




导读:网易游戏引入 Apache Doris 升级架构,先是替换 Elasticsearch、Hbase、Clickhouse 构建了实时数仓,而后基于 Apache Doris 和 Iceberg 构建了湖仓融合架构,实现架构的大幅简化及统一。目前,网易游戏 Apache Doris 集群超 20 个 ,总节点数百个,已对接内部 200+ 项目,日均查询量超过 1500 万,总存储数据量 PB 级别。
近年来,随着网易游戏品类和产品的快速增加,数据规模呈现爆炸性增长,日均新增数据可达百 TB 级别。面对如此庞大的数据增长,如何高效、实时地提供数据分析成为一项重要挑战。网易游戏技术中心效能研发部的重点工作围绕数据、人工智能和安全展开,旨在通过数据和 AI 为公司众多游戏提供运营及决策支持,同时保护网易所有与游戏相关的产品、服务和资源的安全。这是推动游戏商业成功、品质提升以及渠道优化的重要支撑。
网易游戏早期数据平台是由 Hive、Spark、Trino、ElasticSearch、HBase、ClickHouse 多种技术栈组成,存在查询性能低、实时性不足、运维及研发成本高等问题。为此,引入 Apache Doris 进行架构升级,最初用 Doris 替换了 Elasticsearch、Hbase、Clickhouse,构建了实时数仓;随后基于 Apache Doris 和 Iceberg 构建了湖仓融合的架构,实现了数据架构的简化,数据的时效性和查询性能大幅提升。网易游戏 Apache Doris 集群超 20 个 ,总节点数百个,已对接内部 200+ 项目,日均查询量超过 1500 万,总存储数据量 PB 级别。
早期架构及痛点
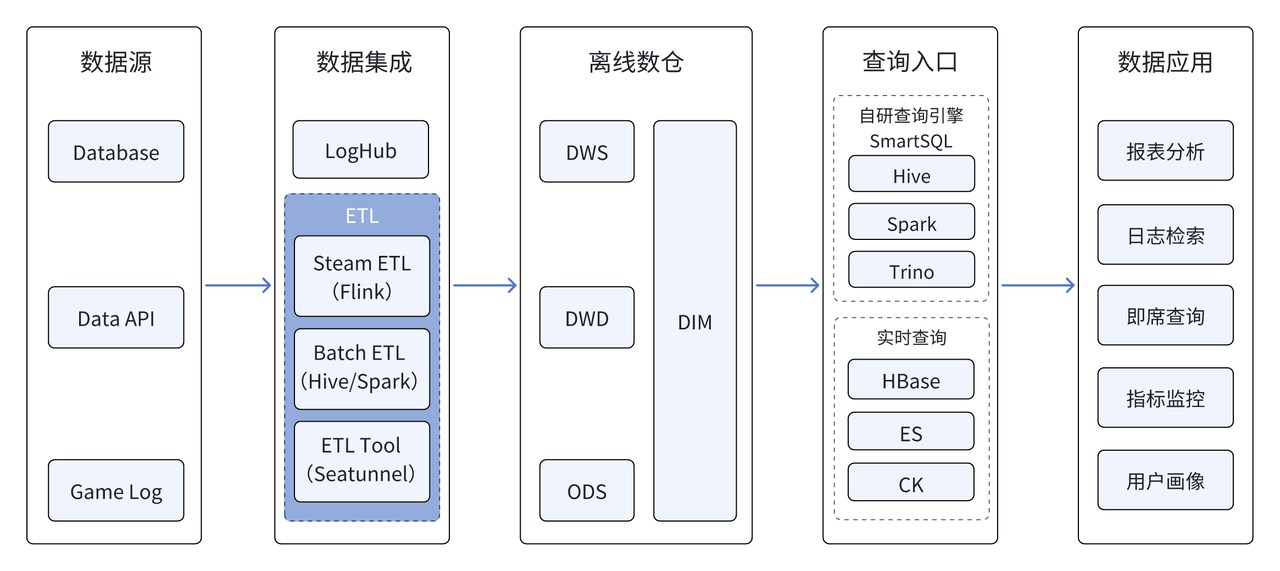
在早期架构中,大部分查询请求通过离线数据仓库(Hive)以及多种查询引擎(如 Hive、Spark 和 Trino)完成,而针对时效性要求更高的实时查询分析,则由 Elasticsearch、HBase 和 ClickHouse 提供支持。
这一架构在使用过程中暴露出了许多问题:
- 数据时效性差:该架构数据处理链路长,需要经过多次流转,时效性对实时分析业务满足比较吃力。
- 查询性能不优:依赖 Hive、Spark、Trino 等查询引擎的效率不够高;HBase、Elasticsearch、ClickHouse 对复杂查询支持非常有限。
- 运维成本高:涉及组件较多,包括 Hive、Spark、Trino、HBase、Elasticsearch、ClickHouse 等,运维复杂度相对较高,需要投入较多的人力。
- 研发成本高:过多的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











