




 本文围绕梯度下降在线性回归中的应用展开。先进行数据准备,采用随机梯度下降寻找参数,比较了sklearn线性回归和最小二乘法的差距。解释了线性回归可用梯度下降拟合的原因,阐述了梯度下降原理,最后利用sklearn中的SGDRegressor快速进行梯度下降线性回归。
本文围绕梯度下降在线性回归中的应用展开。先进行数据准备,采用随机梯度下降寻找参数,比较了sklearn线性回归和最小二乘法的差距。解释了线性回归可用梯度下降拟合的原因,阐述了梯度下降原理,最后利用sklearn中的SGDRegressor快速进行梯度下降线性回归。
1、数据准备
# 生成随机散点
import numpy as np
x = 2 * np.random.rand(100, 1)
y = 6 + 5 * x + np.random.rand(100,1) # 添加噪声
# 图示
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.scatter(x, y, s=2, c='red',alpha=0.7)
plt.show()
生成散点如下:
2、随机梯度下降寻找参数
# y = wx +b
# 将b值初始定为 w2 * 1, 让其同时迭代
x_b = np.c_[np.ones((10, 1)), x] # 合并列
采用动态学习率,使其逐步减小:
def eta_new(t):
"""
t : 迭代次数
限定最低学习率 0.01
4 和 1为人为定值
"""
return 4/(1 + t) +0.01
随机梯度下降:
n = 1000 # 迭代次数
w = np.random.randn(2,1) # 随机定w的初始值
# 开始随机梯度下降
for time in range(n):
for index in range(1,len(x)): # 浏览全部索引
r_index = np.random.randint(index) # 随机提取
xi = x_b[r_index : r_index+1] # 随机取样本
yi = y[r_index : r_index+1]
eta = eta_new(time + index) # 学习率跟随迭代次数和索引浮动变化,总体趋势为逼近0.01
td = xi.T.dot(xi.dot(w) - yi)
w -= eta * td
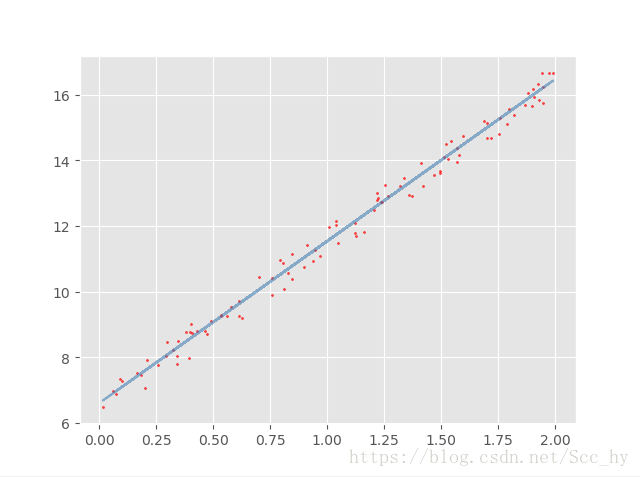
经过一千次随机迭代后,绘图查看迭代效果
# w 参数为 array([[6.60615545],
# [4.93099413]])
plt.scatter(x, y, s=2, c='red',alpha=0.7) # 原数据
plt.plot(x, x_b.dot(w), c = 'steelblue', alpha =0.6) # 迭代后的拟合数据
plt.show()
3、sklearn 线性回归和最小二乘发
# 用最小二乘方法进行计算 w 和 b
w_r = (len(x)*sum(x*y) -sum(x)*sum(y) ) / (len(x)*sum(x*x) - sum(x)**2)
b_r = np.mean(y)- w_r*np.mean(x)
## 结果为 : w_r = 4.91148394 ;b_r = 6.60282153
# sklear线性回归
from sklearn.linear_model import LinearRegression
lr = LinearRegression(fit_intercept=False)
lr.fit(x_b, y)
lr.coef_ # array([[6.60282153, 4.91148394]]) 结果同最小二乘法
比较线性回归和随机梯度下降的差距
y_pre = lr.predict(x_b)
plt.scatter(x, y, s=2, c='red',alpha=0.7)
plt.plot(x, x_b.dot(w), c = 'steelblue', alpha =0.6)
plt.plot(x, y_pre, c = 'green', alpha = 0.6)
plt.show()
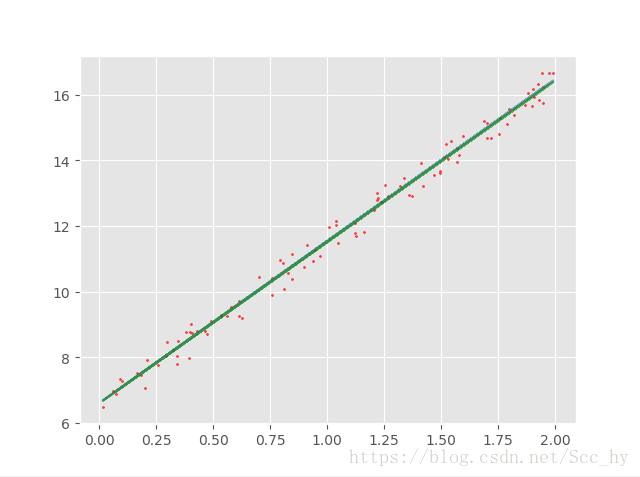
由图可见:SGD 和线性回归的拟合几乎重叠
从参数上来看也几乎相同
SGD —— ·[6.60615545], [4.93099413]
线性回归 —— [6.60282153, 4.91148394]
4、为什么线性回归可以用梯度下降的方法去拟合
首先,从最小二乘法和线性回归所得的参数结果可以知晓,两者是进行同样的算法操作。
由于,最小二乘法是由方差求一阶偏导为零,推导出来的。(推导相对简单,自行百度)
而梯度下降是常见的一阶优化方法(具有一阶连续偏导),目的也是为了使得方差收敛到最小。
方差: [具有一阶连续偏导]
D
=
∑
i
=
1
n
(
y
i
−
x
i
⋅
w
)
2
D = \sum_{i=1}^n{(y_i-x_i\cdot{w})^2}
D=i=1∑n(yi−xi⋅w)2
因此可以用选取适当的初始值
w
0
w_0
w0,不断迭代,更新
w
w
w的值,进行目标函数的极小化,直到收收敛,从而达到减小函数值的目的。
5、梯度下降原理
只要不断执行以下过程即可收敛到局部极小
f
(
x
t
+
1
)
<
f
(
x
t
)
,
t
=
0
,
1
,
2....
f(x^{t+1} )<f(x^t) , t = 0,1,2....
f(xt+1)<f(xt),t=0,1,2....
根据泰勒展开可得(舍掉高阶无穷小项以后——局部线性近似公式)回顾泰勒展开:
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
Δ
x
T
∇
f
(
x
)
f(x+\Delta{x} )\approx{f(x) + \Delta{x}^T \nabla{f(x)}}
f(x+Δx)≈f(x)+ΔxT∇f(x)
要使得
f
(
x
t
+
1
)
=
f
(
x
t
+
Δ
x
)
<
f
(
x
t
)
f(x^{t+1} ) = f(x^t+\Delta{x} )<f(x^t)
f(xt+1)=f(xt+Δx)<f(xt),且最快下降(推倒参考),需要使得
Δ
x
T
=
−
λ
∇
f
(
x
)
\Delta{x}^T = -\lambda \nabla{f(x)}
ΔxT=−λ∇f(x),即 $x^{t+1} -x^t =-\lambda \nabla{f(x)} $,最终得到:
x
t
+
1
=
x
t
−
λ
∇
f
(
x
)
x^{t+1} =x^t -\lambda \nabla{f(x)}
xt+1=xt−λ∇f(x)
由于只关注
x
x
x的值,且在知道其为凸函数的时候,可以直接这样简单快速迭代
方差的梯度函数为:(由于多次迭代,可以忽略常数项,相当于将其算入学习率)
∇
f
(
w
)
=
2
∑
i
=
1
n
x
i
(
y
i
−
x
i
⋅
w
)
\nabla{f(w)}= 2\sum_{i=1}^n{x_i(y_i-x_i\cdot{w})}
∇f(w)=2i=1∑nxi(yi−xi⋅w)
即逐步移动
w
w
w,使
f
(
w
t
)
f(w^t)
f(wt)其达到最小值
参考 李航 《统计学习方法》
参考 周志华 《机器学习》
6、利用sklearn中的SGDRegressor,快速进行梯度下降线性回归
其默认优化的是均方差损失函数
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(N_ilter = 50, # 迭代次数
penalty = None, # 正则项为空
eta0 = 0.1 # 学习率
)
sgd_reg.fit(x,y)
sgd_reg.intercept_ , sgd_reg.coef_
## 结果 6.59849714, 4.90377178
其结果同 线性回归基本相同,增加迭代次数还可以优化


















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











