



零·简介
一、定义
图像检索:基于特征匹配(如SIFT、SURF、ORB)或深度学习模型(如CNN),从数据库中快速定位相似图像。
图像分割:将图像划分为多个有意义的区域(如前景/背景、物体部件),支持像素级分类。
二、划分
具体可做如下分类
| 技术类别 | 具体方法 | 适用场景 |
|---|---|---|
| 基于阈值的分割 | 全局阈值、自适应阈值、Otsu算法 | 光照均匀或局部对比度差异大的场景(如文档扫描、工业质检) |
| 基于边缘的分割 | Canny、Sobel、Prewitt算子 | 边界清晰的物体分割(如车牌识别、医学影像中的器官轮廓提取) |
| 基于区域的分割 | 区域生长、分水岭算法、SLIC超像素 | 纹理一致或空间连续的区域分割(如自然图像中的物体分离、遥感图像地物提取) |
| 基于聚类的分割 | K-means、Mean Shift、GrabCut | 无监督或半监督场景(如交互式图像编辑、复杂背景下的目标提取) |
| 基于图论的分割 | Graph Cut、Normalized Cut | 需要全局优化的场景(如医学影像中的器官分割、视频对象分割) |
| 深度学习分割 | FCN、U-Net、Mask R-CNN、DeepLab系列 | 高精度语义分割(如自动驾驶中的道路检测、医疗影像中的病灶定位) |
| 图像检索技术 | 特征点匹配(SIFT/SURF/ORB)、词袋模型(BoW)、深度学习嵌入(如ResNet特征) | 图像数据库搜索、版权保护、安防监控中的目标再识别 |
三、价值
- 效率提升
- 自动化处理替代人工标注,降低时间成本(如工业质检中缺陷检测速度提升90%)。
- 深度学习模型实现实时分割(如自动驾驶中道路检测延迟<50ms)。
- 精度优化
- 语义分割模型(如U-Net)在医学影像中达到98%的像素级准确率。
- 分水岭算法结合形态学操作,可分离重叠物体(如细胞计数误差率<2%)。
- 成本降低
- 开源库减少商业软件授权费用,适合中小企业部署。
- 轻量级模型(如MobileNetV3+DeepLab)可在移动端运行,降低硬件成本。
- 应用扩展
- 支持跨领域创新(如农业中通过遥感图像分割监测作物生长,医疗中通过CT图像分割辅助手术规划)。
四、应用场景
- 医疗影像分析
- 病灶定位:U-Net分割CT图像中的肿瘤区域,辅助放射科医生诊断。
- 细胞计数:阈值分割+连通区域分析,统计血液涂片中的白细胞数量。
- 工业缺陷检测
- 金属表面检测:自适应阈值分割结合轮廓分析,定位裂纹、划痕。
- 电子元件质检:GrabCut算法提取芯片引脚,检测焊接缺陷。
- 自动驾驶
- 道路可行驶区域分割:DeepLabv3+模型识别车道线、人行道。
- 交通标志检测:语义分割+目标检测,识别限速牌、红绿灯。
- 增强现实(AR)
- 背景替换:GrabCut算法分离人物与背景,实现虚拟直播特效。
- 物体交互:SLIC超像素分割跟踪手势,控制AR游戏角色。
- 遥感与地理信息
- 地物提取:分水岭算法分割卫星图像中的建筑物、水体、植被。
- 灾害评估:语义分割统计洪水淹没区域,辅助救援决策。
五、选型建议
- 简单场景:优先选择阈值分割或边缘检测(如文档扫描、基础质检)。
- 复杂背景:使用聚类方法(如K-means)或分水岭算法(如重叠物体分离)。
- 高精度需求:部署深度学习模型(如U-Net用于医学影像,Mask R-CNN用于实例分割)。
- 实时性要求:采用轻量级模型(如MobileNetV3+SSDLite)或优化后的传统算法。
六、发展趋势
- AI融合加速:传统算法与深度学习结合(如DeepLab系列集成CRF后处理)。
- 实时性优化:模型量化、剪枝技术推动分割模型在移动端部署。
- 3D分割突破:点云数据处理技术(如PointNet++)支持自动驾驶中的三维场景理解。
- 小样本学习:少样本/零样本分割方法减少对大量标注数据的依赖。
ps:
《数学建模算法与应用》————司守奎|2011年国防工业出版社
《计算机视觉:算法与应用》—————Richard Szeliski、艾海舟|2012年清华大学出版社
壹·轮廓发现与绘制
图像轮廓是一系列相连的点组成的曲线,代表物体的基本外形。轮廓与边缘的区别在于,轮廓是连续的,边缘并不全部连续。轮廓发现的操作一般用于二值化图,所以通常会使用阈值分割或Canny边缘检测先得到二值图。注意,轮廓发现是针对白色物体的,一定要保证物体是白色,而背景是黑色,不然寻找轮廓时会找到图片外围的框。
一、轮廓发现的基本步骤
-
图像预处理:
- 将彩色图像转换为灰度图像,便于后续处理。使用
Imgproc.cvtColor()函数实现。 - 使用边缘检测算法(如Canny)或阈值分割算法(如
Imgproc.threshold())将灰度图像转换为二值图像,这是轮廓发现的前提。
- 将彩色图像转换为灰度图像,便于后续处理。使用
-
轮廓发现:
- 使用
Imgproc.findContours()函数在二值图像中查找轮廓。该函数接受二值图像、轮廓检索模式和轮廓逼近方法作为参数,返回检测到的轮廓列表和轮廓层级信息。
- 使用
-
轮廓绘制:
- 使用
Imgproc.drawContours()函数将检测到的轮廓绘制到原始图像或复制的图像上。该函数接受目标图像、轮廓列表、轮廓索引、颜色、线条粗细等参数。
- 使用
二、轮廓层级的概念
轮廓层级(Contour Hierarchy)描述了图像中轮廓之间的包含关系和顺序关系。在包含多个轮廓的图像中,轮廓之间可能存在父子关系、兄弟关系等。OpenCV使用一个四维数组来表示轮廓层级,每个元素的结构为[Next, Previous, First_Child, Parent],其中:
Next:同一层级上的下一个轮廓的索引。Previous:同一层级上的前一个轮廓的索引。First_Child:当前轮廓的第一个子轮廓的索引。Parent:当前轮廓的父轮廓的索引。
三、不同的轮廓检索模式及其应用场景
-
RETR_EXTERNAL
- 描述:只检索最外面的轮廓,忽略所有子轮廓。
- 应用场景:当只需要检测图像中的主要对象时,如检测文档中的表格、卡片等。
2. RETR_LIST:
- 描述:
检索所有的轮廓,并将它们保存到一条链表当中,不建立任何轮廓之间的层级关系。 - 应用场景:
需要检测图像中的所有轮廓,但不关心它们之间的层级关系时,如统计图像中的对象数量。
3. RETR_CCOMP:
- 描述:
检索所有的轮廓,并将它们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界。 - 应用场景:
当需要区分对象的外边界和内部空洞时,如检测带有孔洞的物体。
4. RETR_TREE:
- 描述:
检索所有的轮廓,并重构嵌套轮廓的整个层次结构。 - 应用场景:
当需要完整理解图像中轮廓之间的嵌套关系时,如检测复杂的嵌套对象或进行精细的图像分割。
四、相关的API使用
-
Imgproc.findContours():- 参数:
image:输入的二值图像。contours:检测到的轮廓列表,每个轮廓是一个MatOfPoint对象。hierarchy:轮廓层级信息,是一个Mat对象。mode:轮廓检索模式,如Imgproc.RETR_EXTERNAL、Imgproc.RETR_LIST等。method:轮廓逼近方法,如Imgproc.CHAIN_APPROX_SIMPLE(压缩水平、垂直和对角分割,只保留末端点)。
- 返回值:无直接返回值,但会填充
contours和hierarchy参数。
- 参数:
-
Imgproc.drawContours():- 参数:
image:要在其上绘制轮廓的目标图像。contours:轮廓列表。contourIdx:要绘制的轮廓的索引。如果为-1,则绘制所有轮廓。color:轮廓的颜色,以Scalar对象表示,如new Scalar(0, 0, 255)表示红色。thickness:轮廓线的粗细。如果为负值(如Imgproc.FILLED),则填充轮廓所限制的区域。
- 返回值:无。
- 参数:
五、示例代码
import org.opencv.android.Utils;
import org.opencv.core.Core;
import org.opencv.core.Mat;
import org.opencv.core.MatOfPoint;
import org.opencv.core.Scalar;
import org.opencv.core.CvType;
import org.opencv.imgproc.Imgproc;
import org.opencv.android.BaseLoaderCallback;
import org.opencv.android.LoaderCallbackInterface;
import org.opencv.android.OpenCVLoader;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.os.Bundle;
import android.app.Activity;
import android.widget.ImageView;
import java.util.ArrayList;
import java.util.List;
public class ContourDetectionActivity extends Activity {
private ImageView imageView;
private Mat srcImage, grayImage, edges, dstImage;
private List<MatOfPoint> contours;
private Mat hierarchy;
static {
if (!OpenCVLoader.initDebug()) {
// 处理OpenCV初始化失败的情况
}
}
private BaseLoaderCallback mLoaderCallback = new BaseLoaderCallback(this) {
@Override
public void onManagerConnected(int status) {
switch (status) {
case LoaderCallbackInterface.SUCCESS:
// OpenCV加载成功,执行图像处理
runOnUiThread(new Runnable() {
@Override
public void run() {
processImage();
}
});
break;
default:
super.onManagerConnected(status);
break;
}
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_contour_detection);
imageView = findViewById(R.id.imageView);
// 加载图像
Bitmap bitmap = BitmapFactory.decodeResource(getResources(), R.drawable.test_image);
srcImage = new Mat(bitmap.getHeight(), bitmap.getWidth(), CvType.CV_8UC3);
Utils.bitmapToMat(bitmap, srcImage);
// 加载OpenCV库
if (!OpenCVLoader.initDebug()) {
OpenCVLoader.initAsync(OpenCVLoader.OPENCV_VERSION, this, mLoaderCallback);
} else {
mLoaderCallback.onManagerConnected(LoaderCallbackInterface.SUCCESS);
}
}
private void processImage() {
// 转灰度图像
grayImage = new Mat();
Imgproc.cvtColor(srcImage, grayImage, Imgproc.COLOR_BGR2GRAY);
// 边缘检测(可选,根据实际需求决定是否使用)
edges = new Mat();
Imgproc.Canny(grayImage, edges, 50, 150);
// 如果不使用Canny边缘检测,可以直接对灰度图像进行阈值分割
// Imgproc.threshold(grayImage, edges, 127, 255, Imgproc.THRESH_BINARY);
// 查找轮廓
contours = new ArrayList<>();
hierarchy = new Mat();
Imgproc.findContours(edges, contours, hierarchy, Imgproc.RETR_TREE, Imgproc.CHAIN_APPROX_SIMPLE);
// 绘制轮廓
dstImage = srcImage.clone();
Imgproc.drawContours(dstImage, contours, -1, new Scalar(0, 0, 255), 2);
// 显示结果
Bitmap resultBitmap = Bitmap.createBitmap(dstImage.cols(), dstImage.rows(), Bitmap.Config.ARGB_8888);
Utils.matToBitmap(dstImage, resultBitmap);
imageView.setImageBitmap(resultBitmap);
}
@Override
protected void onResume() {
super.onResume();
if (!OpenCVLoader.initDebug()) {
OpenCVLoader.initAsync(OpenCVLoader.OPENCV_VERSION, this, mLoaderCallback);
} else {
mLoaderCallback.onManagerConnected(LoaderCallbackInterface.SUCCESS);
}
}
}贰·轮廓面积与周长
轮廓面积与周长轮廓面积和轮廓周长都是轮廓的重要统计特征。轮廓面积是指每个轮廓中所有像素点围成区域的面积,单位为像素。轮廓周长是指每个轮廓中所有像素点围成区域的周长,单位同样为像素。通过分析轮廓面积和轮廓周长,我们可以区分物体的大小,识别物体的不同,同时还能分析出一些其他内容,例如,正方形区域的周长和面积是有固定关系的,圆形区域的周长和面积是有固定关系的。通过计算轮廓面积和周长,再结合这些固定关系,我们是可以得到一些结论的。
// 1. 图像预处理(灰度化+二值化)
Mat gray = new Mat();
Imgproc.cvtColor(srcMat, gray, Imgproc.COLOR_BGR2GRAY);
Mat binary = new Mat();
Imgproc.threshold(gray, binary, 127, 255, Imgproc.THRESH_BINARY);
// 2. 查找轮廓
List<MatOfPoint> contours = new ArrayList<>();
Mat hierarchy = new Mat();
Imgproc.findContours(binary, contours, hierarchy, Imgproc.RETR_TREE, Imgproc.CHAIN_APPROX_SIMPLE);
// 3. 计算轮廓面积和周长
for (int i = 0; i < contours.size(); i++) {
MatOfPoint contour = contours.get(i);
// 面积计算
double area = Imgproc.contourArea(contour);
// 周长计算
MatOfPoint2f contour2f = new MatOfPoint2f(contour.toArray());
double perimeter = Imgproc.arcLength(contour2f, true);
Log.d("ContourMetrics", "轮廓" + i + " - 面积: " + area + ", 周长: " + perimeter);
}叁·轮廓外接多边形
前面我们提到轮廓发现、轮廓周长以及轮廓面积,然后通过轮廓面积和周长的固定关系来判断轮廓形状。但是针对不规则的形状,其实我们是很难通过数量关系来进行判断的。参考之前直线拟合的方式,我们也可以通过形状拟合的方式来对轮廓进行一定的分析。最常见的是将轮廓拟合成矩形等多边形。
一、核心API详解
1. 最大外接矩形
- API:
Imgproc.boundingRect(MatOfPoint points) - 参数:
points:轮廓点集合(MatOfPoint类型)。
- 返回值:
Rect对象,包含矩形的左上角坐标(x, y)、宽度(width)和高度(height)。 - 用途:获取轮廓的轴对齐(横平竖直)外接矩形,适用于快速定位物体位置。
2. 最小外接矩形(旋转矩形)
- API:
Imgproc.minAreaRect(MatOfPoint2f points) - 参数:
points:轮廓点集合(需转换为MatOfPoint2f类型)。
- 返回值:
RotatedRect对象,包含矩形的中心点(center)、尺寸(size)和旋转角度(angle)。 - 用途:获取轮廓的最小面积外接矩形,可能旋转一定角度,更精确地包裹轮廓。
3. 轮廓多边形逼近
- API:
Imgproc.approxPolyDP(MatOfPoint2f curve, MatOfPoint2f approxCurve, double epsilon, boolean closed) - 参数:
curve:输入轮廓点集合(MatOfPoint2f类型)。approxCurve:输出逼近多边形的顶点集合。epsilon:逼近精度,表示原始曲线与逼近曲线之间的最大距离(值越小,逼近越精确)。closed:是否闭合多边形(true表示闭合)。
- 用途:通过Douglas-Peucker算法减少轮廓点数量,同时保持形状的主要特征。
二、操作步骤
1. 图像预处理
将彩色图像转换为灰度图像java
使用阈值分割或边缘检测(如Canny)生成二值图像
2. 查找轮廓
使用Imgproc.findContours()查找轮廓
3. 获取最大外接矩形
遍历轮廓,调用boundingRect():
for (int i = 0; i < contours.size(); i++) {
Rect rect = Imgproc.boundingRect(contours.get(i));
// 绘制矩形
Imgproc.rectangle(dstMat, rect, new Scalar(0, 255, 0), 2);
}4. 获取最小外接矩形
将轮廓点转换为MatOfPoint2f,调用minAreaRect():
for (int i = 0; i < contours.size(); i++) {
MatOfPoint2f contour2f = new MatOfPoint2f(contours.get(i).toArray());
RotatedRect minRect = Imgproc.minAreaRect(contour2f);
// 获取旋转矩形的四个顶点
Point[] vertices = new Point[4];
minRect.points(vertices);
// 绘制旋转矩形
for (int j = 0; j < 4; j++) {
Imgproc.line(dstMat, vertices[j], vertices[(j + 1) % 4], new Scalar(0, 0, 255), 2);
}
}5. 轮廓多边形逼近
调用approxPolyDP()减少轮廓点数量:
for (int i = 0; i < contours.size(); i++) {
MatOfPoint2f contour2f = new MatOfPoint2f(contours.get(i).toArray());
MatOfPoint2f approxCurve = new MatOfPoint2f();
double epsilon = 0.02 * Imgproc.arcLength(contour2f, true); // 精度与轮廓周长相关
Imgproc.approxPolyDP(contour2f, approxCurve, epsilon, true);
// 绘制逼近多边形
Point[] approxPoints = approxCurve.toArray();
for (int j = 0; j < approxPoints.length; j++) {
Point p1 = approxPoints[j];
Point p2 = approxPoints[(j + 1) % approxPoints.length];
Imgproc.line(dstMat, p1, p2, new Scalar(255, 0, 0), 2);
}
}三、实现效果
- 最大外接矩形:
- 矩形与坐标轴对齐,快速定位物体边界,但可能包含较多空白区域。
- 示例:检测文档时,矩形可能包含文档周围的空白。
- 最小外接矩形:
- 矩形可能旋转,紧密包裹轮廓,适合精确测量物体尺寸。
- 示例:检测倾斜的卡片时,旋转矩形能准确计算卡片的实际尺寸。
- 轮廓多边形逼近:
- 减少轮廓点数量(如从1000点减少到20点),同时保持形状特征。
- 示例:简化复杂的树叶轮廓,便于后续形状分析或识别。
四、关键注意事项
- 数据类型转换:
minAreaRect()和approxPolyDP()需要MatOfPoint2f类型,需通过toArray()转换。
- 精度控制:
epsilon值影响多边形逼近的精度,需根据实际需求调整(如epsilon = 0.01 * 轮廓周长)。
- 性能优化:
- 对大量轮廓处理时,可提前过滤小面积轮廓(通过
contourArea())。
- 对大量轮廓处理时,可提前过滤小面积轮廓(通过
- 结果展示:
- 使用
Imgproc.rectangle()、Imgproc.line()等API将结果绘制到图像上,便于调试和验证。
- 使用
肆·凸包检测
凸包(Convex Hull)是一个计算几何(图形学)中的概念。在一个实数向量空间V中,对于给定集合X,所有包含X的凸集的交集S被称为X的凸包(就是包含所有 X元素的最小凸集)。X的凸包可以用X内所有点(X1,…Xn)的凸组合来构造.在二维欧几里得空间中,凸包可想象为一条刚好包着所有点的橡皮圈。用不严谨的话来讲,给定二维平面上的点集,凸包就是将最外层的点连接起来的凸多边形,它能包含点集中的所有的点。
操作步骤与实现效果
1. 凸包检测流程
- 步骤:
- 获取点集(如轮廓点)。
- 调用
convexHull计算凸包顶点索引。 - 根据索引提取凸包点集,绘制凸包多边形。
- 效果:
凸包多边形紧密包裹点集,顶点按顺时针或逆时针顺序排列,适用于形状分析、碰撞检测等场景。
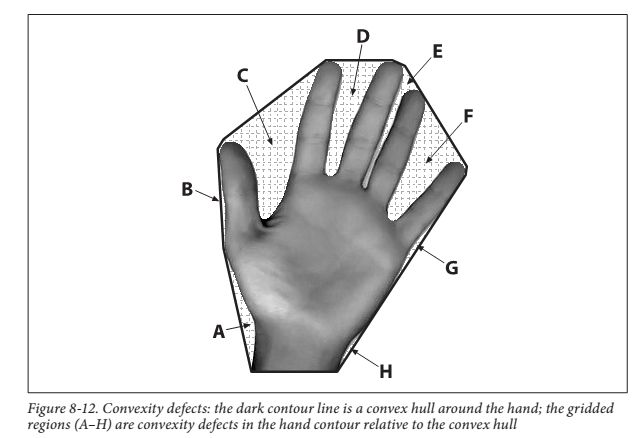
2. 凸包缺陷分析流程
- 步骤:
- 获取原始轮廓点和凸包顶点索引。
- 调用
convexityDefects计算缺陷点信息。 - 解析缺陷点数据(起点、终点、最远点、深度),标记凹陷区域。
- 效果:
缺陷点信息可量化凹陷程度,用于手势识别(如手指间隙)、物体破损检测等场景。
示例代码(Android环境)
// 凸包检测
MatOfPoint points = ...; // 输入点集
MatOfInt hull = new MatOfInt();
Imgproc.convexHull(new MatOfPoint2f(points.toArray()), hull, false, true);
// 提取凸包点集
List<Point> hullPoints = new ArrayList<>();
for (int i = 0; i < hull.rows(); i++) {
int index = hull.get(0, i)[0];
hullPoints.add(points.toArray()[index]);
}
// 绘制凸包
MatOfPoint hullMat = new MatOfPoint(hullPoints.toArray(new Point[0]));
Imgproc.drawContours(dstMat, new ArrayList<MatOfPoint>() {{ add(hullMat); }}, -1, new Scalar(0, 255, 0), 2);
// 凸包缺陷分析
MatOfInt4 defects = new MatOfInt4();
Imgproc.convexityDefects(points, hull, defects);
int[] defectArray = defects.toArray();
for (int i = 0; i < defectArray.length; i += 4) {
Point start = new Point(defectArray[i], defectArray[i+1]);
Point end = new Point(defectArray[i+2], defectArray[i+3]);
Point farthest = new Point(defectArray[i+4], defectArray[i+5]);
double depth = defectArray[i+6];
// 绘制缺陷点
Imgproc.line(dstMat, start, end, new Scalar(0, 0, 255), 2);
Imgproc.circle(dstMat, farthest, 5, new Scalar(255, 0, 0), -1);
}关键注意事项
- 数据类型转换:
convexHull和convexityDefects需要MatOfPoint2f类型输入,需通过toArray()转换。
- 顺序方向:
clockwise参数控制凸包顶点顺序,需根据后续处理需求设定。
- 缺陷点解析:
defects输出为int[]数组,每4个元素代表一个缺陷点(起点、终点、最远点、深度)。
- 性能优化:
- 对大量点集处理时,可提前过滤无效点或降低分辨率。
通过凸包检测和缺陷分析,可实现精确的形状描述和异常检测,适用于手势识别、工业质检、医学影像分析等场景。
伍·模板匹配
什么是模板匹配?模板匹配是一种用于在较大图像中搜索和查找模板图像位置的方法。OpenCV提供matchTemplate()方法来实现模板匹配功能。模板匹配结果返回的是灰度图像,其中每个像素表示该像素的邻域与模板匹配程度。假设输入图像的大小(W * H),模板图像的大小为(w * h),则输出图像的大小将为(W-w+1.H-h+1)。获得结果后、可以使用 minmaxLoc()方法查找最大/最小值位置,并将其作为矩形的左上角,以(w,h)作为矩形的宽度和高度来确定模板匹配到的区域。
一、模板匹配原理
模板匹配的核心思想是通过滑动模板图像在大图中遍历所有可能的位置,计算每个位置的相似度,最终确定最佳匹配区域。具体步骤如下:
- 滑动窗口遍历:将模板图像(尺寸为w×h)在大图(尺寸为W×H)上从左到右、从上到下滑动,生成所有可能的子区域(尺寸为w×h)。
- 相似度计算:对每个子区域与模板图像进行像素级比较,计算匹配度得分。
- 结果矩阵生成:输出一个尺寸为(W−w+1)×(H−h+1)的灰度矩阵,每个像素值表示对应位置的匹配度。
- 最佳位置定位:通过
minMaxLoc()函数在结果矩阵中查找最大值或最小值(取决于匹配方法),确定模板在大图中的位置。
二、OpenCV API核心函数
OpenCV通过Imgproc.matchTemplate()函数实现模板匹配,其参数和用法如下:
public static void matchTemplate(Mat image, Mat templ, Mat result, int method, Mat mask)
参数说明:image:待匹配的大图(8位或32位浮点图像)。templ:模板图像(类型与image一致,尺寸需小于image)。result:输出结果矩阵(单通道32位浮点数,尺寸为(W−w+1)×(H−h+1))。method:匹配方法标志位(如TM_SQDIFF、TM_CCORR_NORMED等)。mask(可选):掩码图像,用于指定模板中参与计算的区域。
三、匹配方法详解
OpenCV提供了6种匹配方法,分为三类:平方差匹配、相关匹配和相关系数匹配。不同方法适用于不同场景,需根据实际需求选择。
1. 平方差匹配(Square Difference)
-
方法:
TM_SQDIFF:计算模板与子区域的平方差和,值越小匹配度越高。TM_SQDIFF_NORMED:归一化平方差,结果范围为[0,1],0表示完全匹配。
-
公式:
-
归一化版本:
- 适用场景:
- 目标与背景颜色差异明显(如黑白对比)。
- 对光照变化敏感,需在稳定光照条件下使用。
2. 相关匹配(Correlation)
-
方法:
TM_CCORR:计算模板与子区域的乘积和,值越大匹配度越高。TM_CCORR_NORMED:归一化相关匹配,结果范围为[0,1],1表示完全匹配。
-
公式:
-
归一化版本:
- 适用场景:
- 目标与背景颜色分布接近(如低对比度场景)。
- 对亮度变化敏感,需在均匀光照下使用。
3. 相关系数匹配(Correlation Coefficient)
-
方法:
TM_CCOEFF:计算模板与子区域的相关系数,值越大匹配度越高。TM_CCOEFF_NORMED:归一化相关系数,结果范围为[−1,1],1表示完全匹配。
-
公式:
其中:
归一化版本:
- 适用场景:
- 背景复杂或目标与背景亮度差异大(如户外场景)。
- 归一化版本对光照变化和尺度变化更鲁棒。
四、实现步骤与代码示例
以下是在Android中实现模板匹配的完整步骤:
-
集成OpenCV库:
-
加载图像:
-
执行模板匹配:
Mat result = new Mat(); int method = Imgproc.TM_CCOEFF_NORMED; // 选择匹配方法 Imgproc.matchTemplate(srcImage, template, result, method); -
定位最佳匹配:
Core.MinMaxLocResult mmr = Core.minMaxLoc(result); Point matchLoc; if (method == Imgproc.TM_SQDIFF || method == Imgproc.TM_SQDIFF_NORMED) { matchLoc = mmr.minLoc; // 平方差法取最小值 } else { matchLoc = mmr.maxLoc; // 其他方法取最大值 } -
绘制匹配结果:
Rect rect = new Rect(matchLoc, new Size(template.cols(), template.rows())); Imgproc.rectangle(srcImage, rect, new Scalar(0, 255, 0), 2); Imgcodecs.imwrite("path/to/result.jpg", srcImage);
五、性能优化与局限性
- 性能优化:
- 降低分辨率:对大图进行下采样(如
Imgproc.resize())以减少计算量。 - 多尺度匹配:结合金字塔分层搜索(如
Imgproc.pyrDown())加速匹配。 - 并行计算:利用OpenCV的并行框架(如
TBB或OpenMP)。
- 降低分辨率:对大图进行下采样(如
- 局限性:
- 旋转与缩放:模板匹配对旋转和缩放敏感,需结合特征点匹配(如SIFT、ORB)解决。
- 光照变化:非归一化方法(如
TM_CCORR)在光照变化下效果差,建议使用归一化版本。 - 复杂背景:相关系数匹配(如
TM_CCOEFF_NORMED)对背景干扰更鲁棒。
六、应用场景
- 文档扫描:定位固定格式的表格或印章。
- 工业检测:检测产品表面缺陷或标识。
- AR导航:识别现实场景中的标记物。
- 视频监控:跟踪特定目标(如车牌、人脸)。
通过合理选择匹配方法和优化策略,模板匹配技术能够在Android平台上实现高效、准确的图像定位,为各类计算机视觉应用提供基础支持。
陆·QR二维码检测与识别
QR二维码
QR码(英语:Quick Response Code;全称为快速响应矩阵图码)是二维码的一种,于1994年由日本DENSO WAVE公司发明,。QR来自英文Quick Response的缩写,即快速反应,因为发明者希望QR码可以快速解码其内容。QR码使用四种标准化编码模式(数字、字母数字、字节(二进制)和日文(Shit J1s))来存储数据。QR码常见于日本,为目前日本最通用的二维空间条码、在世界各国广泛运用于手机读码操作。QR码比普通一维条码具有快速读取和更大的存储资料容量,也无需要像一维条码般在扫描时需要直线对准扫描仪。因此其应用范围已经扩展到包括产品跟踪,物品识别,文档管理,库存营销等方面。
QR二维码的格式和结构
QR码(Quick Response Code)即快速响应矩阵图码,是一种矩阵式二维条码,其核心结构包含以下部分:
- 定位图案(Finder Patterns):位于二维码的三个角落,由黑白相间的同心矩形组成,用于快速定位二维码的方向和位置。这些图案最大的特别之处在于任何一条经过中心的直线其在黑色和白色区域的长度比值都为1:1:3:1:1。
- 对齐图案(Alignment Patterns):小型黑白矩形,辅助校正因透视变形导致的图像畸变。根据二维码版本和尺寸的不同,对齐区域的数目也不尽相同。
- 编码区域(Data Modules):存储实际数据及纠错码,采用Reed-Solomon编码实现容错,最高可恢复约30%的损坏数据。
- 计算模式(Timing Pattern):通过这些线,扫描器可以识别矩阵有多大。
- 版本信息(Version Information):指定正在使用的QR码的版本号,目前有40个不同的版本号,用于销售行业的版本号通常为1-7。
- 格式信息(Format Information):包含关于容错和数据掩码模式的信息,并使得扫描代码更加容易。
- 宁静区域(Quiet Zone):对于扫描器来说非常重要,它的作用就是将自身与周边的进行分离。
OpenCV中的QRCodeDetector类结构
OpenCV中的QRCodeDetector类提供了用于二维码检测和识别的API,其主要方法包括:
-
detect():用于检测图像中是否包含QR二维码,并返回二维码的四个顶点坐标。- 参数:
img:待检测的灰度图像或者彩色(BGR)图像。points:检测到的QR二维码的最小区域四边形的四个顶点坐标集合。
- 返回值:布尔类型,
true代表检测到QR二维码,false代表未检测到。
- 参数:
-
decode():用于解码已检测到的QR二维码中的信息。- 参数:
img:含有QR二维码的灰度图像或者彩色(BGR)图像。points:detect方法得到的points值,数据量不可为空。straight_qrcode:经过矫正和二值化的QR二维码(可选)。
- 返回值:字符串类型,如果解码失败,则为空串。
- 参数:
-
detectAndDecode():同时执行检测和解码操作,一步完成二维码的定位和识别。- 参数:
img:含有QR二维码的灰度图像或者彩色(BGR)图像。points:检测到的QR二维码的最小区域四边形的四个顶点坐标(可选)。straight_qrcode:经过矫正和二值化的QR二维码(可选)。
- 返回值:字符串类型,如果解码失败,则为空串。
- 参数:
-
detectMulti()与decodeMulti():用于处理图像中的多个二维码。
检测和识别的具体步骤
在Android中使用OpenCV进行QR二维码的检测与识别,可以按照以下步骤进行:
-
集成OpenCV库
-
加载图像
Mat srcImage = Imgcodecs.imread("path/to/source.jpg"); -
创建QRCodeDetector对象
QRCodeDetector qrDetector = new QRCodeDetector(); -
执行检测与解码
String decodedInfo = qrDetector.detectAndDecode(srcImage); //或者,如果需要获取二维码的顶点坐标和矫正后的图像,可以使用以下方式: Mat points = new Mat(); Mat straightQrcode = new Mat(); String decodedInfo = qrDetector.detectAndDecode(srcImage, points, straightQrcode); -
处理检测结果
if (!decodedInfo.isEmpty()) { // 解码成功,处理解码后的信息 Log.d("QRCodeDetector", "Decoded Info: " + decodedInfo); } else { // 解码失败 Log.d("QRCodeDetector", "Failed to decode QR code"); } -
绘制边界框(可选)
if (!points.empty()) { List<MatOfPoint> contourList = new ArrayList<>(); contourList.add(new MatOfPoint(points.toArray())); Imgproc.polylines(srcImage, contourList, true, new Scalar(0, 255, 0), 2); } -
显示或保存结果
Imgcodecs.imwrite("path/to/result.jpg", srcImage);
柒·图像分割(漫水填充法)
图像分割
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。它是由图像处理到图像分析的关键步骤。现有的图像分割方法主要分以下几类:基于阈值的分割方法(固定阈值、自适应阈值、二值化)、基于区域的分割方法、基于边缘的分割方法
以及基于特定理论的分割方法等。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。图像分割的过程也是一个标记过程,即把属于同一区域的像素赋予相同的编号。
漫水填充法
漫水填充算法是根据像素灰度值之间的差值寻找相同区域实现分割。我们可以将图像的灰度值理解成像素点的高度,这样一张图像可以看成崎岖不平的地面或者山区,向地面上某一个低洼的地方倾倒一定量的水,水将会掩盖低于某个高度的区域。漫水填充法利用的就是这样的原理,其形式与注水相似,因此被称形象的称为“漫水”。
与向地面注水一致,漫水填充法也需要在图像选择一个注水像素,该像素被称为种子点,种子点按照一定规则不断向外扩散,从而形成具有相似特征的独立区域,进而实现图像分割。漫水填充分割法主要分为以下三个步骤:
。选择种子点(x,y);
。以种子点为中心,判断4邻域或者8邻域的像素值与种子点像素值的差值,将差值小于阈值的像素点添加进区域内。。
将新加入的像素点作为新的种子点,反复执行第二步,直到没有新的像素点被添加进该区域
捌·图像分割(分水岭法)
图像的灰度空间很像地球表面的整个地理结构,每个像素的灰度值代表高度。其中的灰度值较大的像素连成的线可以看做山脊,也就是分水岭。其中的水就是用于二值化的gray threshold level,二值化阈值可以理解为水平面,比水平面低的区域会被淹没,刚开始用水填充每个孤立的山谷(局部最小值)。
当水平面上升到一定高度时,水就会溢出当前山谷,可以通过在分水岭上修大坝,从而避免两个山谷的水汇集,这样图像就被分成2个像素集,一个是被水淹没的山谷像素集,一个是分水岭线像素集。最终这些大坝形成的线就对整个图像进行了分区,实现对图像的分割。
https://zhuanlan.zhihu.com/p/67741538
玖·图像分割(Grabcut)
GraphCut需要用户提供精确的前景背景的种子,而且当提供的种子无法覆盖所有分布时,必然会影响分割的准确度。为了解决这个问题,微软研究室提出了更加快捷高效的GrabCut分割算法。GrabCut需要用户提供一个矩形,矩形内为前景,矩形外为背景。GrabCut具体步骤如下:
1:矩形外的像素作为背景,矩形内的像素作为前景,用这两组去训练背景GMM和前景GMM(这里GMM指高斯混合模型);
2:用训练好的两个GMM来计算每一个像素属于背景和属于前景的概率,进而计算出能量函数E中的Data项,能量函数中的Smoothiness项的计算方法大致与GraphCut相同;
3:通过最优化能量函数得到图像的一个分割;
4:用3中的分割结果中的前景Pixels和背景Pixels去训练前景GMM和背景GMM:
5:重复2,3,4,直到分割结果收敛(不再有大的变化)。
拾·图像分割(均值漂移)
MeanShfit 均值漂移算法是一种通用的聚类算法,通常可以实现彩色图像分割。
基本思想为:首先随便选择一个中心点,然后计算该中心点一定范围之内所有点到中心点的距离向量的平均值,计算该平均值得到一个信移均值,然后将中心点移动到偏移均值位置,通过这种不断重复的移动,可以使中心点逐步逼近到最佳位置。这种思想类似于梯度下降方法,通过不断的往梯度下降的方向移动,可以到达梯度上的局部最优解或全局最优解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









