




贴心小梗概
本文将介绍使用LazyLLM搭建最基础的RAG的流程。首先介绍使用LazyLLM搭建RAG系统的必要环境配置,然后简单回顾RAG的基本流程,接下来分别介绍RAG中文档加载、检索组件、生成组件三个关键部分的参数和基本使用方法,最后利用LazyLLM实现最简单的RAG,并展示相关效果。
环境准备
在使用LazyLLM搭建RAG系统之前,我们需要配置好相关的环境,包括“开发环境搭建”和“环境变量配置”两个步骤。
1.开发环境搭建
您可以用以下任一方式搭建 LazyLLM 开发环境。
📌手动配置
LazyLLM 基于 Python 开发,我们需要保证系统中已经安装好了 Python, Pip 和 Git。在Macbook上安装这些比较复杂,安装方式见附录。
首先准备一个名为 lazyllm-venv 的虚拟环境并激活:
python -m venv lazyllm-venv
source lazyllm-venv/bin/activate如果运行正常,你可以在命令行的开头看到 (lazyllm-venv) 的提示。接下来我们的操作都在这个虚拟环境中进行。
从 GitHub 下载 LazyLLM 的代码:
git clone https://github.com/LazyAGI/LazyLLM.git并切换到下载后的代码目录:
cd LazyLLM安装基础依赖:
pip3 install -r requirements.txt把 LazyLLM 加入到模块搜索路径中:
export PYTHONPATH=$PWD:$PYTHONPATH这样我们在任意目录下都可以找到它。
📌拉取镜像
我们提供了包含最新版本的 LazyLLM 的 docker 镜像,开箱即用:
docker pull lazyllm/lazyllm也可以从 https://hub.docker.com/r/lazyllm/lazyllm/tags 查看并拉取需要的版本。
📌从Pip安装
LazyLLM 支持用 pip 直接安装,下面三种安装方式分别对应不同功能的使用。
安装 LazyLLM 基础功能的最小依赖包。可以支持线上各类模型的微调和推理。
pip3 install lazyllm安装 LazyLLM 的所有功能最小依赖包。不仅支持线上模型的微调和推理,而且支持离线模型的微调(主要依赖 LLaMA-Factory)和推理(大模型主要依赖 vLLM,多模态模型依赖LMDeploy,Embedding模型依赖Infinity)。
pip3 install lazyllm
lazyllm install standard安装 LazyLLM 的所有依赖包,所有功能以及高级功能都支持,比如自动框架选择(AutoFinetune、AutoDeploy 等)、更多的离线推理工具(如增加 LightLLM 等工具)、更多的离线训练工具(如增加 AlpacaloraFinetune、CollieFinetune 等工具)。
pip3 install lazyllm
lazyllm install full2.API Key配置
调用大模型主要分为线上调用和本地调用两种方式。对于线上调用,您需要提供相应平台的API Key。如果您还没有对应平台的账号,首先需要在平台上注册一个账号。LazyLLM框架提供了自动调用平台API Key的功能,只需将您的API Key设置为环境变量,并在调用时指定平台和模型名称,即可实现线上模型的调用。
LazyLLM目前支持以下平台(api key链接见附件):
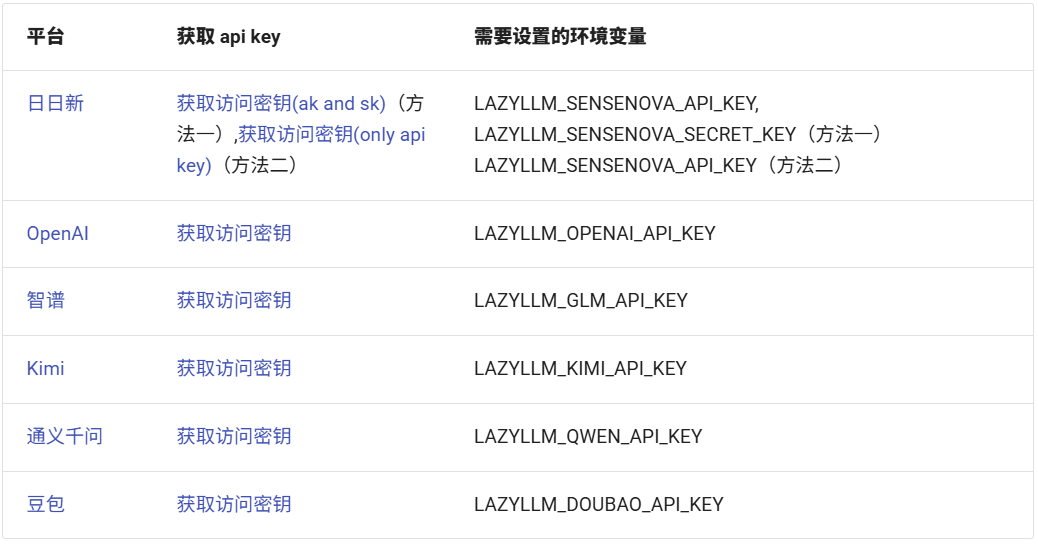
要配置平台的API Key为环境变量,请按照以下步骤操作:
1️⃣根据您使用的平台,获取相应的API Key(注意:SenseNova平台需要获取两个Key)。
2️⃣使用以下命令设置对应的环境变量:
export LAZYLLM_<使用的平台环境变量名称,大写>_API_KEY=<申请到的api key>例如,如果您需要访问SenseNova平台,如果您通过方法一获得密钥,您需要设置以下环境变量:
export LAZYLLM_SENSENOVA_API_KEY="您的Access Key ID"
export LAZYLLM_SENSENOVA_SECRET_KEY="您的Access Key Secret"如果您通过方法二获得密钥,您需要设置以下环境变量:
export LAZYLLM_SENSENOVA_API_KEY="您的API-Key"在配置好环境变量后,当您实例化OnelineChatModule并指定模型来源时,LazyLLM会自动根据配置的环境变量调用相应的API Key。
通过这种方式,您可以轻松管理和调用不同平台的API Key,简化了模型调用的流程。
RAG 实践剖析
1.原理回顾
在准备好LazyLLM的环境和配置后,让我们快速回顾一下RAG(Retrieval-augmented Generation,RAG,检索增强生成)的基本原理。RAG的工作原理是当模型需要生成文本或回答问题时,首先会从一个庞大的文档集合中检索出相关的信息,这些检索到的信息随后会被用于指导生成过程,从而显著提高生成文本的质量和准确性。RAG 的整体结构可以用下图标识,系统接收一个用户 Query, 首先通过检索器(Retriever)从外部文档中检索出与给定 Query 相似的内容,然后将其与 Query 一同输入到 LLM ,LLM 给出最终答案:
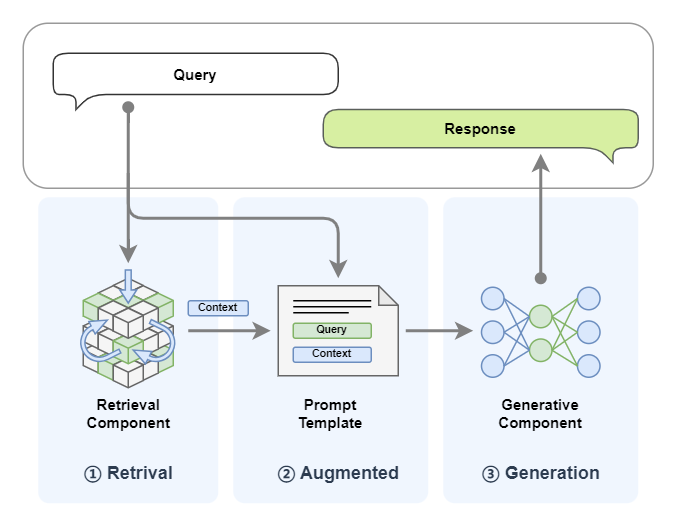
RAG的离线工作流程可以归纳成以下三步:
1️⃣文档读取和解析(Reader)
把各种格式的文档加载到系统中,可以借助开源工具(如MinerU)来提高解析的准确率。
2️⃣分块和向量化(Transform and Vectorize)
对收集到的原始数据进行清洗、去重、分块等预处理工作,然后进行向量化。
3️⃣索引和存储(Indexing and Store)
利用向量数据库或其他高效的向量检索工具,将处理后的文本数据进行高效的存储和索引。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









