



 本文通过数据预处理、探索性分析、散点图绘制和回归模型建立,揭示了工资与教育、年龄等变量的关系,并特别分析了性别对教育与工资间关系的影响。
本文通过数据预处理、探索性分析、散点图绘制和回归模型建立,揭示了工资与教育、年龄等变量的关系,并特别分析了性别对教育与工资间关系的影响。
1、数据准备
import urllib.request
import matplotlib.pyplot as plt
plt.style.use('ggplot')
import pandas as pd
# 下载同时显示进度条
def jdt(down, pic, all):
"""
@down : 已经下载的数据块
@pic : 数据块的大小
@all : 远程文件的大小
"""
jd = 100.0 * down * pic / all
if jd > 100:
jd = 100
print('%.2f%%'%jd)
url = 'http://lib.stat.cmu.edu/datasets/CPS_85_Wages'
fil_out = r'D:\Python_data\wages.txt'
urllib.request.urlretrieve(url, fil_out,jdt)
2、数据读取及简单探索
查看下载文件,前27行为无效数据, 后6行也是无效
数据描述如下:
EDUCATION: Number of years of education.
SOUTH: Indicator variable for Southern Region (1=Person lives in
South, 0=Person lives elsewhere).
SEX: Indicator variable for sex (1=Female, 0=Male).
EXPERIENCE: Number of years of work experience.
UNION: Indicator variable for union membership (1=Union member,
0=Not union member).
WAGE: Wage (dollars per hour).
AGE: Age (years).
RACE: Race (1=Other, 2=Hispanic, 3=White).
OCCUPATION: Occupational category (1=Management, 2=Sales, 3=Clerical, 4=Service, 5=Professional, 6=Other).
SECTOR: Sector (0=Other, 1=Manufacturing, 2=Construction).
MARR: Marital Status (0=Unmarried, 1=Married)
name = ['EDUCATION', 'SOUTH', 'SEX', 'EXPERIENCE', 'UNION',
'WAGE', 'AGE', 'RACE', 'OCCUPATION', 'SECTOR', 'MARR']
data_wage = pd.read_table(fil_out, skiprows=27, skipfooter = 6, sep = '\t', header=None )
data_wage.columns = name
# 去掉大部分分类变量看相关
d = ['EDUCATION', 'SEX', 'EXPERIENCE', 'WAGE', 'AGE']
pd.plotting.scatter_matrix(data_wage[d], color='steelblue')
plt.show()
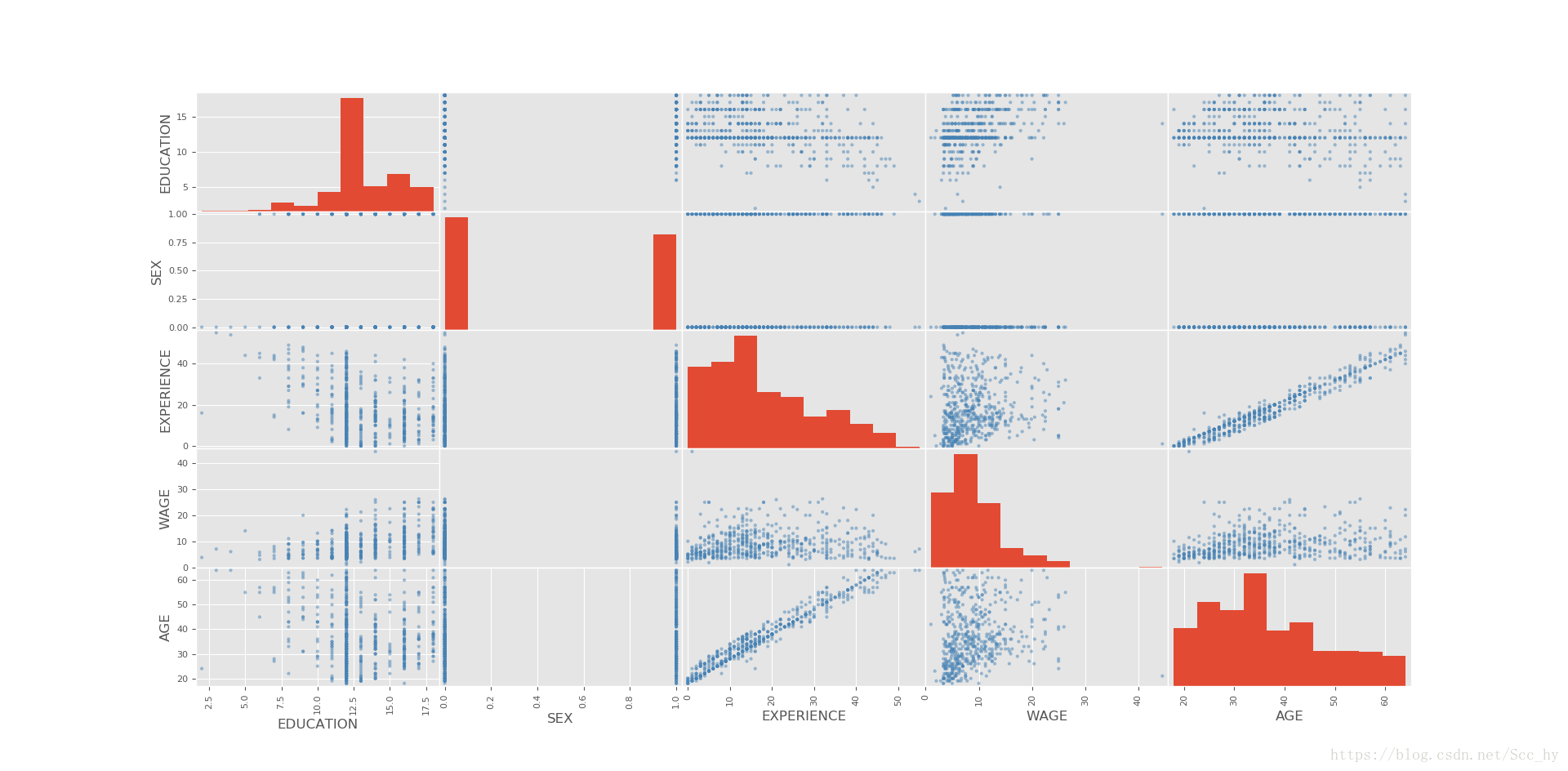
3、绘制交互作用相关性散点
# 绘制回归相关性矩阵+交互作用
import seaborn
seaborn.pairplot(data_wage, vars=['WAGE', 'AGE', 'EDUCATION']
,kind = 'reg', hue = 'SEX', size=5)
plt.show()
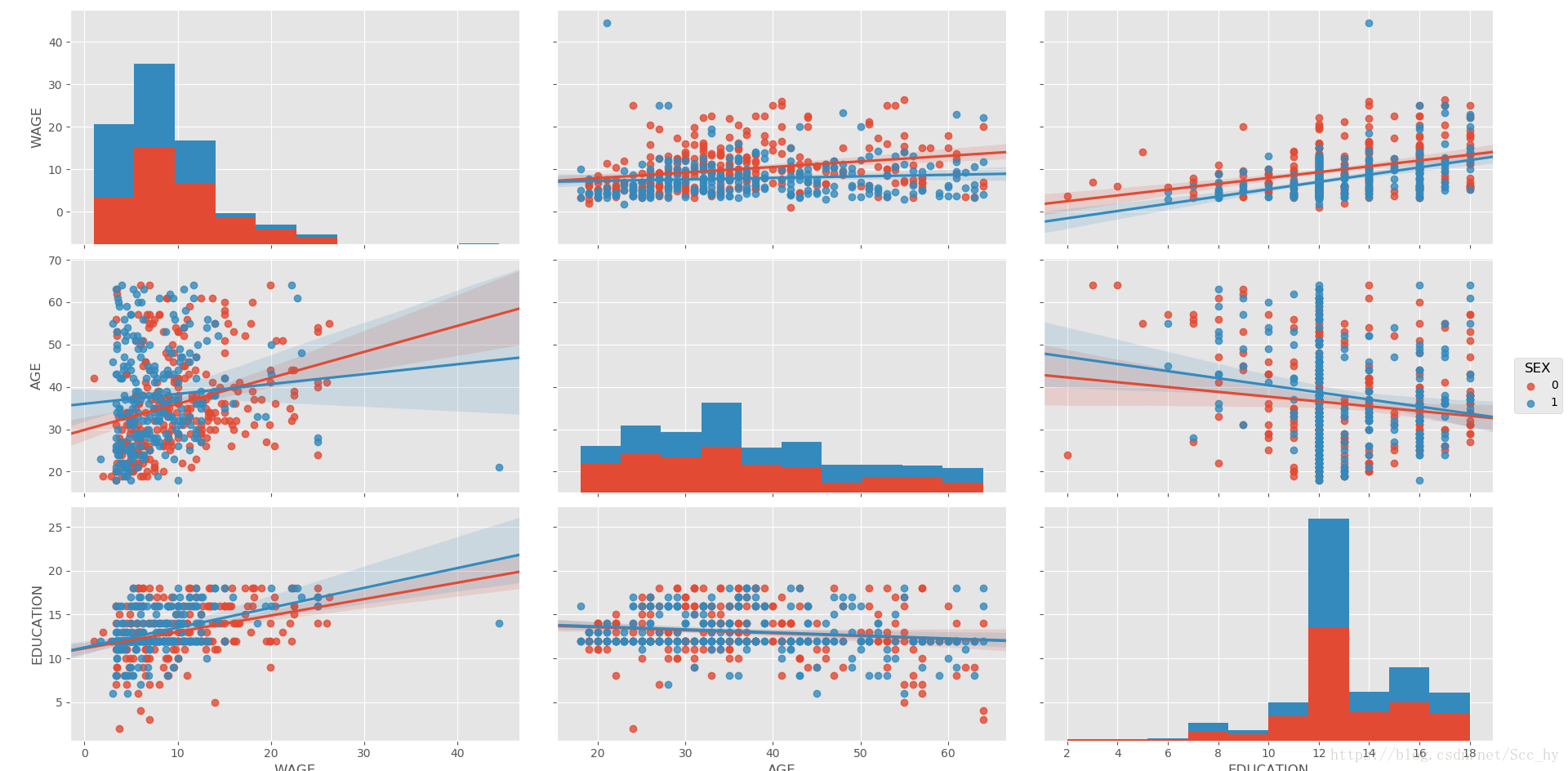
4、建模分析
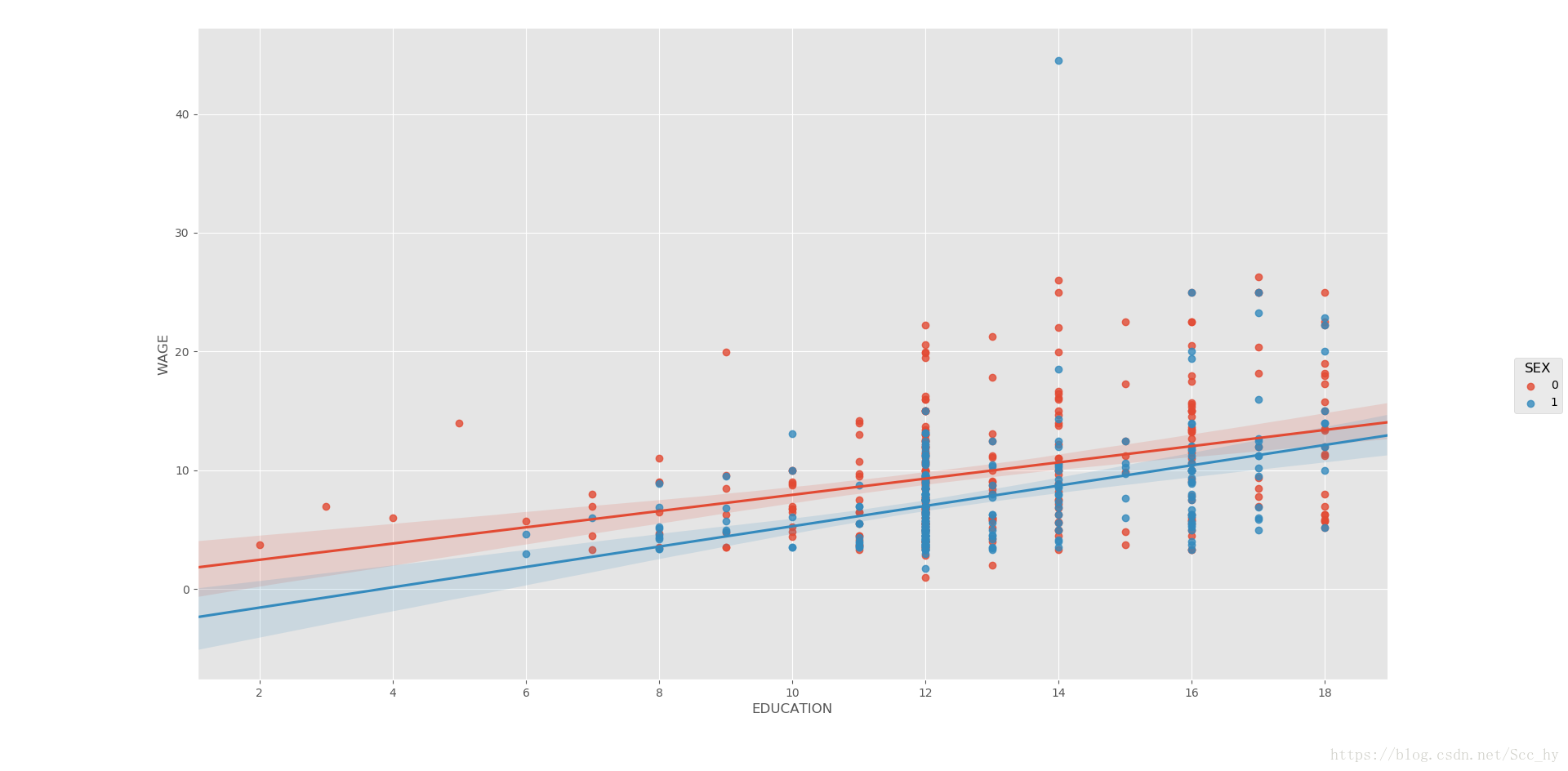
# 单变量回归绘图+交互作用
seaborn.lmplot(y='WAGE', x = 'EDUCATION', hue = 'SEX',data=data_wage)
plt.show()
# 建模
from statsmodels.formula.api import ols
results = ols('WAGE~EDUCATION + C(SEX) + EDUCATION*C(SEX)', data = data_wage).fit()
print(results.summary())
结果如下:
==============================================================================
Dep. Variable: WAGE R-squared: 0.190
Model: OLS Adj. R-squared: 0.186
Method: Least Squares F-statistic: 41.50
Date: Sun, 30 Sep 2018 Prob (F-statistic): 4.24e-24
Time: 18:07:55 Log-Likelihood: -1575.0
No. Observations: 534 AIC: 3158.
Df Residuals: 530 BIC: 3175.
Df Model: 3
Covariance Type: nonrobust
=========================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------------
Intercept 1.1046 1.314 0.841 0.401 -1.476 3.685
C(SEX)[T.1] -4.3704 2.085 -2.096 0.037 -8.466 -0.274
EDUCATION 0.6831 0.099 6.918 0.000 0.489 0.877
EDUCATION:C(SEX)[T.1] 0.1725 0.157 1.098 0.273 -0.136 0.481
==============================================================================
Omnibus: 208.151 Durbin-Watson: 1.863
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1278.081
Skew: 1.587 Prob(JB): 2.94e-278
Kurtosis: 9.883 Cond. No. 170.
==============================================================================
就该数据而言,男性受教育作用要比女性受教育作用大,这可能是女性存在生育期工作空挡和社会对男性偏向造成的


















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











