





Abstract
生成模型的最新进展突出了图像标记化(image tokenization )在高效合成高分辨率图像中的关键作用。与直接处理像素相比,标记化将图像转换为潜在表示(latent representations),减少了计算需求,提高了生成过程的有效性和效率。先前的方法,如VQGAN,通常使用具有固定下采样因子的二维潜在网格(2D latent grids)。然而,这些二维标记化在管理图像中存在的固有冗余(inherent redundancies)方面面临挑战,其中相邻区域经常显示相似性。为了克服这个问题,我们引入了基于变换的Transformer-based 1-Dimensional Tokenizer (TiTok),这是一种将图像标记为一维潜在序列的创新方法。TiTok提供了更紧凑的潜在表示,产生比传统技术更高效和有效的表示。例如,一张256张的图像可以减少到32个离散的discrete tokens,与之前的方法获得的256或1024个标记相比,这是一个显著的减少。尽管它的性质紧凑,但TiTok以最先进的方法实现了竞争性能。具体来说,使用相同的生成器框架,TiTok获得了1.97 gFID,在ImageNet 256 X256基准测试中显著优于MaskGIT基线4.21。当涉及到更高的分辨率时,TiTok的优势变得更加明显。在ImageNet 512X 512基准测试中,TiTok不仅优于最先进的扩散融合模型DiT-XL/2 (gFID 2.74 vs. 3.04),而且还减少了64个图像令牌,从而使生成过程更快。我们表现最好的变体可以显著超过DiT-XL/2 (gFID 2.13 vs. 3.04),同时仍能以 74× 的速度生成高质量的样本。
Introduction
近年来,由于Transformer[19,62,66,10,67,68]和Diffusion Model[16,55,29,49,21]的重大进步,图像生成取得了显著进展。与生成语言模型的趋势相呼应[48,59],许多当代图像生成模型的架构都包含一个标准的图像tokenizer和de-tokenizer。该模型阵列利用标记化的图像表示(范围从连续的[34]到离散向量[54,61,19])来执行一个关键功能:将原始像素转换为潜在空间。潜在空间(例如,32 × 32)明显比原始图像空间(256 × 256 × 3)更紧凑。它提供了压缩但富有表现力的表示,因此不仅有利于生成模型的有效训练和推理,而且为扩大模型大小铺平了道路。
is 2D structure necessary for image tokenization?
In this work, we introduce a transformer-based framework [62, 17] designed to tokenize an image to a 1D discrete sequence, which can later be decoded back to the image space via a de-tokenizer.
具体来说,我们提出了基于变压器的一维标记器(TiTok),它由视觉变压器(ViT)编码器、ViT解码器和矢量量化器组成,遵循典型的矢量量化(VQ)模型设计[19]。在标记化阶段,图像被分割并平面化成一系列补丁,然后与1D序列的潜在标记进行连接。经过ViT编码器的特征编码过程后,这些隐标记构建图像的隐表示。在矢量量化步骤[61,19]之后,利用ViT解码器从被掩码令牌序列中重构输入图像[15,24]。
在TiTok的基础上,我们进行了广泛的实验来探索一维图像标记化的动态。我们的调查研究了潜在空间大小、模型大小、重建保真度和生成质量之间的相互作用。从这一探索中,出现了几个令人信服的见解:
1. 增加表示图像的潜在令牌的数量可以持续提高重建性能,但在128个令牌之后,好处就变得微不足道了。有趣的是,对于一个合理的图像重建,32个标记就足够了。
2. 扩大标记器模型的大小显着提高了重建和生成的性能,特别是当标记数量有限(例如,32或64)时,展示了在潜在空间实现紧凑图像表示的有希望的途径。
3. 一维标记化打破了以往二维图像标记器的网格约束,不仅使每个潜在标记能够重构固定图像网格以外的区域,从而使标记器设计更加灵活,而且还可以学习到更高级、语义更丰富的图像信息,特别是在紧凑的潜在空间中。
4. 1D标记化在生成训练中表现出优异的性能,与典型的2D标记器相比,它不仅在训练和推理方面都有显着的加速,而且在使用更少的标记时也具有竞争力的FID分数。

Related Work
参考视频如何搭建VQ-VAE模型(Pytorch代码)转自:刹那-Ksana-_哔哩哔哩_bilibili
Image Tokenization
autoencoders [27, 63], the design of using an encoder that compresses high-dimensional images into a low-dimensional latent representation and then using a decoder to reverse the process,
has proven to be successful over the years.
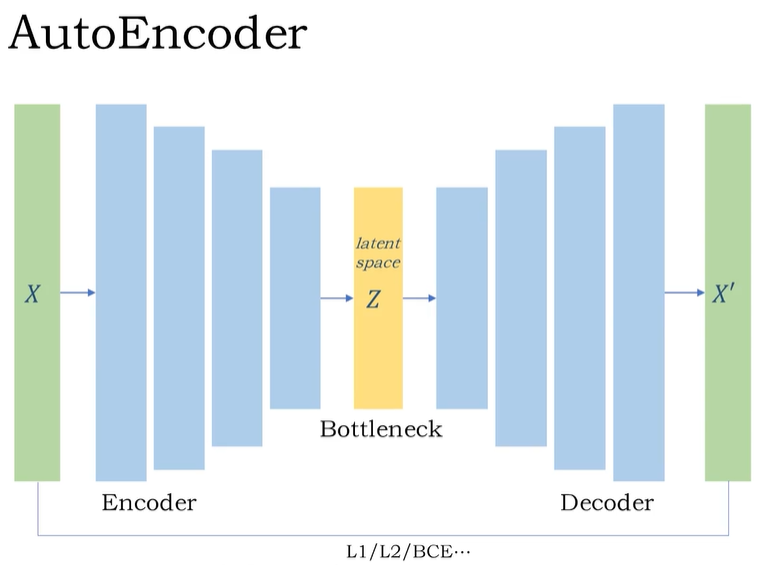
Variational Autoencoders (VAEs) [34] extend the paradigm by learning to map the input to a distribution.
VAE以前写过 生成模型速通(Diffusion,VAE,GAN)_gan vae diffusion-优快云博客
Instead of modeling a continuous distribution, VQVAEs(Vector Quantized Variational Autoencoder) [47, 53] learn a discrete representation forming a categorical distribution. VQGAN [19] further improves the training process by using adversarial training [23]. The transformer design of the autoencoder is further explored in ViT-VQGAN [65] and Efficient-VQGAN [7].
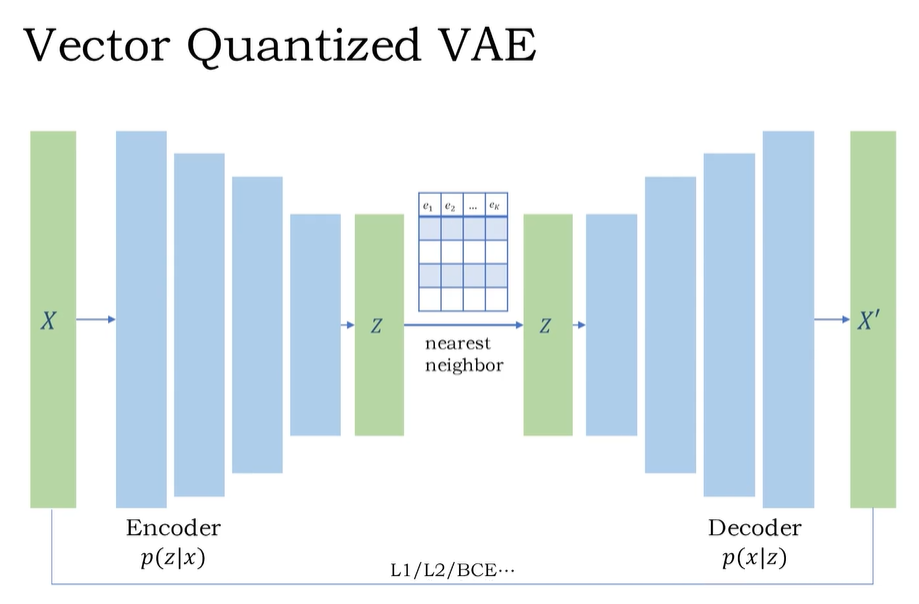
VAE vs VQ-VAE
| 特点 | VAE | VQ-VAE |
|---|---|---|
| 潜在空间类型 | 连续的概率分布 | 离散向量集合(codebook) |
| 是否使用KL散度正则化 | 是 | 否 |
| 潜在向量是否可直接采样 | 可以(用高斯) | 不行(需要查表codebook) |
| 输出质量 | 有时模糊 | 更清晰、锐利 |
Orthogonal to this, RQ-VAE [36] and MoVQ [76] study the effect of using multiple vector quantization steps per latent embedding, while MAGVIT-v2 [68] and FSQ [45] propose a lookup-free quantization.
RQ-VAE: Towards Training Vector Quantized AutoEncoders for Large Vocabulary Size
核心思想:引入 残差量化(Residual Quantization) 技术,让编码过程更高效。
RQ-VAE 不只用一个 codebook,而是用多个 codebook 分层逐步逼近编码向量。也就是说,每一层 codebook 学习残差(残差 = 当前编码 - 上一层重构结果),分层逼近真实表示。
MoVQ:Mixture of VQ: Towards Generalized Discrete Representation Learning
核心思想:使用多个 codebook,但每个输入编码只“激活”其中一个或几个 codebook(像 mixture of experts)。每个输入不是统一用一个 codebook,而是通过 gating mechanism(门控机制) 选择最合适的一个或多个 codebooks。这种方式让不同数据可以用不同的子词典表示,增强表达多样性。
MAGVIT v2: Scaling Masked Generative Video Transformers with Multi-Resolution Token Learning
核心思想:它其实是一个基于 VQ-VAE + Transformer 的视频生成系统,强调对时空信息的建模和多分辨率 token 学习。
亮点:
-
使用改进的 VQ-VAE 提取多尺度离散 token 表示
-
用 Transformer 对视频 token 序列进行建模
-
多分辨率 token(既包含 coarse 也包含 fine 信息)
FSQ:Fully Scalar Quantization for Discrete Representation Learning
核心思想:用纯标量量化(不使用向量/embedding,而是每维单独量化)来代替传统 VQ-VAE 的 vector quantization。传统 VQ 是把整个向量看成一个整体做最近邻查找,而 FSQ 把每一维的值做独立量化(比如每维有 N 个桶/分段),最后组合成一个 token
However, all aforementioned works share the same workflow of an image always being patchwise encoded into a 2D grid latent representation. In this work, we explore an innovative 1D sequence latent representation for image reconstruction and generation.
Tokenization for Image Understanding
For image understanding tasks (e.g., image classifica-tion [17], object detection [8, 77, 74], segmentation [64, 70, 72], and Multi-modal Large Language Models (MLLMs) [1, 40, 73]), it is common to use a general feature encoder instead of an autoencoder to tokenize the image.
Specifically, many MLLMs [40, 42, 58, 32, 22, 11] uses a CLIP [51] encoder to tokenize the image into highly semantic tokens, which proves effective for image captioning [13] and VQA [2]. Some MLLMs also explore discrete tokens [32, 22] or “de-tokenize” the CLIP embeddings back to images through diffusion models [58, 32, 22].
However, due to the nature of CLIP models that focus on high-level information, these methods can only reconstruct an image with high-level semantic similarities (i.e., the layouts and details are not well-reconstructed due to CLIP features). Therefore, our method is significantly different from theirs, since the proposed TiTok aims to reconstruct both the high-level and low-level details of an image, same as typical VQ-VAE tokenizers [34, 54, 19].
Image Generation
Image generation methods range from sampling the VAE [34], using GANs [23] to Diffusion Models [16, 55, 29, 49, 21] and autoregressive models [60, 12, 47]. Prior studies that are most related to this work build on top of a learned VQ-VAE codebook to generate images. Autoregressive transformer [19, 65, 7, 36], similar to decoder-only language models, model each patch in a step-by-step fashion, thus requiring as many steps as token number, e.g., 256 or 1024.
Non-autoregressive (or bidirectional) transformers [76, 68], such as MaskGIT [9], generally predict more than a single token per step and thus require significantly fewer steps to predict a complete image. Apart from that, further studies looked into improved sampling strategies [38, 39, 37].
As we focus on the tokenization stage, we apply the commonly used non-autoregressive sampling scheme of MaskGIT to generate a sequence of tokens that is later decoded into an image.
Method
Preliminary Background on VQ-VAE
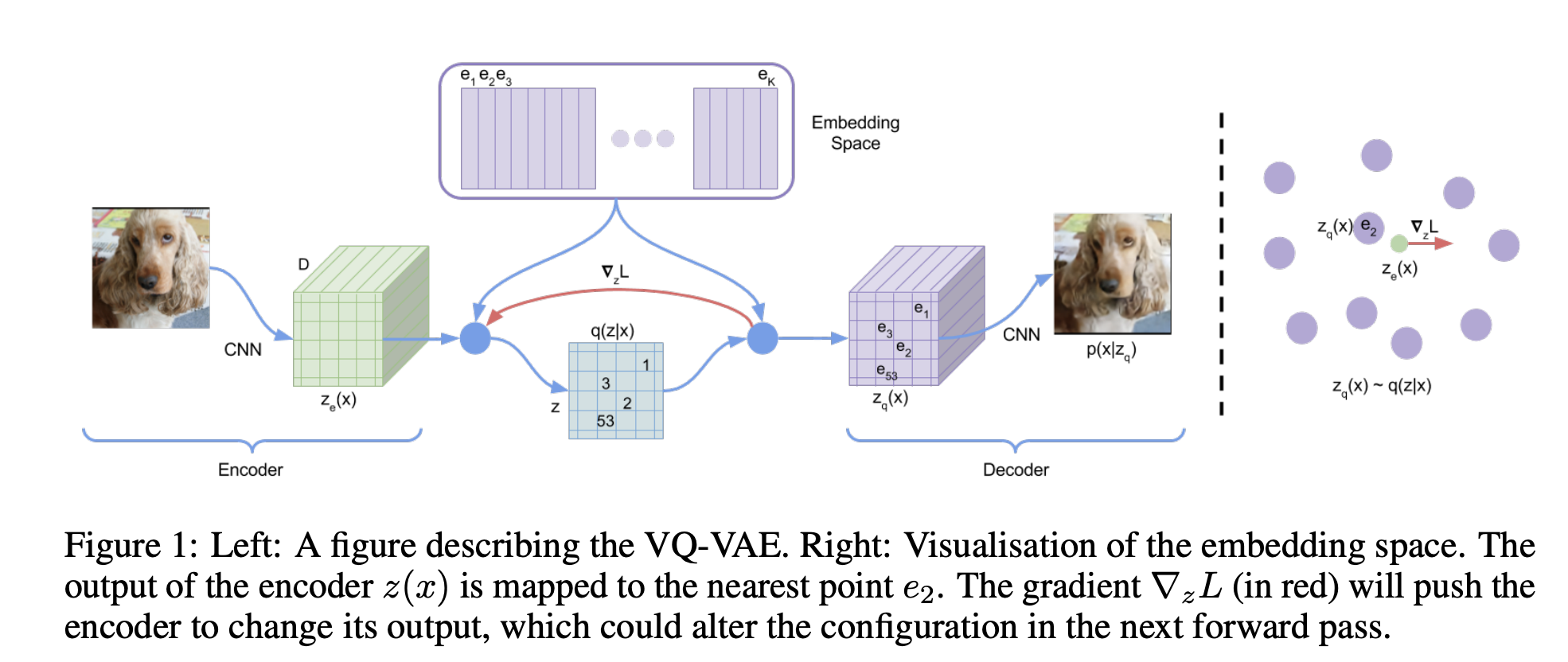
在我们的讨论范围内,我们主要关注矢量量化(Vector-Quantized, VQ)tokenizer[61,19],因为它在各个领域的广泛适用性,包括但不限于图像和视频生成[19,9,55,67],大规模预训练[12,5,46,3,18]和多模态模型[20,69]。
A typical VQ model contains three key components:
an encoder Enc, a vector quantizer Quant, and a decoder Dec.
Step1
Given an input image I ∈ R H×W×3
the image is initially processed by the encoder Enc and converted to latent embeddings,which downsamples the spatial dimensions by a factor of f
![]()
Subsequently, each embedding z ∈ RD is mapped (via the vector quantizer Quant) to the nearest code ci ∈ RD, in a learnable codebook C ∈ RN×D, comprising N codes.
********************************************
D 表示 latent embedding 的通道维度(feature dimension),即每个 token 的表示维度。
假设:
-
输入图像大小为 256×256
-
下采样因子 f=4,那么 latent map 是 64×64
-
假设 D = 32,那么:
-
每个位置有一个 32 维的向量,整个 latent 表达是 64×64×32
-
这就是输入到 vector quantizer 的内容,quantizer 会查找最接近的 codebook 中的向量 ci∈R32
-
********************************************
Step2
Formally, we have:
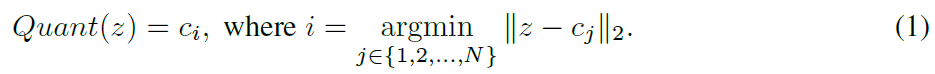
这一步就是 VQ 中的“最近邻查找”步骤,用一句话说就是:
把 encoder 输出的向量 z 映射到 codebook C={c1,c2,...,cN}中距离它最近的那个 code ci
理解:
-
有个学到的“词典”(codebook),每一页上有一个向量(一个 code)。
-
Encoder 输出了一个 patch 的特征向量 z
-
然后你去词典里找:哪个 code 跟 z 最像?(L2 距离最小)
-
找到了,比如是第 17 页的向量 c17,那就:
Quant(z)=c17
Step3
During de-tokenization, the reconstructed imageˆI is obtained via the decoder Dec as follows:

Despite the numerous improvements over VQ-VAE [61] (e.g., loss function [19], model architec-ture [65], and quantization/codebook strategies [76, 36, 68]), the fundamental workflow (e.g., the 2D grid-based latent representations) has largely remained unchanged.
********************************************
vq-embedding 和 unet的区别:
| 模块 | VQ Tokenizer | U-Net |
|---|---|---|
| Encoder | 下采样图像,提取 patch-level 表示 | 下采样图像,提取语义特征 |
| Decoder | 重建图像 | 生成 mask / segmentation / enhanced image |
| 中间表示 | latent embedding(Z2D) | bottleneck feature map(通常也是多通道的特征) |
| 方面 | VQ Tokenizer 的 latent embedding | U-Net 中间特征(latent-like) |
|---|---|---|
| 表示的东西 | 被量化为离散 token 的紧凑表征(每个位置代表一个 code) | 原始特征图,连续值,用于后续任务(如分割) |
| 是否量化(discretized) | ✅ 会用 codebook 离散化 | ❌ 全程都是连续表示 |
| 是否可用于 token 化 | ✅ 是 token,本质是“图像的离散 patch 表示” | ❌ 不是 token,没法直接作为离散输入用于 LLM |
| 适用场景 | 生成模型(VQGAN、DALL·E 等),token-based模型输入 | 分割、重建、回归等任务 |
| 训练目标 | 压缩图像并可解码重构 | 完成特定任务(比如分割、超分辨等) |
U-Net 的 latent 是“连续的特征图”,而 VQ 的 latent 是“准离散的 token 表示”,两者虽然结构相似,但目标和处理方式完全不同。
VAE vs VQ-VAE

VAE:把图像编码成“一个浮点向量”,就像你描述一个人长相时说“脸有点圆、鼻子微高、眼睛大小适中”
VQ-VAE: 把图像编码成“一个离散编号组合”,就像你说“他长得像小李子和周杰伦的结合”——用的是固定模板组合(codebook)
********************************************
TiTok: From 2D to 1D Tokenization
a notable limitation of VQ models within the standard workflow exists: the latent representation Z2D is often envisioned as a static 2D grid.
Such a configuration inherently assumes a strict one-to-one mapping between the latent grids and the original image patches.
This assumption
1. limits the VQ model’s ability to fully exploit the redundancies(过多的) present in images, such as similarities among adjacent patches.
2. constrains the flexibility in selecting the latent size, with the most prevalent configurations being f = 4, f = 8, or f = 16 [55], resulting in 4096, 1024, or 256 tokens for an image of dimensions 256 × 256 × 3.
Inspired by the success of 1D sequence representations in addressing a broad spectrum of computer vision problems [8, 1, 40], we propose to use a 1D sequence, without the fixed correspondence between latent representation and image patches in 2D tokenization, as an efficient and effective latent representation for image reconstruction and generation.
| 表达方式 | 形状 | 对应方式 | 示例 |
|---|---|---|---|
| 2D latent (传统 VQ) | H/f×W/f×D | 每个 latent 对应固定 patch | 32×32 grid (1024 token) |
| 1D latent (新方法) | L×D | 每个 latent 不一定对应固定 patch | L=256 或 L=128,视图像复杂度定 |
为什么更好?
-
压缩更高效:可以压成更少的 token,还保持表达能力。
-
打破 patch 限制:类似 transformer 中 learned token,不固定在 patch。
-
更灵活适配 transformer:尤其是像 LLAMA、GPT、ViT 等模型处理的都是 1D 序列,latent 也变成 1D,更容易对接。
确实更适合transformer呢
Image Reconstruction with TiTok
We establish a novel frame-work named Transformer-based 1-Dimensional Tokenizer (TiTok), leveraging(利用) Vision Transformer (ViT) [17] to tokenize images into 1D latent tokens and subsequently reconstruct the original images from these 1D latents.
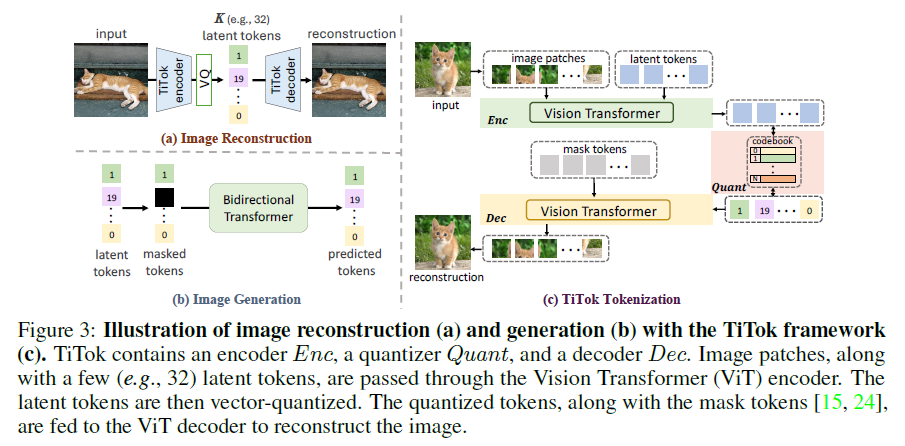
As depicted in Fig. 3, TiTok employs a standard ViT for both the tokenization and de-tokenization processes (i.e., both the encoder Enc and decoder Dec are ViTs). During tokenization, we patchify the image into patches (with a patch embedding layer) ![]() (with patch size equal to the downsampling factor f and embedding dimension D) and concatenate
(with patch size equal to the downsampling factor f and embedding dimension D) and concatenate
them with K latent tokens![]()
They are then fed into the ViT encoder Enc. In the encoder output, we only retain the latent tokens as the image’s latent representation, thereby enabling a more compact latent representation of 1D sequence Z1D (with length K). This adjustment decouples the latent size from image’s resolution and allows more flexibility in design choices. That is, we have:
![]()
where ⊕ denotes concatenation, and we only retain the latent tokens from the encoder output.
(拼接的时候P:从 [H/f, W/f, D] → [H/f × W/f, D],也就是 [N, D],
concat L:将 latent token L ∈ ℝ^{K × D} 和 P ∈ ℝ^{N × D} 拼接成 [N+K, D];)
In the de-tokenization phase, drawing inspiration from [15, 5, 24], we incorporate a sequence of mask tokens ![]() obtained by replicating a single mask token
obtained by replicating a single mask token ![]() times to the quantized latent tokens Z1D
times to the quantized latent tokens Z1D
The image is then reconstructed via the ViT decoder Dec as follows:
![]()
where the latent tokens Z1D is first vector-quantized by Quant and then concatenated with the mask tokens M before feeding to the decoder Dec.
Despite its simplicity, we emphasize that the concept of compact 1D image tokenization remains underexplored in existing literature. The proposed TiTok thus serves as a foundational platform for exploring the potentials of 1D tokenization and de-tokenization for natural images. It is worth noting that although one may flatten 2D grid latents into a 1D sequence, it significantly differs from the proposed 1D tokenizer, due to the fact that the implicit 2D grid mapping constraints still persist.
********************************************
mask tokens
在 图像重建(de-tokenization) 阶段,原始图像已经不再可见,只剩下压缩后的 latent 表达(记作 Z1D)。但重建图像需要与原图大小一致的 token 序列输入,所以:-
-
他们 使用一个“mask token”向量的复制版本 来填补原始图像中对应 patch 的位置(即输入中除了 latent token 以外的那部分 token 用 mask 填补);
-
这些 mask tokens 的作用就是**“告诉 decoder:这里是空白,请你根据已有的 latent token 来还原图像内容。”**
Quant()
Quant 是 vector quantization 模块,作用是将连续的 latent 向量 Z1D 映射到一个 离散的 codebook 中的索引或向量。

| 方法 | Quantization | 目的 |
|---|---|---|
| VQ-VAE | encoder 输出 → quant → decoder | 训练一个离散 latent 空间 |
| MaskGIT | 输入 token 是离散 code | 用 transformer 预测 masked token |
| TiTok | encoder latent → quant → decoder | 让 decoder 更像“语义重建”,而不是 pixel-wise 的 |
我突然感觉这个框架也能用到多模态
Image Generation with TiTok
Besides the image reconstruction task which the tokenizer is trained for, we also evaluate its effectiveness for image generation, following the typical pipeline [19, 9].
Specifically, we adopt MaskGIT [9] as our generation framework due to its simplicity and effectiveness, allowing us to train a MaskGIT model by simply replacing its VQGAN tokenizer with our TiTok. We do not make any other specific modifications to MaskGIT, but for completeness, we briefly describe its whole generation process with TiTok.
The image is pre-tokenized into 1D discrete tokens. At each training step, a random ratio of the latent tokens are replaced with mask tokens.
Then, a bidirectional transformer takes the masked token sequence as input, and predicts the corresponding discrete token ID of those masked tokens.
The inference process consists of multiple sampling steps, where at each step the transformer’s prediction for masked tokens will be sampled based on the prediction confidence, which are then used to update the masked images.
In this way, the image is “progressively generated” from a sequence full of mask tokens to an image with generated tokens, which can later be de-tokenized back into pixel spaces. The MaskGIT framework shows a significant speed-up in the generation process compared to auto-regressive models. We refer readers to [9] for more details.
| Image Generation | Image Reconstruction |
|---|---|
| 从 随机噪声或语义提示 生成图像 | 从 已有信息/latent 表达 恢复原图 |
| 本质是“创造新图像” | 本质是“还原已有图像” |
| 没有 ground truth | 有 ground truth(原图) |
Two-Stage Training of TiTok with Proxy Codes
Existing Training Strategies for VQ Models
虽然 VQ 模型的结构很简单,但训练起来却很敏感,主要体现在:
-
损失函数复杂:比如 VQGAN 引入了感知损失(perceptual loss)和对抗损失(adversarial loss)来提升生成质量;
-
调参难:训练这些模型往往依赖很多超参数、初始化策略、优化技巧;
-
缺少公开代码:比如 MaskGIT 的很多训练细节并没有公开代码复现,导致难以模仿其训练过程;
-
新任务挑战更大:TiTok 试图实现一个“1D token 的图像重建”,而这在以往文献中很少被研究,因此更难找到现成经验可用。
-
传统训练(比如 VQGAN)要直接预测 RGB 像素;
-
需要使用多种复杂的 loss,例如对抗损失;
-
整体训练不稳定,代价高。
Two-Stage Training Comes to the Rescue
Although training TiTok with the typical Taming-VQGAN [19] setting is feasible, we introduce a two-stage training paradigm for an improved performance. The two-stage training strategy contains “warm-up” and “decoder fine-tuning” stages.
Stage1 - warm-up
用 proxy codes 替代原始图像进行训练,让 1D tokenization 学得更稳定
In the “warm-up” stage, instead of directly regressing the RGB values and employing a variety of loss functions (as in existing methods), we propose to train 1D VQ models with the discrete codes generated by an off-the-shelf MaskGIT-VQGAN model, which we refer to as proxy codes. This approach allows us to bypass(绕过) the intricate loss functions and GAN architectures, thereby concentrating our efforts on optimizing the 1D tokenization settings. Importantly, this modification does not harm the functionality of the tokenizer and quantizer within TiTok, which can still fully function for image tokeniztion and de-tokenization; the main adaptation simply involves the processing of TiTok’s de-tokenizer output. Specifically, this output, comprising a set of proxy codes, is subsequently fed into the same off-the-shelf(已经训练好的) VQGAN decoder to generate the final RGB outputs. It is noteworthy that the introduction of proxy codes differs from a simple distillation [26]. As verified in our experiments, TiTok yields significantly better generation performance than MaskGIT-VQGAN.
❌ 不直接生成 RGB 图像
✅ 用现成 VQGAN(如 MaskGIT)生成的 离散编码(proxy codes) 来训练 TiTok
-
拿一个 已经训练好的 VQGAN(如 MaskGIT);
-
输入图像 → 它输出一堆离散 codes(proxy codes);
-
我们让 TiTok 的编码器+解码器来拟合这些 proxy codes;
-
最终,这些 proxy codes 会丢给 VQGAN 原始的 decoder 输出 RGB 图像。
Stage2 - decoder fine-tuning
After the first training stage with proxy codes, we optionally have the second “decoder fine-tuning” stage, inspired by [10, 50], to improve the reconstruction quality. Specifically, we keep the encoder and quantizer frozen, and only train the decoder towards pixel space with the typical VQGAN training recipe [19].
-
Encoder + Quantizer:不再动;
-
Decoder:接 proxy code → 输出图像 → 用真实图像做 supervision;
-
损失函数使用标准的 VQGAN 训练方式(L2 + perceptual + GAN loss 等)。
目的:
-
进一步提升图像重建质量;
-
用 pixel space 的 supervision 进行 fine-tune;
-
相当于“精炼”阶段。
【阶段一】Warm-Up with Proxy Codes:
原图 → 预训练 MaskGIT-VQGAN → proxy codes
↓
TiTok Encoder + Quantizer + Decoder
↓
拟合 proxy codes (非像素)
输出 proxy codes → 用 MaskGIT-VQGAN decoder → 还原图像
【阶段二】Decoder Fine-Tuning(可选):
只训练 decoder,目标直接重建 RGB 图像
encoder + quantizer 参数不变
我感觉encoder可以换成clip等多模态模型
Experimental Results
Preliminary Experiments of 1D Tokenization

















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









