




可观测性(Observability)是指通过系统的外部输出数据,推断其内部状态的能力。可观测性平台通过采集、存储、可视化分析三大可观测性数据:日志(Logging)、链路追踪(Tracing)和指标(Metrics),帮助团队全面洞察分布式系统的运行状态,支撑资源优化、预警机制、故障分析等,提升系统可靠性与用户体验。
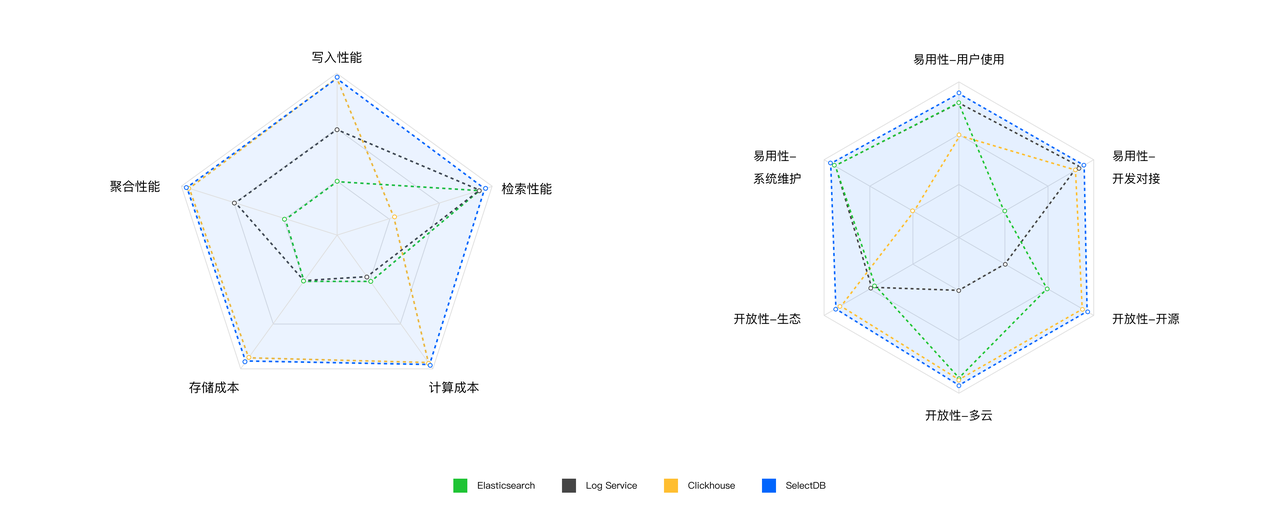
SelectDB 针对可观测性场景进行倒排索引、全文检索、写入性能、存储空间等多方面优化,助力企业构建高性能、低成本、开放的可观测性平台,相对于 Elasticsearch 和云上日志服务,性能提升的同时成本降低数倍。
- 高性能: 写入性能是 Elasticsearch 的 5 倍,日志查询性能是其 2 倍,聚合统计分析性能是其 6~21 倍。
- 低成本: 以日增 100TB、保存 30 天、热数据 3 天的需求,SelectDB Cloud 成本大约 20 万/月,Elasticsearch 大约 140 万/月,云厂商日志服务大约 135 万/月。
- 易用性: 兼容 MySQL 语法;架构简洁,支持无停服自动升级、弹性扩缩容及自动负载均衡;并提供可视化集群管理 Cluster Manager。
- 开放性: 在全球主流云上(阿里云、腾讯云、华为云、AWS、Azure、GCP)提供服务,支持 OpenTelemetry、Grafana、 Kibana 等开源和商业生态,保持生态开放性和中立性。
接下来,我们将从多个角度深入分析和介绍,包括可观测性场景需求、可观测数据的特征以及各种方案之间的对比。帮助读者全面地理解可 SelectDB 可观测性方案的优势和适用性。
为什么可观测性越来越重要
可观测性平台在提升系统稳定性、优化运维效率和支持业务创新方面发挥着关键作用,近年来,可观测性的地位日益提升,主要源于以下两方面因素:
- 业务和 IT 系统越来越复杂: 随着云计算和微服务的发展,业务系统日益复杂。例如,一个 GenAI 应用的请求可能涉及到 App、服务网关、鉴权服务、计费服务、RAG 引擎、Agent 引擎、向量数据库、业务数据库、分布式缓存、消息队列、大模型 API 等数十个服务。传统依赖登录服务器查询运行状态和分析故障的方式,在复杂系统中已经不再有效。而可观测性平台统一采集和存储 Log、Trace、Metrics 数据,提供统一可视化分析,能够有效快速发现问题。
- 业务可靠性要求显著提高: 系统故障及其恢复效率直接影响用户体验。可观测性通过全域数据打通和全景可视化分析,支持团队快速定位问题根源,缩短业务中断时间,保障服务可用性。同时,依托全局数据分析和预测,能够提前发现系统资源瓶颈,预防故障发生。
如何选择可观测性解决方案
可观测性数据的特征
可观测性解决方案的核心在于如何高效应对海量数据的存储与分析挑战,而可观测性数据本身具有以下显著特征:
- 数据存储量大且对成本敏感: 可观测性数据特别是 Log 和 Trace 规模极为庞大且持续生成。对于中大型企业而言,每天产生的可观测性数据高达 100 TB 甚至 PB 量级。为了满足业务需求或监管要求,这些数据往往需要存储半年甚至更长时间,存储总量长期维持在 PB 甚至 EB 级别,带来高昂的存储成本。而随着时间的推移,这些数据的价值也在逐渐下降,因此对于可观测性平台来说,存储成本也变的更加敏感。
- 数据写入吞吐高且需要实时: 面对每天 TB 甚至 PB 量级新增数据,要求平台具备 1 ~ 10GB/s、百万 ~ 千万条/s 的高吞吐写入能力;同时,考虑到可观测性数据常用于故障排查、安全追踪等时效要求很高的场景,还要求平台保证秒级写入延迟,确保数据的实时性和可用性。
- 需要实时分析且支持全文检索: Log 和 Trace 数据中有大量的文本,如何在其中快速检索关键词和短语是该场景的核心需求。由于数据规模庞大,传统的全量扫描和字符串匹配方式在性能和扩展性上往往无法达到实时响应的要求,特别是在上述高吞吐低延迟实时写入的前提下,实时文本检索更加困难。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6457
6457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











