







 本文探讨了使用Arctan作为逻辑回归中的激活函数的可能性,并通过对比实验验证了其相较于传统Sigmoid函数的优势,特别是在大数据场景下的更快收敛速度。
本文探讨了使用Arctan作为逻辑回归中的激活函数的可能性,并通过对比实验验证了其相较于传统Sigmoid函数的优势,特别是在大数据场景下的更快收敛速度。
一、主要内容
最近看到两篇文章,写用arctan 来优化relu激活函数的文章。
《基于Arc-LSTM的人职匹配研究》
《基于ArcReLU函数的神经网络激活函数优化研究》
就想着其实可以将逻辑回归的sigmoid函数换成标准化后的arctan函数,同样可以进行二阶求导,梯度下降。
二、主要思路
详细的简单脚本可以参考笔者的 github:Arctan_logistic
逻辑回归简单讲就是单层全连接层,所以激活函数可以进行替换
def activation(linear_x, method='sigmoid'):
"""
激活函数, sigmoid / arctan
"""
if method == 'sigmoid':
out = np.zeros_like(linear_x, dtype=np.float64)
biger_bool = np.abs(linear_x) >= 100
out[biger_bool] = 1 / ( 1 + np.exp(-100 * np.sign(linear_x[biger_bool])) )
out[~biger_bool] = 1 / ( 1 + np.exp(- linear_x[~biger_bool]))
return out
if method == 'arctan': # (arctan / np.pi * 2 + 1)/2 归一化
return np.arctan(linear_x) / np.pi + 1/2
def activation_derivative(nd, method='sigmoid'):
"""
激活函数求导
"""
if method == 'sigmoid': # sigmoid_out
return nd - nd * nd
if method == 'arctan': # linear_x
return 1 / (1 + nd * nd) / np.pi
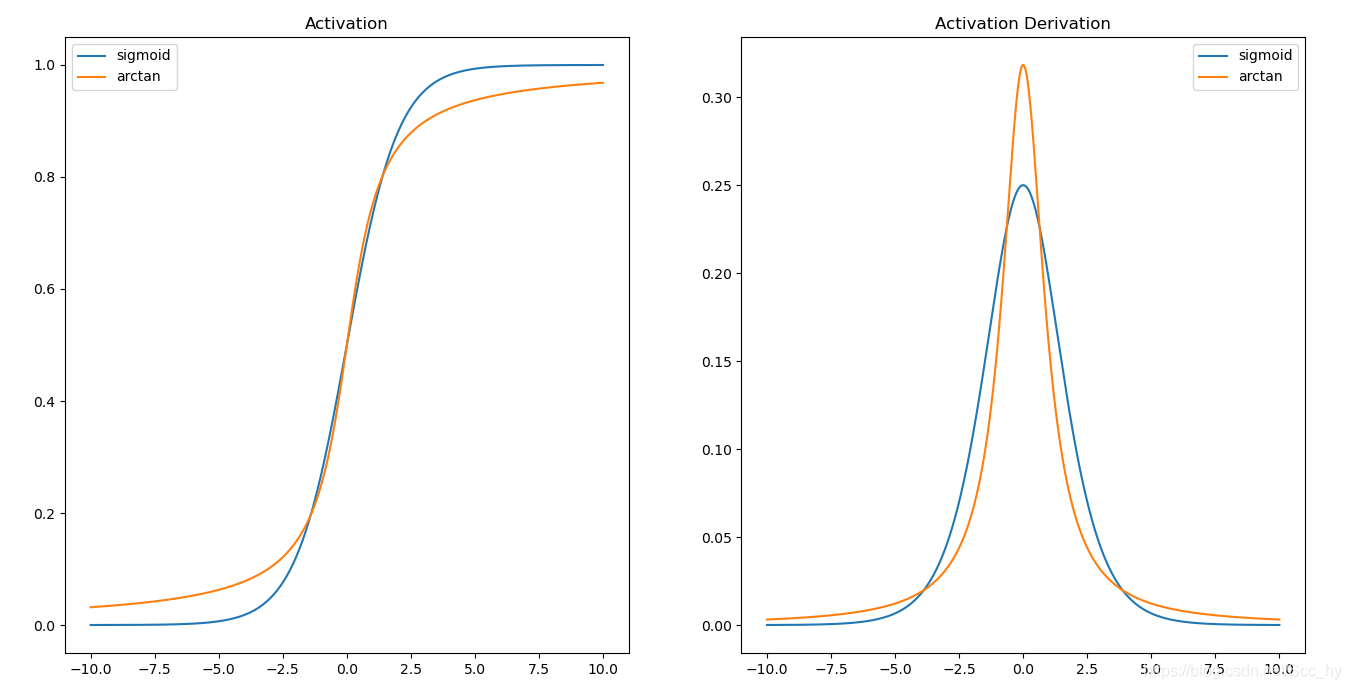
import matplotlib.pyplot as plt
draw_x = np.linspace(-10, 10, 1000)
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
axes[0].plot(draw_x, activation(draw_x, method='sigmoid'), label='sigmoid')
axes[0].plot(draw_x, activation(draw_x, method='arctan'), label='arctan')
axes[0].set_title('Activation')
axes[0].legend()
axes[1].plot(draw_x, activation_derivative(activation(draw_x, method='sigmoid'), method='sigmoid'), label='sigmoid')
axes[1].plot(draw_x, activation_derivative(draw_x, method='arctan'), label='arctan')
axes[1].set_title('Activation Derivation')
axes[1].legend()
plt.show()
从图中可以看出,arctan的梯度下降会更加迅速, 同时比sigmoid更不容易趋于0。
链式求导迭代
def epoch_train(x, y, w, lr, method='sigmoid', batch_size=128, epoch_num=0, verbose=0):
"""
训练一次数据
"""
loop = True
data_g = data_generator(x, y, batch_size=batch_size)
loss_list = []
while loop:
try:
xt, yt = next(data_g)
except StopIteration:
loop = False
linear_x = xt.dot(w) # (m, n).dot((n, 1)) -> (m, 1)
pred_y = activation(linear_x, method=method)
loss_d = loss_derivative(yt, pred_y)
if method == 'sigmoid':
w_d = xt.T.dot(activation_derivative(pred_y, method='sigmoid') * loss_d) / batch_size
if method == 'arctan':
# (m, n).T.dot((m, 1)) -> (n, 1)
w_d = xt.T.dot(activation_derivative(linear_x, method='arctan') * loss_d) / batch_size
w -= lr * w_d
# print('w_d:', w_d)
loss_list.append(binary_loss(yt, activation(xt.dot(w))))
if verbose:
print('w:\n', w)
print(f'Epoch [{epoch_num}] loss: {np.mean(loss_list):.5f}')
print('--'*25)
return w
三、结论
3.1 结论
在大数据场景下,对数据分布不进行过多的假设,采用arctan 替换sigmoid 函数逻辑回归收敛所需迭代的次数会更少。
**************************************************
--------------------------------------------------
t_epoches-10 test_time: 0
LogisticRegression acc: 81.579%
my-sigmoid-lr acc: 81.579%
my-arctan-lr acc: 86.842%
--------------------------------------------------
t_epoches-10 test_time: 1
LogisticRegression acc: 89.474%
my-sigmoid-lr acc: 73.684%
my-arctan-lr acc: 76.316%
--------------------------------------------------
t_epoches-10 test_time: 2
LogisticRegression acc: 84.211%
my-sigmoid-lr acc: 84.211%
my-arctan-lr acc: 86.842%
**************************************************
--------------------------------------------------
t_epoches-40 test_time: 0
LogisticRegression acc: 86.842%
my-sigmoid-lr acc: 89.474%
my-arctan-lr acc: 81.579%
--------------------------------------------------
t_epoches-40 test_time: 1
LogisticRegression acc: 84.211%
my-sigmoid-lr acc: 84.211%
my-arctan-lr acc: 84.211%
--------------------------------------------------
t_epoches-40 test_time: 2
LogisticRegression acc: 81.579%
my-sigmoid-lr acc: 78.947%
my-arctan-lr acc: 81.579%



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











