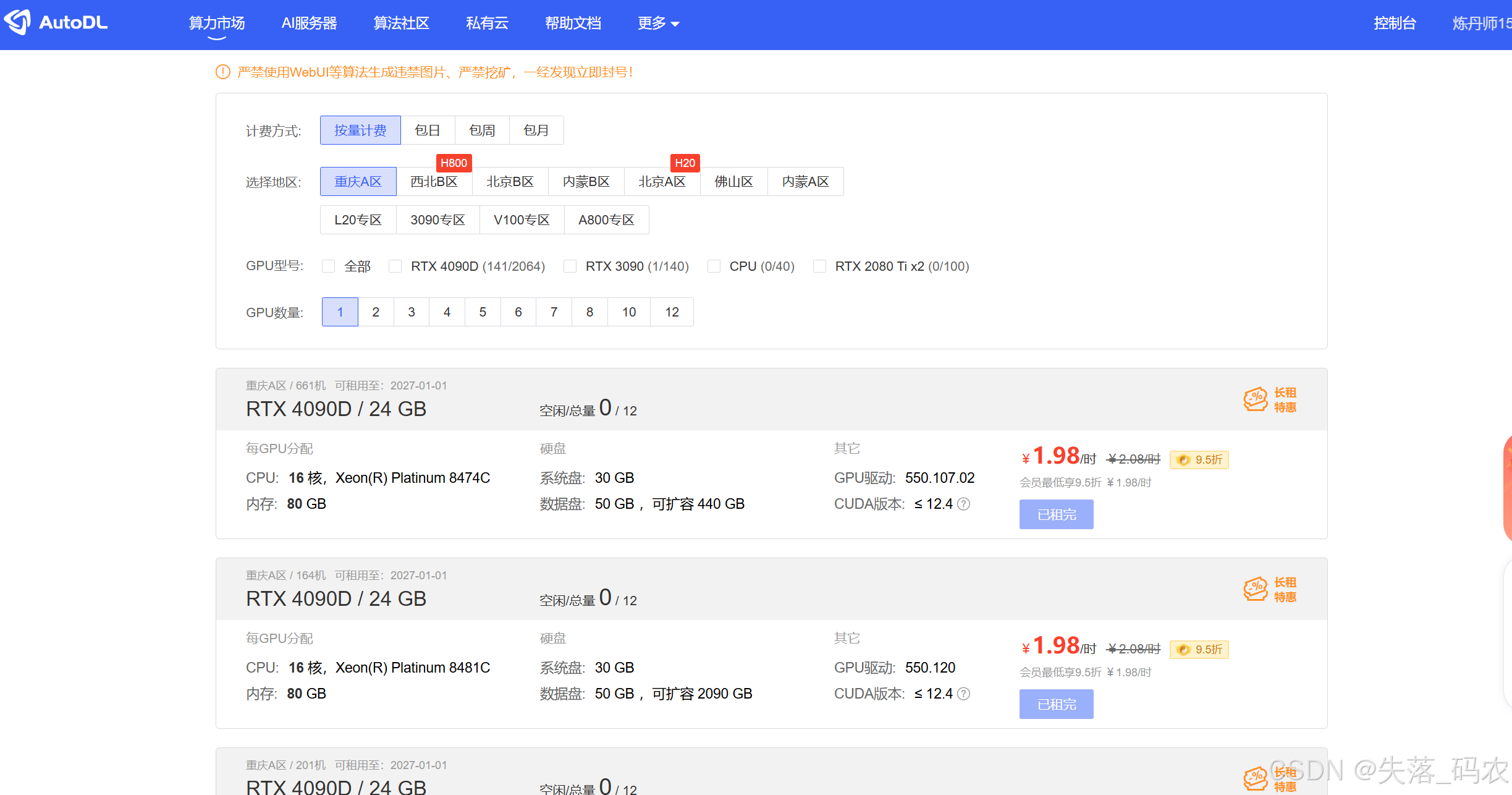
推荐使用GPU:NVDIA RTX 3080/3090/4090(24GB显存,高性能多核CPU,内存≥32GB)
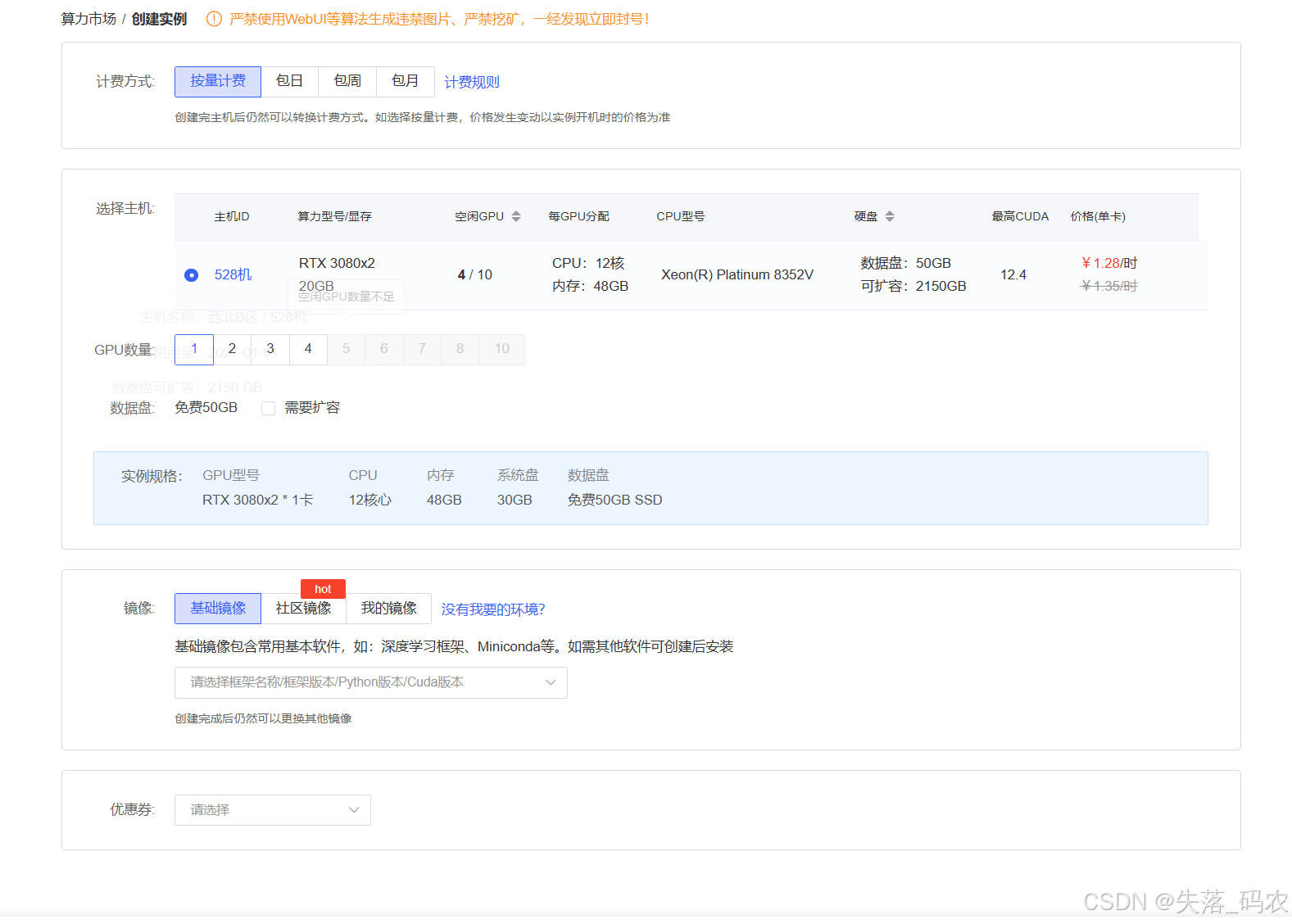
可以直接选择“基础镜像”,常用的miniconda等环境都是有的;如果是要用github上的项目,可以在“算法镜像”部分搜索,选择合适的镜像环境。 “我的镜像”适用于之前已经租过AutoDL上的服务器,因为目前那台机器没有空闲GPU了,所以将那台机器上的数据生成自己的镜像,然后就可以选择转移到这
选择好合适的服务器后,可以开始创建镜像:

我这里选择是pytorch2.0.0,python3.8,cuda11.8的版本,远在whisper-large-v3要求的环境之上
购买完成后,点击右上角控制台,然后点击导航栏的容器实例,就能看到自己已经购买的所有服务了。

重点留意SSH登录的指令和密码这块,稍后的与vscode远程连接要用到
二、AutoDL与Vscode建立远程连接
首先现在Vscode的扩展商店中下载,安装Remote SSH
ctrl+shift+p打开命令面板,搜索如下图的内容
点击添加新的SSH主机
然后在搜索框中输入你刚才在AutoDL上购买的服务器的登陆指令,点击回车
这里默认就行,点击回车
Vscode中,右下角会有弹出,点击连接

在新弹出的窗口中,上方搜索框中输入AutoDL的登录密码,点击回车
也可以在旧窗口中点击在此窗口中连接,然后输入密码,这样就不会有两个窗口了
至此,远程连接成功,我们点击Vscode左侧的资源管理,就能访问远程连接环境的文件了,这里还需要再输入一次密码,然后点击信任此作者,就能到达如图所示的界面,你就可以在终端中进行操作了
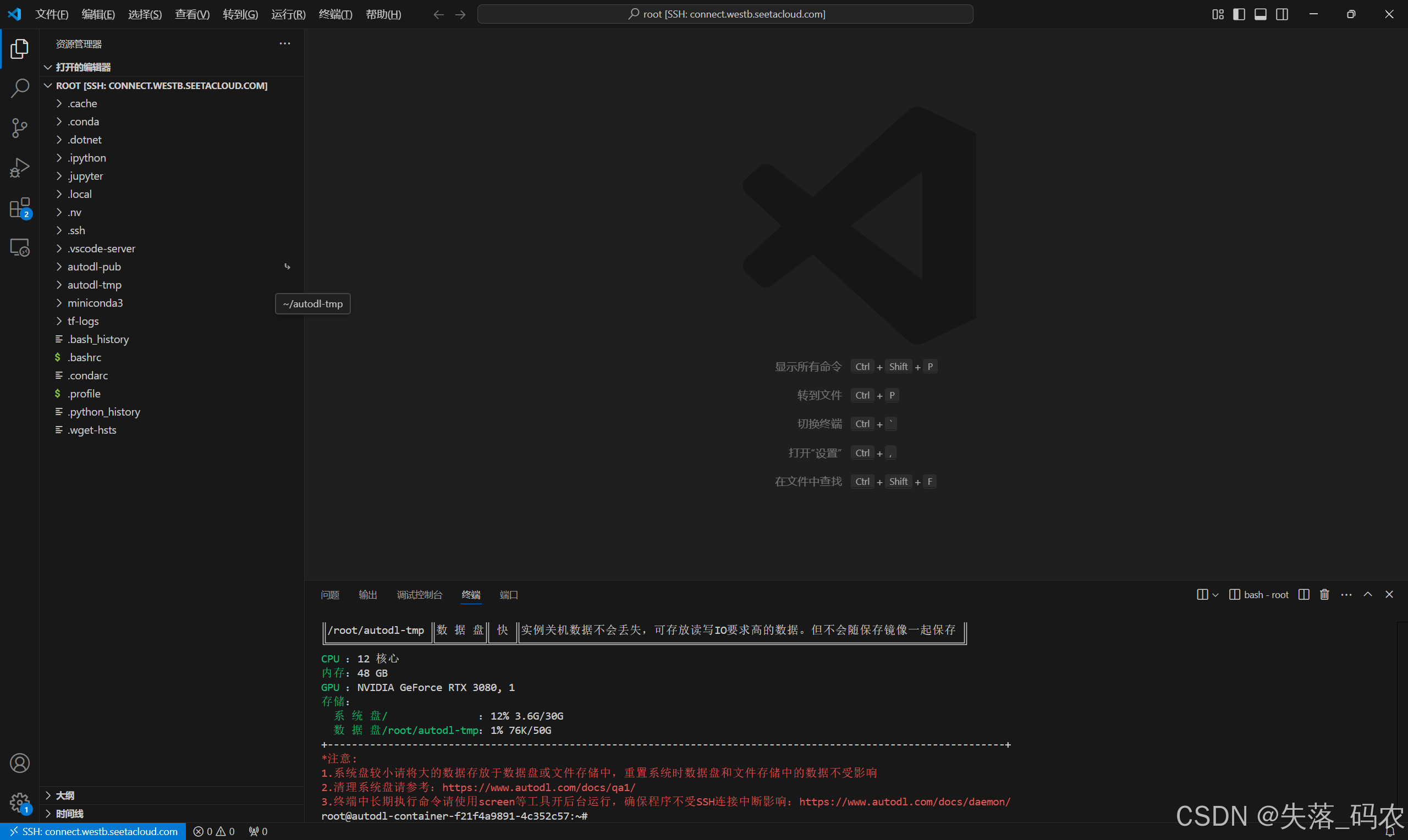
你可以在终端中输入:
python --version
nvcc --version
就能看到基本环境版本了

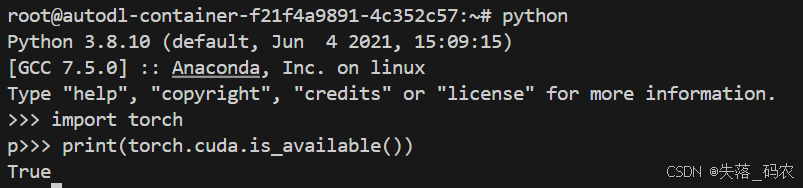
输入
import torch
print(torch.cuda.is_available()) # 返回 True 表示有可用 GPU
也说明pytorch也安装好了(这个是AutoDL提供给我们的镜像中自动有的,不用手动安装)
三、下载&运行Whisper-large-v3模型
1,下载模型,在命令行中输入:pip install openai-whisper
2,安装 ffmpeg,ffmpeg工具的主要作用是编码/解码/转码以及媒体格式转换,处理音频用的
sudo apt update
sudo apt install ffmpeg -y
安装后可以进行检验
ffmpeg -version
3,创建一个.py脚本文件,输入以下代码:
import whisper
import torch
# 检查是否有 GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载 Whisper-large-v3 模型
model = whisper.load_model("large-v3").to(device)
# 指定音频文件路径,写你自己的,如果音频在同级目录下,直接声明即可,如果不在,要写完整的地址
audio_file = "sounds2.mp3"
# 强制设置语言为中文进行转录
result = model.transcribe(audio_file, language="zh", fp16=True if device == "cuda" else False)
# 打印识别结果
print("识别结果:", result["text"])
保存即可
在命令行输入python xxxxxx.py,即可运行结果(xxxx为脚本文件名)


















 7955
7955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









