



 随着互联网流量红利的减少,精细化运营成为趋势。本文详细介绍了AB测试的基本概念、实施步骤及注意事项,帮助读者掌握这一重要工具。
随着互联网流量红利的减少,精细化运营成为趋势。本文详细介绍了AB测试的基本概念、实施步骤及注意事项,帮助读者掌握这一重要工具。
随着互联网时代的流量红利、人口红利的逐渐减少,越来越多的产品运营开始关注一个词:精细化。
通俗来说,就是期望通过一些更细致的运营手段,产品方案,人群投放等方法机制,以期望获取稳定的业务增长。
而这其中最重要的方法之一,就是 AB-Test
01 什么是AB-Test
AB-Test起源于医学。
当一个药剂被研发后,医学工作人员需要确认其效果,是否达到预期,或者是否有其他副作用的影响。那怎么做呢?
用户被随机分组成两组,在不知情的情况下,拿到了测试用药和安慰剂。
经过一段时间的实验后,比较这两组病人的表象是否具有显著的差异,从而决定测试用药是否有效。这就是医学的“双盲实验”。
同样,这个“双盲实验”被互联网公司们拿过来在产品运营,算法推荐,交互设计,广告投放等各个领域中进行“X盲实验”。
即我们把将web或者app界面或者流程,拆分为多个版本,在同一时间段里,分别让同质化的用户使用。在达到统计最小样本量后,收集相关的数据,通过数学检验 和 业务评估,得出最优质的版本,达到效果最大化。
一句话概括AB-Test:运用数学的方式,结合业务的目的,通过流量分割的方式,得到一个可以使得效果最大化且置信的结论,并推广至全流量业务。
02 AB-Test 中的知识点
AB-Test包含了很多不同模块的知识点。
比如流量的分割,最小样本量计算,假设检验的方法,置信区间的计算等。
我们依次来说下这些常用知识点
• 流量的分割
简单来说,流量分割有两种:分流 or 分层
分流:即实验和实验之间不交叉,不会产生交集用户
这种做法,不适合整体场景都使用。
毕竟一个APP的流量是有限,但是实验个数可以是无限个。
这种分流,会把流量通过实验个数切分,每个实验之间倒是不影响了。
但是,样本量少了,实验周期长了。如果实验多一些,做一个AB实验,要测试1个月,你会不会担心自己的年终KPI?
分层:即实验和实验交叉,会产生交集用户
这种做法是纵向是实验,横向是实验分桶。
但是必须在每一层都重新打散。相当于同一个用户在处在不同的实验中。
由于本身实验之间的场景不会相互影响,所以分层其实是大多数时候建议的方案。
毕竟可以当前场景下的全流量,不会导致流量不够的问题。
分流的方法非常适合需要拆分业务场景的实验。
因为会导致实验相关联而相互影响。比如优惠券的发放,不同团队发放不同的的优惠券,一定要分流实验。这样保证优惠券之间不会相互影响。
分层的方法非常适合实验不会相互影响的场景。
比如产品功能改变,页面UI修改,产品和业务相互之间不影响,那么建议用分层。这样可以不断切分,保证流量的使用。
• 样本量计算
在预期条件下,要检测出这个指标“变化”,最小可信的样本量需要多少。
当然,网上有大量的样本量计算器。都是根据统计学中的提升比例和置信比例计算可以得到的。
• 假设检验
假设检验是先对总体参数提出一个假设值,然后利用样本信息判断这一假设是否成立。从而判断实验效果如何,是否达到目的。
当然,假设检验中还需要了解 两个假设、两类错误。
两个假设
• 原假设H0:实验中想反对的假设(即达不到实验目的)
• 备择假设H1:实验中想予以支持的假设(即实验的目的是啥就是啥)
两类错误
• 第一类错误:弃真错误,当原假设为真时拒绝原假设
• 第二类错误:取伪错误,当原假设为假时未拒绝原假设
检验度量
• P值:P值即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的P值,一般以P<0.05 为有统计学差异。
• 分布检验:一般大于等于1.96就有差异
• Z检验:Z检验常用于总体正态分布、方差已知或独立大样本的平均数的显著性和差异的显著性检验。
• T检验:t检验常用于总体正态分布、总体方差未知或独立小样本平均数的显著性检验、平均数差异显著性检验。
• 置信区间
置信区间是用来对一个概率样本的总体参数进行区间估计的样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平。
置信水平代表了估计的可靠度,一般来说使用95%的置信水平进行区间估计。
置信区间可以辅助确定版本间是否有存在显著差异的可能性:
• 置信区间上下限的值同正同负,认为存在有显著差异的可能性
• 置信区间上下限的值有负有正,认为不存在有显著差异的可能性
03 AB-Test 的制定步骤
我们先来看看整体AB测试的流程:
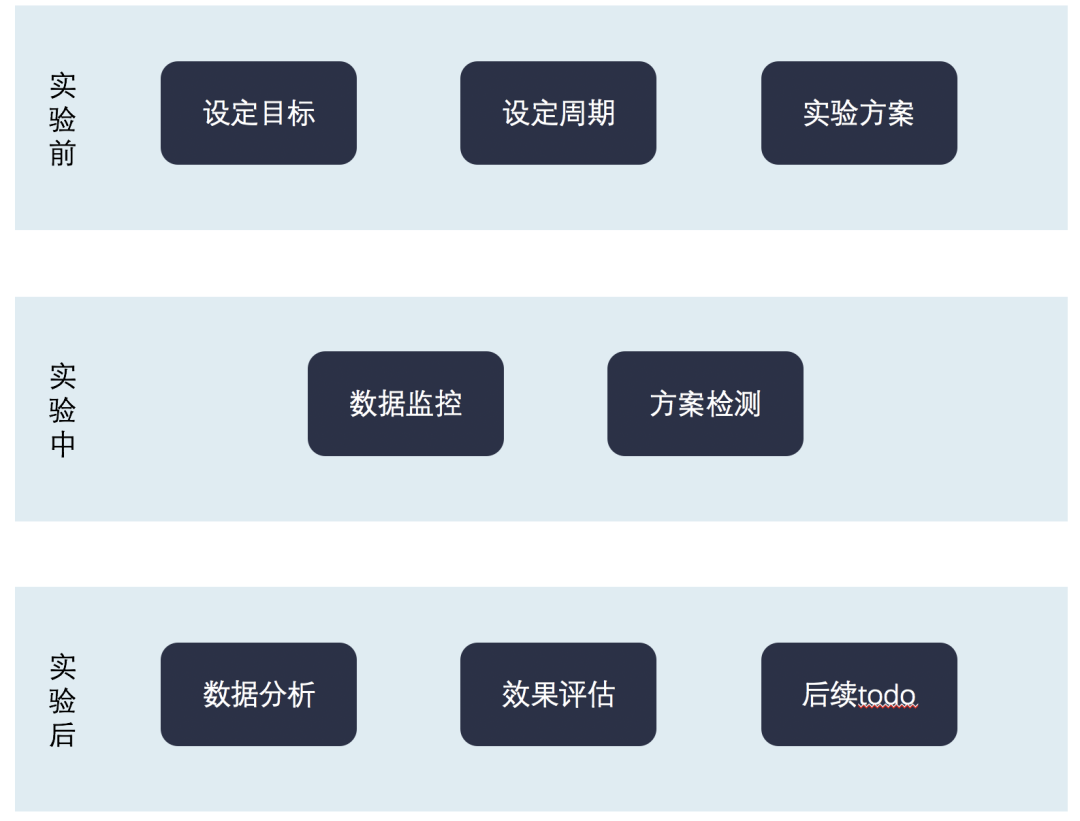
• 实验前
• 定目标 + 做实验设计
实验开始前,要先考量该实验需要解决什么问题;也就是目标是什么。有了目标,我们才能有接下来对应的指标和流量预估。
目标用户,最小样本量,实验周期,实验分流比例&周期,分组对应的策略等
• 实验期间
• 实验是否符合预期的校验
即对应的用户是不是就在一个桶里,ABN桶的策略是否生效,流量比例是否正确,在上线后,一定要校验线上是否生效。如果有问题,那么需要及时修改,这样才能保证在预期实验周期内拿到对应的数据
• 实验结束
• 效果评估 + 沉淀复盘
收集完成实验数据,我们要统计实验周期内的效果,看看是否有数据显著性差异,以及要确认下,是否有业务显著性差异。我们做的实验到底策略如何,是否要全量上线。
以及我们这次实验哪里做的不好,哪里做的好,流程机制如何,数据全链路里是否都能自动产出等等。为下一次更好的做AB-Test做准备
04 AB-Test 采坑集锦
• 时间&样本同质性
保证同一时间周期内观测实验结果
保证样本同质化,不要出现分流不均匀的问题
• 尽量有AA实验
做AB测试时,非常重要的就是分流均衡问题,我们可以通过AA实验来验证分流是否均衡
• 同一样本在同一实验中保持一个分桶
如果同一用户属多个分桶,不仅会对用户造成一定的“误导”,也会导致数据无法有效统计
• 实验时长尽量大于户活跃间隔周期
做AB测试时,尽量设定一个实验生效期,这个周期一般是用户的一个活跃间隔期
• 保证实验能达到最小样本量
如果样本量不足,则需要实验周期拉长,算整个实验周期内的数据
以上,就是今天讲述的AB测试相关的基础知识点,希望对你有帮助~

















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









